
Регрессионный анализ делится на две группы: параметрическая и непараметрическая регрессия. Наиболее важной особенностью параметрического регрессионного анализа является то, что взаимосвязь между переменными можно объяснить функцией. Также; При параметрической регрессии следует сделать некоторые важные предположения. Вы можете получить доступ к этим предположениям и моим приложениям, применяющим параметрический регрессионный анализ, по ссылкам ниже:
- Приложения R - Часть 1: Простая линейная регрессия
- Приложения R - Часть 2: Множественная линейная регрессия
Когда предположения не представлены, необходимо принять некоторые меры по исправлению переменных в наборе данных. Таким образом, поскольку предоставлены необходимые допущения, их можно использовать в оценках.
В непараметрическом регрессионном анализе функция не определена заранее, и нет никаких существенных допущений, как в параметрическом регрессионном анализе. Основные методы оценки, используемые в непараметрической регрессии, основаны на сглаживании. По этой причине методы непараметрической регрессии еще называют более плавными.
Некоторые методы оценки, используемые в непараметрической регрессии, основаны на принципе сглаживания. Основная идея сглаживания заключается в использовании локально взвешенного среднего значения, оценочное значение зависимой переменной в данной точке x определяется путем взятия средневзвешенного значения точек в окрестности x. В непараметрической регрессии есть методы, используемые для нахождения локально взвешенного среднего.
Разберем методы непараметрической регрессии по элементам:
- Сглаживание ядра
- Сглаживание диаграммы рассеяния с локальным взвешиванием (НИЗКОЕ)
- Более плавный интервал бега (RIS)
- Сглаживание ограниченного B-сплайна (COBS)
1. Сглаживание ядра
В сглаживании ядра веса определяются функцией ядра. Эти функции ядра; Епанечников, двумерный, треугольный, гауссовский и форменный. Графики этих функций показаны ниже.
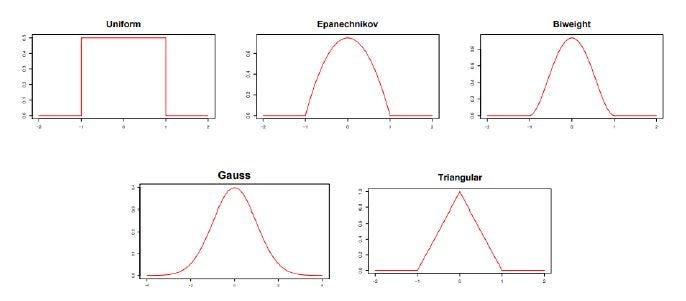
Наиболее предпочтительной функцией сглаживания ядра является функция ядра Епанечникова. Для сглаживания ядра функция «kerreg» может использоваться в пакете R «WRS2». Давайте применим этот метод к набору данных:
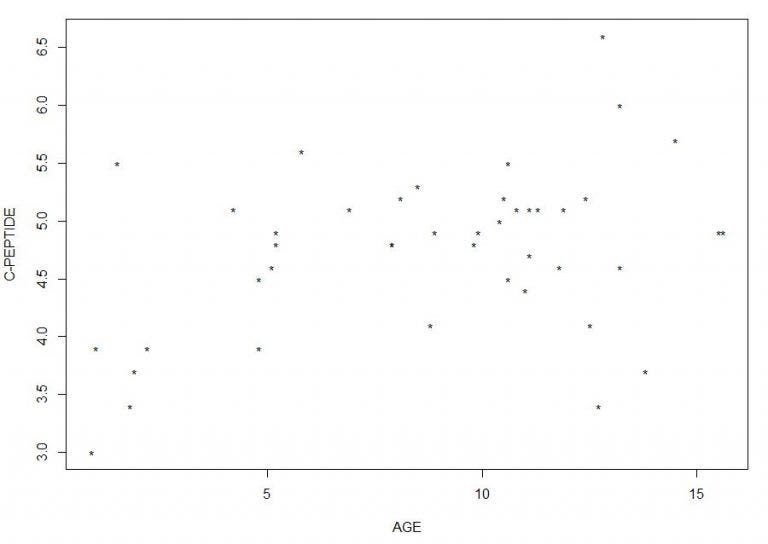
Sockett et al. (1987) сообщают данные, относящиеся к моделям остаточной секреции инсулина у детей в то время, когда им был поставлен диагноз диабета. Часть исследования была посвящена тому, можно ли использовать возраст для прогнозирования логарифма концентраций С-пептида при постановке диагноза:
