
Вы когда-нибудь проходили процесс внедрения Spark в свой проект, определяя оптимальное количество разделов в случайном порядке, выделение памяти для экземпляров драйвера и исполнителя, количество ядер исполнителя и все эти забавные вещи только для чтения данных из источника JDBC, подобного этому? ?
jdbcDF = spark.read \
.format("jdbc") \
.option("driver", "org.postgresql.Driver") \
.option("url", "jdbc:postgresql:dbserver") \
.option("user", os.environ['user']) \
.option("password", os.environ['pass']) \
.option("query", query) \
.load()
Для механизма, используемого для крупномасштабной распределенной обработки данных, документация Spark об источниках данных JDBC не так много внимания уделяет тому, почему приведенный выше фрагмент не является лучшим способом чтения данных из реляционной базы данных, но именно поэтому я Я пишу эту статью, а также потому, что я видел запросы Spark, написанные таким образом, в проектах, частью которых я был.
В чем проблема кода выше? Ну… это очень медленно :) Если вы выполните SQL-запрос в Spark, как в приведенном выше примере, вы будете использовать только один поток (вы можете видеть в пользовательском интерфейсе Spark, что во время выполнения кода выполняется только одна задача), и созданный фрейм данных будет иметь один раздел.
Большинство из нас используют Spark в конвейерах ETL/ELT для параллельной обработки, поэтому чтение данных из источника JDBC с использованием только одного потока, вероятно, не то, что нам нужно. Не говоря уже о том, что нам придется перераспределить фрейм данных после выполнения запроса, потому что данные теперь хранятся в 1 разделе. Итак, как мы на самом деле можем одновременно читать данные в Spark?
# pass the original query to dbtable as a subquery
final_query = f'({query}) as q'
# depends on your usecase, how many executor cores you have in the cluster
# what do you plan to do with the dataframe downstream, data size etc
partitionsCount = 100
# I'm hardcoding the date values here, but I'll show below how to identify
# these values at run time if you don't know them upfront
min_date = '2020-01-01'
max_date = '2022-12-31'
jdbcDF = spark.read \
.format("jdbc") \
.option("driver", "org.postgresql.Driver") \
.option("url", "jdbc:postgresql:dbserver") \
.option("user", os.environ['user']) \
.option("password", os.environ['pass']) \
.option("dbtable", final_query) \
.option("numPartitions", partitionsCount) \
.option("partitionColumn", "date") \
.option("lowerBound", f"{min_date}") \
.option("upperBound", f"{max_date}") \
.load()
Вы можете видеть, что аргументы первой опции идентичны, но последние опции не появлялись в исходной команде spark.read(). Давайте обсудим каждый из них:
- dbtable:
Согласно официальной документации Spark, если мы хотим одновременно считывать данные и разбивать их в соответствии с нашими потребностями, мы больше не можем использовать запрос. вместо этого должен передавать наш SQL-запрос через параметр dbtable . Единственная разница между этими двумя параметрами (кроме имени) заключается в том, что теперь запрос должен быть заключен в круглые скобки и иметь псевдоним — по сути, исходный запрос передается как подзапрос. - numPartitions
Максимальное количество разделов, которые можно использовать для параллелизма при чтении и записи таблицы. Это также определяет максимальное количество одновременных подключений JDBC. Если количество разделов для записи превышает этот предел, мы уменьшаем его до этого предела, вызывая объединение (numPartitions) перед записью. (источник) Я установил значение 100 в кластере EMR , но хорошей практикой было бы установить номер раздела в диапазоне от 1 до 4, умноженный на количество ядер. Однако это не число, высеченное на камне, поэтому всегда проверяйте разные значения, чтобы увидеть, что работает для вас. - partitionColumn:
Это, вероятно, самый важный параметр, который больше всего влияет на время выполнения ваших запросов. Несколько вещей, о которых следует помнить:
– рассматриваемый столбец должен быть числовым, датой или отметкой времени.
– для наилучшей производительности значения столбца должны быть как можно более равномерно распределены и иметь большое количество элементов. Мы хотим избежать искажения данных в столбцах — я расскажу об этом ниже.
