Stack Overflow недавно опубликовал свой опрос разработчиков за 2022 год, и среди профессиональных разработчиков SQL опередил Python как 3-й наиболее широко используемый язык программирования. Хотя некоторые утверждают, что SQL считается правильным языком программирования (это Тьюринг-полный, так что…), трудно отрицать повсеместное распространение и полезность SQL в мире данных.
Однако когда дело доходит до искусственного интеллекта и машинного обучения, SQL по-прежнему является гражданином второго сорта, даже по сравнению с R или Javascript. К сожалению, инженеры и аналитики, разбирающиеся в SQL, обычно очень хорошо знают данные и предметную область, что крайне важно для успешного машинного обучения в производственной среде.
С другой стороны, развертывание модели в потоке — это в значительной степени неизученный механизм развертывания, который имеет ряд важных для бизнеса приложений, таких как обнаружение аномалий и профилактическое обслуживание.
Средство, позволяющее аналитикам SQL создавать системы потокового машинного обучения, может принести значительную пользу многим организациям во многих отраслях. К сожалению, потоковое вещание, машинное обучение и SQL редко используются в одном предложении!
Сегодня мы собираемся изменить это и посмотреть, как вы можете использовать возможности машинного обучения с низким кодом в Databricks AutoML и Delta Live Tables для выполнения выводов машинного обучения на основе потоковых данных в Databricks Lakehouse. Другими словами, мы обучим и запустим в производство модель машинного обучения для прогнозирования потоковых данных, не написав ни единой строчки на Python!
На диаграмме ниже я разбил сквозной процесс на 5 этапов для ясности. Здесь все преобразования, которые вы будете создавать, будут выполняться в SQL и выполняться в конвейере Delta Live Tables (DLT). Если вы не знакомы с такими функциями, как DLT и Databricks AutoML, я буду добавлять больше цветов, когда мы описываем шаги.

Давайте подробнее рассмотрим 5 шагов.
- Загрузите данные и обучите модель машинного обучения с помощью низкокодового интерфейса Databricks AutoML.
- Скопируйте автоматически созданный код UDF Spark и требования из пользовательского интерфейса MLflow и вставьте в ячейки записной книжки Databricks.
- Запишите преобразования SQL, которые вы хотите выполнить для потоковых данных, в записной книжке Databricks с SQL в качестве языка по умолчанию.
- Создайте конвейер DLT, используя интерфейс DLT, и нажмите «Выполнить». Ваш конвейер потокового вывода машинного обучения начнет преобразовывать и делать выводы относительно модели машинного обучения на лету!
- Визуализируйте результаты, используя, как вы уже догадались, SQL с Databricks SQL.
Как вы видите здесь, хотя это и 5 шагов, процесс создания этого потокового конвейера довольно прост и вполне соответствует набору навыков энергичного аналитика SQL.
Этот общий шаблон применим во многих случаях использования. Для целей этого блога мы выберем сценарий профилактического обслуживания, в котором мы обучаем модель машинного обучения прогнозировать сбои машины и развертываем модель для потока входящих показаний датчиков машины.
Теперь давайте погрузимся и начнем строить!
Я разместил весь код и данные, необходимые для всего этого упражнения, в этом общедоступном репозитории Github. Данные, которые мы используем в этом примере, представляют собой очищенную версию набора данных классификации профилактического обслуживания этой машины от Kaggle.
Клонировать репозиторий примеров кода с помощью репозиториев
Databricks обеспечивает бесшовную интеграцию с рядом поставщиков Git, таких как Github и Gitlab с Databricks Repos. Мы можем использовать репозитории, чтобы клонировать указанный выше репозиторий, чтобы начать работу.
Сначала скопируйте URL-адрес репозитория Git из пользовательского интерфейса Github.
Щелкните значок репозитория на левой вкладке интерфейса рабочей области Databricks. Щелкните правой кнопкой мыши открытую вкладку и выберите «Добавить репозиторий» в раскрывающемся меню. Вставьте URL-адрес в текстовое поле URL-адрес репозитория Git и нажмите «Создать». Это можно увидеть ниже.

