В этой статье будет рассмотрена классификация K-ближайших соседей (KNN) как инструмент для построения алгоритма обнаружения рака кожи с использованием набора данных HAM10000.

Эта статья является частью большой серии, посвященной набору данных HAM10000 — пожалуйста, обратитесь к вводной статье. Рекомендуется прочитать предыдущую статью из серии Логистическая регрессия на HAM10000, так как предполагается, что читатель уже понял контекст статьи.
Мотивация
Классификация K-ближайших соседей (KNN) — это метод статистического моделирования, который определяет метку для входных данных на основе их сходства с другими примерами. Он вычисляет расстояние между входными данными и имеющимися у него примерами из обучающего набора, определяет k ближайших соседей и присваивает метку на основе метки большинства своих k ближайших соседей. Более подробное объяснение и пошаговое руководство по алгоритму можно найти здесь: Необходимо расстояние от соседей
В контексте HAM10000 входными данными будет изображение поражения кожи, которое будет сравниваться с изображениями в обучающем наборе. Модель рассчитает расстояние между входным изображением и изображениями тренировочного набора, ранжирует изображения тренировочного набора в порядке от наименьшего до наибольшего «расстояния» и выберет метку с мажоритарным представлением в первых k изображениях тренировочного набора.
В классификации KNN важным компонентом является определение того, как рассчитывается расстояние и значение k. Поскольку мы работаем с данными изображения, которые состоят из числовых значений пикселей, мы можем использовать числовые формулы расстояния, такие как евклидово и минковское расстояние. Мы также можем создать свою собственную метрику расстояния на основе значений пикселей, хотя нет гарантии, что она будет полезной — нам нужно провести эмпирические исследования, чтобы определить это. В этой статье мы будем придерживаться метрики расстояния по умолчанию, используемой учебной библиотекой sci-kit, которая представляет собой евклидово расстояние, поскольку она имеет очень интуитивное геометрическое значение. Предпосылка состоит в том, что длина между двумя точками определяется длиной отрезка прямой линии, который их соединяет (таким образом, другое название евклидова расстояния — расстояние по прямой). Ниже представлена визуализация евклидова расстояния в двух измерениях.

Обобщенная математическая формулировка для двух n-мерных точек, p и q. , является:

Обратите внимание, что в формуле предполагается, что p и qявляются одномерными векторами. В случае двумерных изображений мы можем сгладить их до одномерного и рассматривать как многомерную координатную точку — ниже показан процесс сглаживания.

