Практический пример анализа розничных данных

При анализе данных о розничной торговле крайне важно понимать факторы, влияющие на вовлеченность и реакцию клиентов. Двумя широко используемыми регрессионными моделями для анализа данных подсчета являются регрессия Пуассона и отрицательная биномиальная регрессия. В этом блоге мы углубимся в концепции этих моделей, изучим их приложения и узнаем, как определить, какую из них использовать в различных сценариях.
Предварительные требования.
Чтобы извлечь максимальную пользу из этого сообщения в блоге, полезно иметь базовое понимание регрессионного анализа и знакомство с языком программирования R. Кроме того, понимание данных подсчета и их характеристик улучшит ваше понимание обсуждаемых концепций.
Взаимосвязь среднего значения и дисперсии.
Прежде чем углубляться в модели регрессии, давайте сначала рассмотрим соотношение среднего значения и дисперсии целевой переменной Likes_count. Понимание этой взаимосвязи может дать представление о пригодности пуассоновской или отрицательной биномиальной регрессии для наших данных.
#Calculate the mean and variance of likes_count for each value of the subcategory variable
mean_var_df <- accessory %>% group_by(subcategory) %>% summarise(mean_likes = mean(likes_count), var_likes = var(likes_count))
#Plot the mean-variance relationship
ggplot(mean_var_df, aes(x = mean_likes, y = var_likes)) +
geom_point() +
scale_x_continuous(name = "Mean likes count") +
scale_y_continuous(name = "Variance of likes count") +
ggtitle("Mean-Variance Relationship for Likes Count")

Подготовка модели
Затем нам нужно подготовить данные для моделирования, разделив их на наборы для обучения и тестирования. Это позволяет нам оценить производительность наших моделей на невидимых данных.
### Dividng the data into test and train # Split data into training and testing sets set.seed(123) train_indices <- sample(nrow(accessory), 0.7*nrow(accessory)) # 70% for training train_data <- accessory[train_indices, ] test_data <- accessory[-train_indices, ]
Регрессия Пуассона.
Регрессия Пуассона подходит, когда целевая переменная подчиняется распределению Пуассона, а отношение средней дисперсии приблизительно равно. Давайте построим модель регрессии Пуассона, используя обучающие данные, и проверим предположения.
# Create Poisson regression model using training data
poisson_model <- glm(likes_count ~ current_price + raw_price + discount, data = train_data, family = "poisson")
poisson_aug <- augment(poisson_model)
# Linearity assumption: plot residuals vs. fitted values
ggplot(data = poisson_aug, aes(x = .fitted, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed", color = "red") +
xlab("Fitted values") +
ylab("Residuals")
# Overdispersion assumption: calculate dispersion parameter
dispersiontest(poisson_model)
После проведения теста сверхдисперсии на регрессионной модели Пуассона результаты показали значение z 3,7344 и значение p 9,408e-05. Альтернативная гипотеза указывала, что истинная дисперсия была больше 1. Кроме того, расчетный параметр дисперсии оказался равным 42,64843.
Этот анализ подтвердил наличие чрезмерной дисперсии в данных, что означает, что дисперсия переменной «Количество лайков» превысила свое среднее значение. Учитывая этот вывод, я принял решение перейти от модели регрессии Пуассона к модели отрицательной биномиальной регрессии.
Отрицательная биномиальная регрессия является подходящим выбором при работе с чрезмерно рассеянными данными подсчета. В отличие от регрессии Пуассона, которая предполагает равенство между средним значением и дисперсией, отрицательная биномиальная регрессия обеспечивает большую гибкость и учитывает более высокую дисперсию, наблюдаемую в данных. Используя модель отрицательной биномиальной регрессии, я смог лучше фиксировать и учитывать чрезмерную дисперсию в переменной «Количество лайков», что привело к более точным и надежным результатам моего анализа.
Перейдя на модель отрицательной биномиальной регрессии, я убедился, что использую подходящий статистический метод, который лучше соответствует характеристикам данных. Такой подход позволил мне преодолеть ограничения, связанные с чрезмерной дисперсией, и получить более четкое представление о факторах, влияющих на вовлеченность и реакцию розничных покупателей «Нового шика».
Отрицательная биномиальная регрессия.
Отрицательная биномиальная регрессия компенсирует чрезмерную дисперсию, позволяя дисперсии превышать среднее значение. Эта модель подходит, когда отношение средней дисперсии значительно отклоняется от равенства. Давайте рассмотрим этот вариант, подгоняя модель отрицательной биномиальной регрессии к нашим данным.
# Create Negative Binomial regression model using training data
nb_model <- glm.nb(likes_count ~ current_price + raw_price + discount, data = train_data)
nb_aug <- augment(nb_model)
# Linearity assumption
: plot residuals vs. fitted values
ggplot(data = nb_aug, aes(x = .fitted, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed", color = "red") +
xlab("Fitted values") +
ylab("Residuals")
Выбор между методом Пуассона и отрицательной биномиальной регрессией:
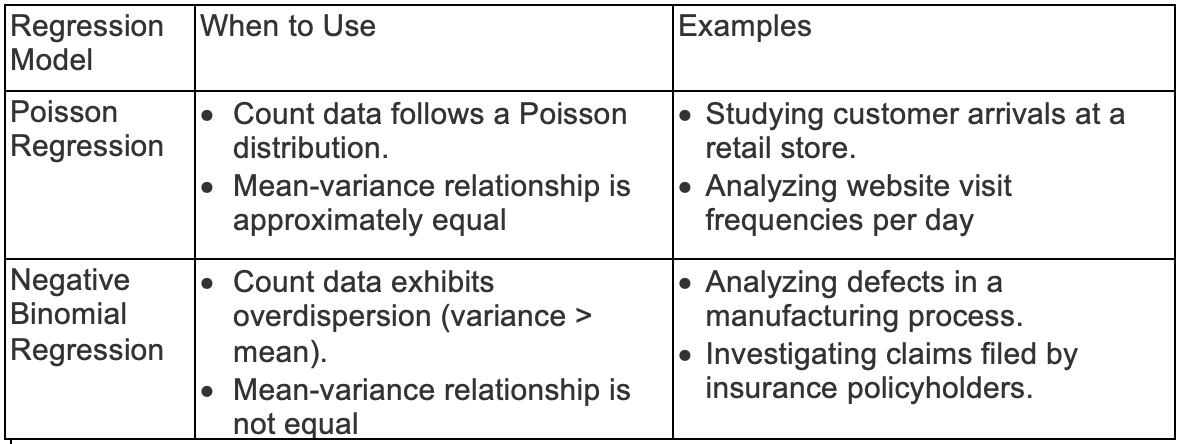
Понимание этих различий помогает выбрать подходящую модель регрессии на основе конкретных характеристик и характера имеющихся данных подсчета. Удачного анализа!
Если вы нашли этот блог полезным и хотите быть в курсе более информативного контента, рассмотрите возможность подписаться на меня на GitHub и LinkedIn. Вы также можете подписаться на мою рассылку на Medium, чтобы получать регулярные обновления и уведомления о новых сообщениях в блоге.
Спасибо за чтение, и я с нетерпением жду возможности поделиться с вами более ценными идеями в будущем!
Подписывайтесь на меня:
- Гитхаб: https://github.com/chdl17/
- LinkedIn: https://www.linkedin.com/in/maruthisai/
Приятного анализа и следите за новостями, чтобы не пропустить еще больше захватывающего контента!