Отправьте модель данных для обучения с помощью Databricks AutoML
Вы можете импортировать данные в Databricks из любой исходной системы под солнцем. Однако в этом примере цель состоит в том, чтобы все было просто. Сначала мы загрузим данные и создадим таблицу.
Перейдите к пользовательскому интерфейсу Databricks SQL с помощью переключателя персон.

Затем откройте обозреватель данных, чтобы перейти к пользовательскому интерфейсу загрузки данных (это предназначено только для небольших наборов данных для быстрого анализа).
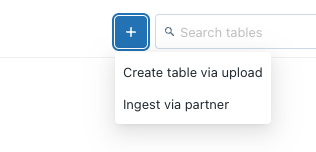
Нажмите «Создать таблицу с помощью загрузки» и перетащите файл .csv с образцами показаний машины в репозиторий Github (загрузите его локально и загрузите с помощью этого пользовательского интерфейса).
Вы увидите образец данных из файла.

Нажмите кнопку Создать. Теперь у вас есть таблица, которую Databricks AutoML может использовать для обучения модели машинного обучения.
Обучите модель машинного обучения с помощью Databricks AutoML
Databricks AutoML обеспечивает подход к автоматизированному машинному обучению с минимальным объемом кода. Одним нажатием кнопки вы можете запустить систему для поиска лучшей модели машинного обучения для данной задачи машинного обучения. Он будет выполнять интеллектуальный байесовский поиск гиперпараметров и моделей и предоставлять обученные модели машинного обучения и соответствующие блокноты, которые использовались для создания моделей. Эти записные книжки хорошо прокомментированы и при необходимости легко модифицируются. Такой подход «стеклянного ящика» резко контрастирует с большинством систем AutoML «черный ящик», присутствующих сегодня на рынке. Система также создает блокнот исследования данных, который полностью автоматизирует процесс исследовательского анализа данных.
Теперь приступим! Снова перейдите к переключателю персон и выберите персону машинного обучения.
Затем щелкните ссылку Start AutoML в пользовательском интерфейсе.

При выполнении чего-либо, связанного с машинным обучением на Databricks, всегда используйте кластер со средой выполнения машинного обучения. Этот пример был создан с использованием кластера среды выполнения 10,5 ML, и я рекомендую вам использовать его для беспрепятственного воспроизведения результатов.
Оставьте классификацию типа проблемы машинного обучения по умолчанию, отмените выбор переменной типа отказа (чтобы избежать утечки данных) и выберите «Цель» в качестве цели прогноза. Затем нажмите яркую синюю кнопку, и AutoML сделает всю работу за вас!

В AutoML есть намного больше, чем я буду обсуждать здесь, и это определенно стоит проверить.
Как только тренировочный процесс завершен. Вы увидите блокноты, соответствующие топ-модели, блокнот исследования данных и список моделей (и соответствующих блокнотов) под ним. Щелкните ссылку артефакта модели для топ-модели. В этом случае модель LightGBM была самой производительной моделью, созданной Databricks AutoML. MLflow, платформа с открытым исходным кодом, разработанная Databricks и тесно интегрированная с платформой, работает под капотом для отслеживания и регистрации всех моделей, созданных таким образом с помощью AutoML.
Благодаря MLflow в этом интерфейсе вы увидите все, что требуется для развертывания модели в любой системе развертывания. Зарегистрируйте модель, нажав кнопку, и скопируйте код Spark UDF и зависимости в файле requirements.txt в текстовый редактор.
Зачем вам писать Python, если вы можете скопировать и вставить (и немного изменить) его!