В этом плоском представлении очень просто подключить изображения к формуле евклидова расстояния.
Что касается значения k, оно обычно определяется путем экспериментов (на жаргоне машинного обучения это называется настройкой гиперпараметров). Мы пробуем разные значения k, смотрим, какое из них обеспечивает наибольшую точность теста, и считаем, что это лучшее значение k. Позже в этой статье мы поэкспериментируем со значениями в k при выборе нашего классификатора KNN.
Подобно логистической регрессии, KNN — это полезный первый шаг и отличная базовая модель — она интуитивно понятна, проста/быстра в реализации (особенно с библиотекой scikit-learn) и имеет множество настраиваемых параметров/гиперпараметров для настройки (например, , значение k, показатель расстояния и т. д.). По мере повторения наших моделей мы вернемся к этой модели классификации KNN и посмотрим, помогла ли дополнительная сложность улучшить наши результаты.
Подготовка данных
Как обсуждалось в разделе Уменьшение масштаба изображений в HAM10000, мы будем использовать уменьшенную форму исходных данных изображения, чтобы уменьшить использование памяти и ускорить время выполнения. Уменьшенные изображения будут в градациях серого с высотой 150 пикселей и шириной 200 пикселей.
Кроме того, применимы многие этапы подготовки данных, описанные в Логистической регрессии на HAM10000 (дополнительный контекст см. в этой статье).
- Данные изображения представляют собой двумерные пространственные данные — scikit-learn ожидает одномерные векторы, поэтому мы сгладим изображения по строкам (как показано ниже). Кроме того, представление плоского вектора необходимо для вычисления метрики евклидова расстояния.
- Библиотека scikit-learn ожидает, что метки будут числовыми, поэтому мы преобразуем диагноз в число. Схема будет
0дляakiec,1дляbcc,2дляbkl,3дляdf,4дляmel,5дляnv,6дляvasc. - Для оценки нам нужны некоторые тестовые данные, которые модель не видела, поэтому мы будем использовать разделение тестов поезда 80/20.
Результаты и оценка модели
Используя значение scikit-learn по умолчанию k = 5, мы достигаем точности ~ 68% — это очень похоже на точность, которую мы достигли с помощью нашей модели логистической регрессии. Как мы обнаружили из нашего логистического регрессионного анализа, эта общая точность ~ 68% может быть очень обманчивой, поскольку у нас такой несбалансированный набор данных. Давайте исследуем матрицу путаницы для нашего классификатора KNN с k = 5:
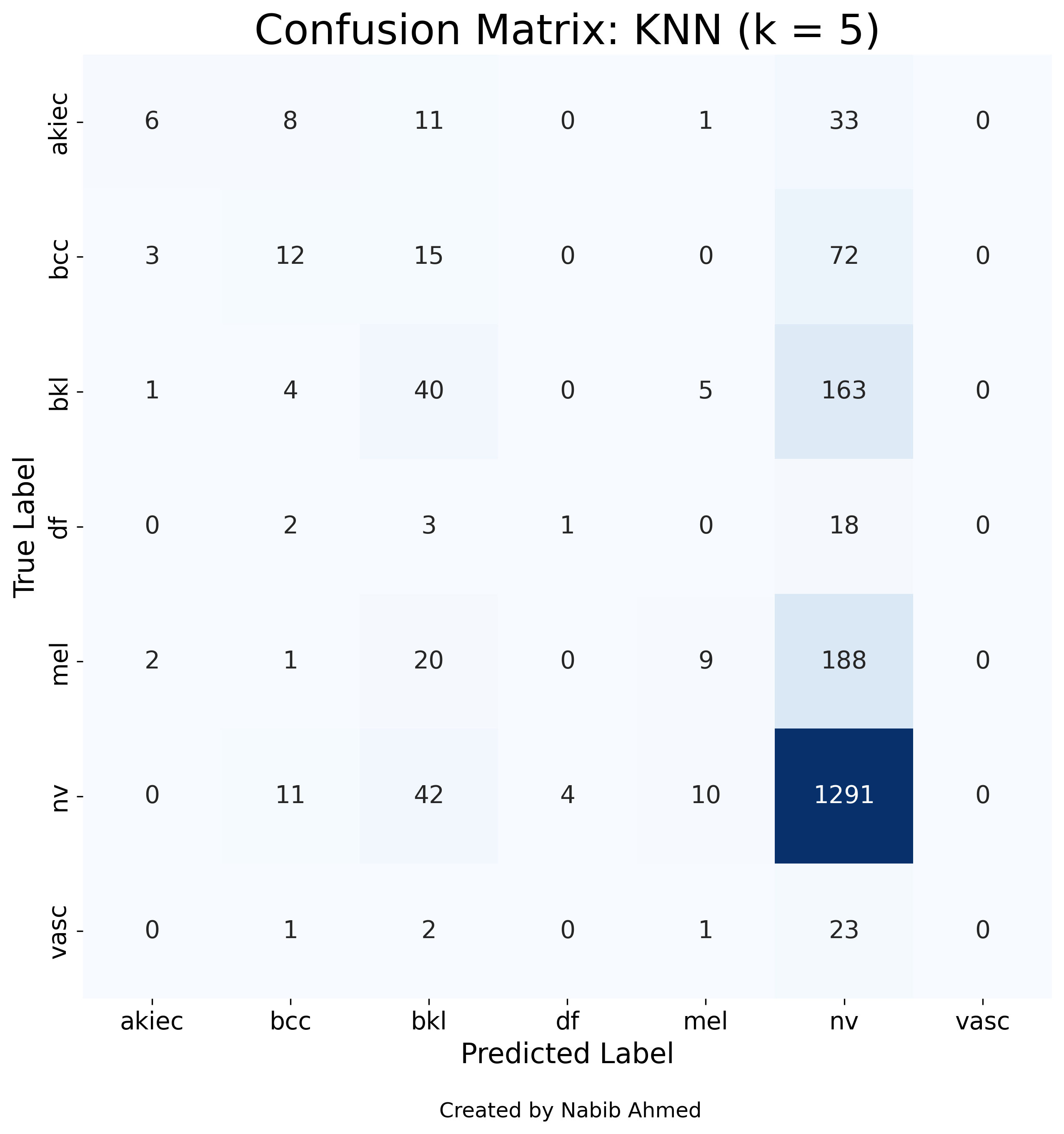
Мы видим очень похожую историю на нашу модель логистической регрессии. Столбец nv имеет наибольшее количество правильных и неправильных классификаций, что демонстрирует, что наша модель сравнима с бессмысленным классификатором, который всегда диагностирует nv (точность которого составляет ~67%).
Давайте поэкспериментируем и посмотрим, есть ли значение k, которое заставляет классификатор KNN работать намного лучше, чем бессмысленный, всегда nv классификатор. Диапазон значений, которые может принимать k, составляет от 1 до примерно ~8000 (поскольку наш тренировочный набор составляет ~8000 изображений, и наличие большего k, чем тренировочный набор, не влияет на производительность). Пробовать каждое значение k немного излишне и пустая трата времени — обычно мы не ожидаем существенного изменения производительности между k и k + 1. Таким образом, чтобы сэкономить время вычислений, мы будем работать с интервалами. Кроме того, не имеет смысла пробовать очень большие значения k, потому что после определенного момента все метки начнут классифицироваться как одна и та же метка. Поскольку nv представлен слишком много, если наше значение k очень велико, может начаться подсчет группы nv соседей. Возьмем, к примеру, крайнее значение k 8000 — в этот момент все изображения будут помечены как доминирующая категория в наборе обучающих данных, которая равна nv. Таким образом, мы хотели бы поэкспериментировать с более низкими значениями k и расширить наш интервал в сторону более высоких значений k. Если определенный диапазон k демонстрирует интересную закономерность, мы можем увеличить масштаб и попробовать другие значения k в пределах этого диапазона. Учитывая эти решения, мы будем использовать собственный интервал значений k, которые имеют меньшие интервалы для меньших значений и большие интервалы для больших значений.
Все это планирование направлено на то, чтобы сэкономить время — часто при моделировании можно провести много кроличьих нор и экспериментов, но наше время ограничено, поэтому важно думать о своем собственном времени, когда вы планируете эксперименты. Это важный показатель, который следует учитывать при определении компромиссов. Кроме того, время может буквально стоить денег — в этом контексте, когда мы используем локальную машину или Google Colab, время вычислений практически бесплатно (если мы отбросим стоимость электроэнергии, Интернета, облачного хранилища и т. д.). Однако это не всегда так — мы можем использовать кластерное или облачное решение, которое взимает плату в зависимости от времени вычислений (например, AWS). В этих случаях решения, подобные тому, что мы приняли выше, имеют решающее значение для экономии затрат.
Экспериментируя с различными значениями k и отслеживая общую точность теста, получаем следующий график:

На графике показана плоская линия, пересекающая различные значения k, с которыми мы экспериментировали, с точностью около 68 % (между k=10 и k=15 наблюдается незначительное увеличение до 69 %, но оно не кажется значительным, учитывая, насколько оно близко по точности). к другим значениям k). Это указывает на то, что на наш классификатор KNN не влияет значение k, и демонстрирует, что наш классификатор не намного лучше, чем бессмысленный, всегда nv классификатор. Поскольку KNN работает путем сравнения ближайших соседей, а класс nv представлен слишком много, независимо от используемого значения k, класс nv, кажется, всегда доминирует. Таким образом, потенциальным следующим шагом будет устранение дисбаланса и проверка того, как работает модель KNN.
Результаты для этой модели логистической регрессии можно найти в этом Google Colab. Полный код также приведен ниже (примечание: он предназначен для среды Google Colab и может не работать на локальном компьютере).
Заключение
В этой статье мы реализовали простую базовую модель с классификацией K-ближайших соседей (KNN). Мы обсудили механизм и мотивацию модели (она присваивает метки на основе метки большинства k ближайших изображений с использованием евклидовых расстояний), необходимую подготовку данных (выравнивание наших изображений, кодирование наших меток в виде чисел и выполнение разделения тестов поезда на наших данные) и оценка результатов нашей модели (общая точность составила ~ 68%, но после изучения матрицы путаницы и распределения меток ее производительность ненамного лучше, чем у бессмысленного классификатора, который всегда выбирает доминирующую метку; кроме того, , после настройки гиперпараметров потенциальных значений k производительность не изменилась, что указывает на неспособность модели преодолеть дисбаланс набора данных).