— если у вас есть несколько столбцов с указанными выше свойствами, выберите проиндексированный столбец. - нижняя граница, верхняя граница:
Обратите внимание, что нижняя граница и верхняя граница используются только для определения шага раздела, а не для фильтрации строк в таблице. Таким образом, все строки в таблице будут разбиты на разделы и возвращены. (источник) Ниже вы увидите, как Spark генерирует каждый раздел. Вот почему вам не нужен столбец с низкой кардинальностью в качестве столбца раздела, но я приведу пример ниже на случай, если сейчас это не имеет смысла.
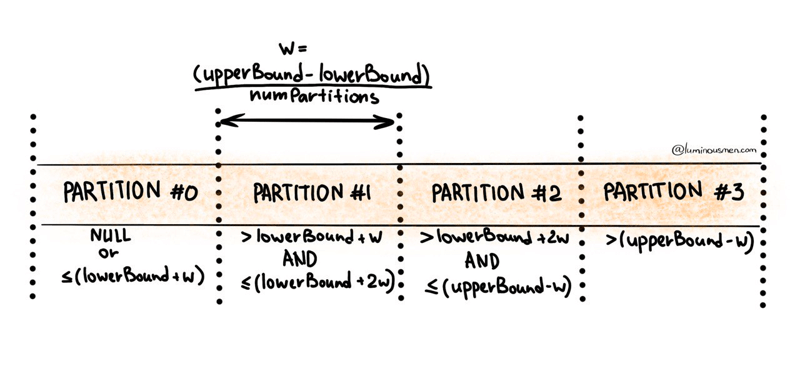
Низкая кардинальность, высокая кардинальность и почему меньше не всегда значит больше
Представьте, что столбец, который вы хотите использовать для разделения, имеет только значения 0 и 1 — действительно экстремальный пример, но распространенный сценарий в Data Engineering, где логические значения True и False равны преобразованы в числовые значения.
Поскольку у вас есть только 0 и 1, вы используете 0 в качестве нижней границы и 1 в качестве верхней границы. В зависимости от того, как генерируются разделы (см. рисунок выше), все строки со значением 0 будут перемещены в первый раздел (предложение WHERE первого раздела — единственное предложение, где 0 не является отфильтровано) и все строки со значением 1 будут перемещены в последний раздел (предложение WHERE последнего раздела является единственным предложением, где 1 не отфильтровывается).
Таким образом, независимо от того, сколько разделов вы создадите, только два раздела будут заполнены и только два ядра-исполнителя будут выполнять всю работу, остальные будут находиться в состоянии простоя, если для них не запланировано другое задание. Из-за этого производительность вашего запроса пострадает.
Асимметрия данных

Давайте представим, что у нас есть набор данных с 20 миллионами строк и 30 разделами, нижняя и верхняя границы — 01–01–2020 и 31–12 2022. Для целей этой статьи я буду использовать сеанс Spark с 30 исполнительными ядрами (это означает, что мы можем запускать до 30 задач одновременно). Имейте в виду, что Spark назначает одну задачу на раздел, поэтому каждый раздел будет обрабатываться одним ядром-исполнителем.
Данные за каждый год будут разделены на 10 разделов, и, учитывая, что 1 задача будет назначена 1 разделу, каждая задача, назначенная на 2020 и 2021 годы, будет отвечать за обработку 100 тыс. строк, но каждая задача, назначенная на 2022 год, должна будет обрабатывать 1,8 млн строк. Это на 1700% больше данных, которые должны быть обработаны одной задачей.
В результате первые 20 задач завершат обработку назначенного им раздела в кратчайшие сроки, а после этого 20 ядер-исполнителей, назначенных завершенным задачам, будут бездействовать (если нет другого задания, в котором можно было бы использовать простаивающие ядра-исполнители) до последнего. 10 задач завершают обработку на 1700% больше записей. Это пустая трата ресурсов и увеличение эксплуатационных расходов, особенно если вы используете Spark в кластере EMR, Glue Job или Databricks.