Создайте блокнот для регистрации UDF
Чтобы использовать модель машинного обучения, которую мы получили выше, в потоковом приложении, нам нужно применить ее как определяемую пользователем функцию Apache Spark (UDF). Автоматически сгенерированный код, который мы скопировали выше, заключает модель в высокоэффективную векторизованную определяемую пользователем функцию, которую затем можно использовать для выполнения распределенного логического вывода в кластере либо в пакетных, либо в потоковых приложениях. Как это относится к столам Delta Live? Мы вернемся к этому после того, как соберем блокнот для регистрации UDF.
Откройте записную книжку Python и вставьте зависимости, скопированные из файла requirements.txt. Добавьте перед каждой строкой «% pip install», как показано ниже.
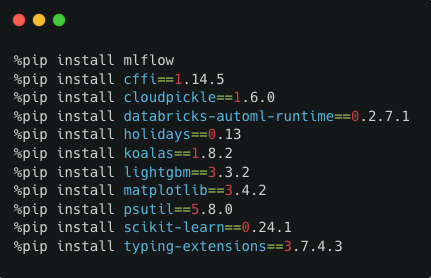
Затем в ячейку ниже вставьте код, скопированный из поля с автоматически сгенерированным кодом PySpark UDF. Внизу скопируйте и вставьте следующую строку:
spark.udf.register("predict_failure", loaded_model)
Просто чтобы я мог сдержать свое обещание, что вы не будете писать Python вручную :)
Вторая ячейка должна выглядеть следующим образом:
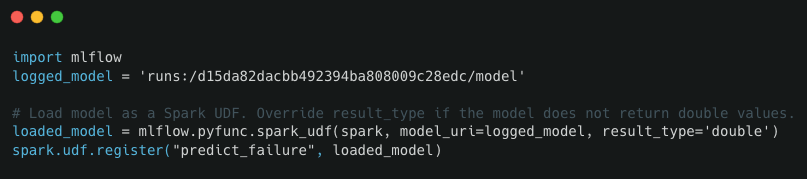
Подводя итог, этот фрагмент загружает модель как UDF искры и регистрирует ее, чтобы ее можно было использовать в потоковом конвейере.
Что такое живые столы Delta?
Delta Live Tables (DLT) — это декларативная платформа ETL, которая позволяет вам сосредоточиться на написании логики преобразования данных на SQL или Python, а также автоматизирует и абстрагирует основную сложность построения и обслуживания конвейеров данных производственного уровня. С помощью DLT вы можете создавать потоковые или пакетные конвейеры данных, не зная ни Apache Spark, ни каких-либо других фреймворков. Помимо ETL, DLT можно эффективно использовать для создания конвейеров разработки функций машинного обучения и конвейеров логического вывода.
В этом примере мы объединяем ETL и вывод модели в потоковом конвейере. (В DLT есть многое, например, мониторинг качества данных, который я не буду обсуждать в этом блоге, поэтому обязательно ознакомьтесь с документацией)
Загрузка данных для приема с помощью автозагрузчика в DLT
Для потокового конвейера данные должны постоянно приниматься по мере их создания/попадания в хранилище объектов. Автозагрузчик Databrick существует именно для этой цели. Автозагрузчик используется для загрузки данных в конвейер DLT, и для имитации этого процесса в этом примере мы повторно загрузим образец того же набора данных в файловую систему Databricks (DBFS).
Укажите подкаталог и загрузите данные в DBFS, перейдя к интерфейсу загрузки DFBS, щелкнув значок «Данные» на левой вкладке в представлении «Машинное обучение» или «Наука и инженерия данных» рабочей области Databricks.

Обратите внимание на это расположение в DBFS, которое будет использоваться позже в записной книжке SQL (указано рядом с галочкой на изображении выше).
Составление логики преобразования DLT в SQL
Создайте записную книжку с SQL в качестве языка по умолчанию. Он будет содержать ETL и логику вывода модели. Вы должны иметь возможность использовать записную книжку в клонированном репо, чтобы воспроизвести этот пример. Единственное, что нужно изменить, — это каталог в DBFS с данными, которые будут загружаться в конвейер.
Давайте внимательно изучим код приема данных:

Приведенный выше оператор SQL создает потоковую таблицу в реальном времени в DLT. Этот синтаксис специфичен для DLT и создает таблицу, в которую будет выполняться потоковая передача при запуске в непрерывном режиме (мы доберемся до этого). Здесь мы видим комментарий, добавленный для предоставления дополнительной информации о логике этого шага. Мы используем автозагрузчик (функция cloud_files) для постепенной загрузки файлов .csv из указанного каталога в таблицу Bronze при динамическом выводе схемы. В архитектуре медальонов Databricks таблица Bronze содержит необработанные данные, поступающие из хранилища объектов. Это объявлено как свойство таблицы. Обратите внимание, что свойство comment и table здесь необязательны.
Затем мы выполняем некоторую очистку данных и проверку качества перед передачей записей, которые будут выводиться моделью.
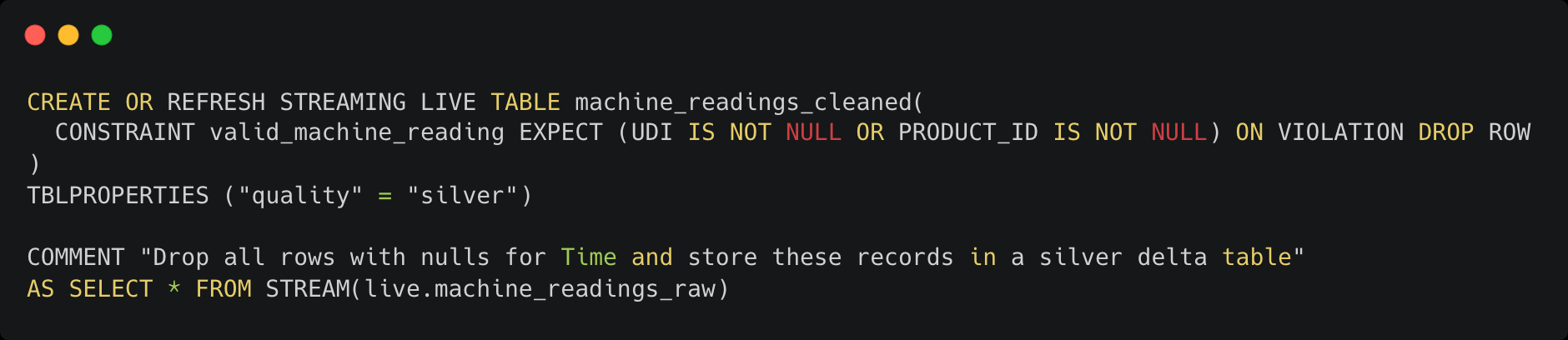
Здесь мы создаем еще одну таблицу потокового вещания, но с изюминкой. У нас есть ограничения качества данных, которые отслеживают два поля в данных, проходящих через этот шаг, на наличие нулевых значений и удаляют записи, где это ограничение не выполняется. Прелесть DLT заключается в том, что данные, относящиеся к ограничениям качества, собираются по мере выполнения конвейера (к чему мы скоро вернемся). Созданный таким образом стол чище, следовательно, это Серебряный стол.
Наконец, мы добираемся до золотой таблицы, где записи оцениваются/прогнозируются с помощью UDF, зарегистрированного в предыдущей записной книжке. Мы предсказываем рекорды с помощью модели LightGBM по потоковой передаче данных в SQL!

Но подождите, код для регистрации UDF находится совсем в другом блокноте. И если бы вы попытались запустить блокнот SQL ячейка за ячейкой, вы бы увидели что-то вроде этого:
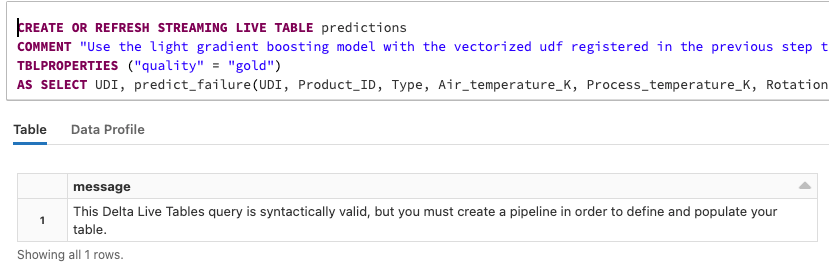
Он просто обеспечивает проверку синтаксиса (что очень полезно, но далеко от конвейера потокового вывода ML!).
Нам нужно создать фактический конвейер DLT из этих двух ноутбуков.
Собираем все вместе с Delta Live Tables
Перейдите к представлению «Машинное обучение» или «Наука и инженерия данных» в интерфейсе рабочей области и щелкните вкладку «Таблицы Delta Live».