Как это исправить? Самое простое решение: использовать другой столбец для разделения. Но если использование этого столбца критично, мы можем использовать два запроса и два фрейма данных вместо одного. У вас по-прежнему будут проблемы с искаженными данными в нисходящем направлении (постоянная проблема в параллельных вычислительных системах), но мы решаем одну проблему за раз.
Первый запрос загрузит первые два года (30 ядер-исполнителей будут разделены между 2020 и 2021 годами), затем второй запрос загрузит последний год (таким образом, все 30 ядер-исполнителей теперь будут использоваться для 2022 года). Из-за этого данная задача, связанная с 2022 годом, теперь будет отвечать за обработку 600 тыс. строк вместо 1,8 млн строк. Это на 66% меньше строк, которые должны обрабатываться одним ядром исполнителя, по сравнению с исходной реализацией, и, кроме того, теперь мы используем все ядра исполнителя из нашего сеанса Spark вместо того, чтобы простаивать.
Что делать, если у меня нет столбца с числовым значением, датой или временной меткой или в столбце есть искаженные данные?
Не проблема. Для инженеров данных использование CTE и оконной функции для создания числового столбца через row_number() должно быть простым делом. При создании нового столбца будут введены некоторые накладные расходы, но даже с учетом этих накладных расходов окончательный запрос будет выполняться намного быстрее с использованием вновь созданного столбца, а не при попытке загрузить все данные в один раздел с помощью одного ядра исполнителя.
with cte as
(
SELECT f1, f2, f3
FROM table
)
select *, row_number() over (order by f1) as rn from cte
В Python приведенный выше синтаксис будет выглядеть так:
original_query = "SELECT f1, f2, f3 FROM table"
final_query = f'(with cte as ({original_query}) select *, row_number() over (order by f1) as rn from cte) as q'
Что делать, если я заранее не знаю нижнюю и верхнюю границы нашего столбца?
Мы выполняем два запроса вместо одного:
— первый запрос будет выполняться для нахождения минимального и максимального значений столбца, который мы будем использовать в качестве partitionColumn
— во втором query мы будем передавать результаты первого запроса в качестве аргументов нижняя граница и верхняя граница.
query_min_max = f"SELECT min(date), max(date) from ({query}) q"
final_query = f"({query}) as q"
df_min_max = spark.read \
.format("jdbc") \
.option("driver", "org.postgresql.Driver") \
.option("url", "jdbc:postgresql:dbserver") \
.option("user", os.environ['user']) \
.option("password", os.environ['pass']) \
.option("query", query_min_max) \
.load()
min = df_min_max.first()["min"]
max = df_min_max.first()["max"]
jdbcDF = spark.read \
.format("jdbc") \
.option("driver", "org.postgresql.Driver") \
.option("url", "jdbc:postgresql:dbserver") \
.option("user", os.environ['user']) \
.option("password", os.environ['pass']) \
.option("dbtable", final_query) \
.option("numPartitions", partitionsCount) \
.option("partitionColumn", "date") \
.option("lowerBound", f"{min}") \
.option("upperBound", f"{max}") \
.load()
Выводы
- Если вы проходите процесс внедрения Spark в свое приложение, постарайтесь использовать его на полную катушку и параллельно считывать данные. Выполнение SQL-запроса к spark.read(), как показано в документации JDBC Spark, поместит все данные в один раздел и будет использовать только одно ядро исполнителя, независимо от того, сколько ядер вы настроили в сеансе Spark.
- Если вы используете Spark сегодня для чтения данных из источников данных JDBC с использованием однопоточного подхода, попытаетесь реорганизовать свои запросы и повысить их производительность, вы можете даже получить повышение, пока вы это делаете :)
- В конце концов, время — деньги. Если вас беспокоят усилия по переписыванию ваших запросов, могу сказать по опыту: некоторые из запросов Spark, которые я рефакторил с помощью описанных выше методов, теперь выполняются ›на 90 % быстрее, чем раньше. Можете себе представить, какой положительный отклик вызвало это улучшение в моей команде.
Спасибо, что прочитали эту статью! Надеюсь, вы нашли его информативным и полезным. Если это так, рассмотрите возможность поделиться ею с другими коллегами, которым она может быть полезна.
Габриэль