Затем нажмите кнопку «Создать конвейер».
Введите имя по вашему выбору для конвейера и добавьте обе записные книжки в качестве библиотек записных книжек в соответствующий раздел (порядок не имеет значения. DLT определит зависимости). Я рекомендую выполнить следующую строку в блокноте SQL в другом месте/редакторе SQL-запросов Databricks, чтобы иметь место для хранения таблиц, созданных в конвейере DLT:
CREATE DATABASE IF NOT EXISTS Machine_predictions
Введите это имя базы данных в поле ввода «Цель» и выберите «Непрерывный» для конвейерного режима. Это необходимо для создания потокового конвейера. Для пакетной обработки выберите триггер. Существует множество других вариантов, и я предлагаю вам изучить их, поскольку они показывают, в какой степени DLT автоматизирует проблемы, связанные с ETL.
Ваши конфигурации должны выглядеть примерно так.

Щелкните Создать.
Через несколько минут у вас будет конвейер потоковой передачи, который выполняет прогнозы с использованием машинного обучения для входящих записей!

Как видите, это делается в режиме разработки. В производственном сценарии вы можете переключиться на производство после тестов, а ряд функций, таких как перезапуск кластера и автоматические повторные попытки конвейера, включенные DLT, делают процесс бесшовным.
Обратите внимание, что выборочные данные, используемые в этом примере, очень малы. DLT как инфраструктура спроектирована для обработки объемов данных от килобайта до петабайта в реальных сценариях.
О DLT можно многое обсудить, но я не буду в этом блоге. Я рекомендую вам посмотреть это короткое видео для краткого обзора.
Запрос результатов с помощью Databricks SQL
Теперь давайте воспользуемся SQL, чтобы взглянуть на прогнозы, сгенерированные этим конвейером.
Переключитесь на Databricks SQL и выполните следующий запрос в редакторе запросов:
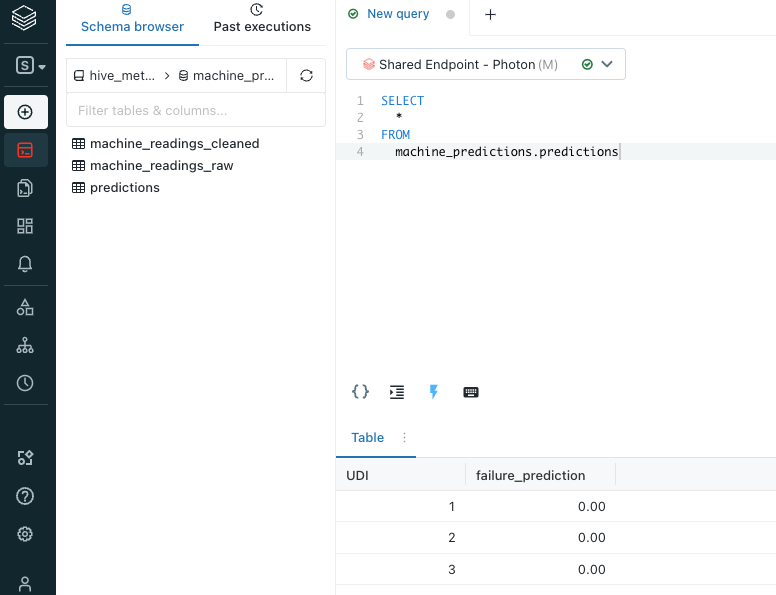
Вы должны увидеть идентификатор записи и прогнозы модели, которые мы ожидаем увидеть в таблице Gold! Вы также увидите бронзовые и серебряные таблицы в базе данных, и их можно запросить одинаково легко.
Вот оно. Мы использовали возможности AutoML с низким кодом в Databricks для обучения модели машинного обучения, которая была развернута в потоке в конвейере, созданном с использованием Delta Live Tables. Просто указывая и щелкая, используя автоматически сгенерированный код и прямой SQL! Это открывает целый мир возможностей для групп данных по всему миру, где SQL является наиболее доступным навыком. Я приглашаю вас попробовать этот пример, настроить что-то, создать свой собственный и, надеюсь, использовать этот шаблон для реальных случаев использования в вашей повседневной работе!