age<-c(5.2,8.8,10.5,10.6,10.4,1.8,12.7,15.6,5.8,1.9,2.2,4.8,7.9,5.2,0.9, 11.8,7.9,1.5,10.6,8.5,11.1,12.8,11.3,1.0,14.5,11.9,8.1,13.8,15.5,9.8,11.0, 12.4,11.1,5.1,4.8,4.2,6.9,13.2,9.9,12.5,13.2,8.9,10.8) c_peptide<-c(4.8,4.1,5.2,5.5,5.0,3.4,3.4,4.9,5.6,3.7,3.9,4.5,4.8,4.9,3.0, 4.6,4.8,5.5,4.5,5.3,4.7,6.6,5.1,3.9,5.7,5.1,5.2,3.7,4.9,4.8,4.4,5.2,5.1,4.6, 3.9,5.1,5.1,6.0,4.9,4.1,4.6,4.9,5.1) plot(age,c_peptide,xlab = “AGE”,ylab = “C-PEPTIDE”, pch=”*”)
Теперь давайте посмотрим на взаимосвязь между переменными, применив функцию ядра эпанечникова:
kerreg(age,c_peptide,pch=”*”,expand = 0.5)
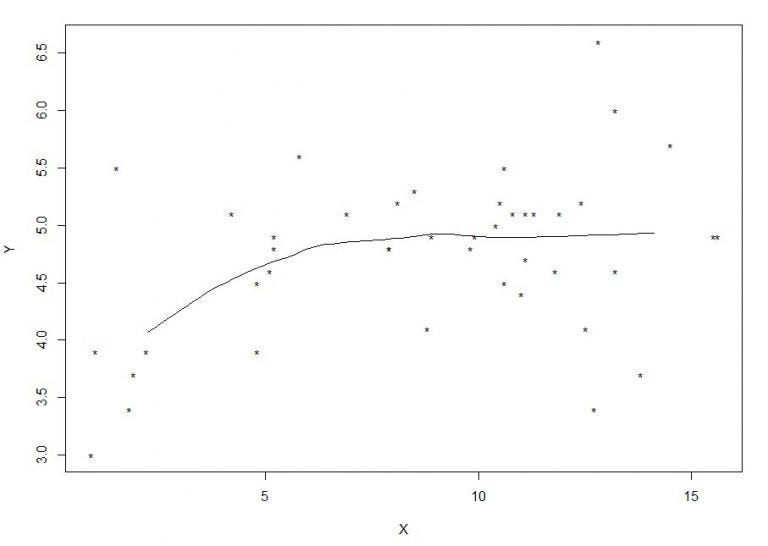
Таким образом, мы смоделировали взаимосвязь между переменными с помощью Kernel Smoothing. Параметр «развернуть» показывает полосу пропускания. Если мы интерпретируем этот график, можно сказать, что если возраст ниже 7 лет, существует положительная взаимосвязь между возрастом и уровнями c-пептида, а когда он выше 7, взаимосвязь отсутствует или небольшая.
2. Сглаживание диаграммы рассеяния с локальным взвешиванием (НИЗКОЕ)
Другой метод непараметрической регрессии - LOWESS. Этот метод также имеет пропускную способность, как сглаживание ядра. Однако здесь полоса пропускания называется «пролетом». Кроме того, оценки могут быть созданы путем определения степени методом LOWESS. Обычно он дает более надежные результаты, если рейтинг установлен на «2». Кроме того, отличие метода LOWESS от других методов непараметрической регрессии заключается в том, что он может работать с 4 независимыми переменными. Сделаем заявку по методу LOWESS. Опять таки; Мы можем изучить взаимосвязь между переменными «возраст» и «с-пептид». В R используется функция «лёсса»:
plot(age,c_peptide,xlab = “AGE”,ylab = “C-PEPTIDE”, pch=”*”) lo_mod<-loess(c_peptide~age,span=0.75,degree = 2) orderx<-order(age) lines(age[orderx],lo_mod$fitted[orderx])

Таким образом, мы смоделировали взаимосвязь между переменными, используя метод LOWESS. Интерпретация графика может быть произведена как в методе сглаживания ядра.
3. Более плавный интервал бега (RIS)
Метод RIS имеет дело с оценкой условной меры местоположения y, когда x известен. Для этой оценки используются надежные оценщики местоположения. Вы можете найти статью о надежных оценках местоположения, которую я написал, по ссылке ниже:
Кроме того, в методе RIS есть значение «диапазона», как в методе LOWESS. Это значение обычно дает лучшие результаты, если оно равно 0,8 или 1. В R функция «цепочки» может использоваться внутри пакета «WRS2».
Теперь давайте смоделируем взаимосвязь между переменными «возраст» и «с-пептид», используя оценку усеченного среднего RIS-метода:
rungen(age,c_peptide,est=tmean,fr=1,LP=FALSE,pch=”*”)
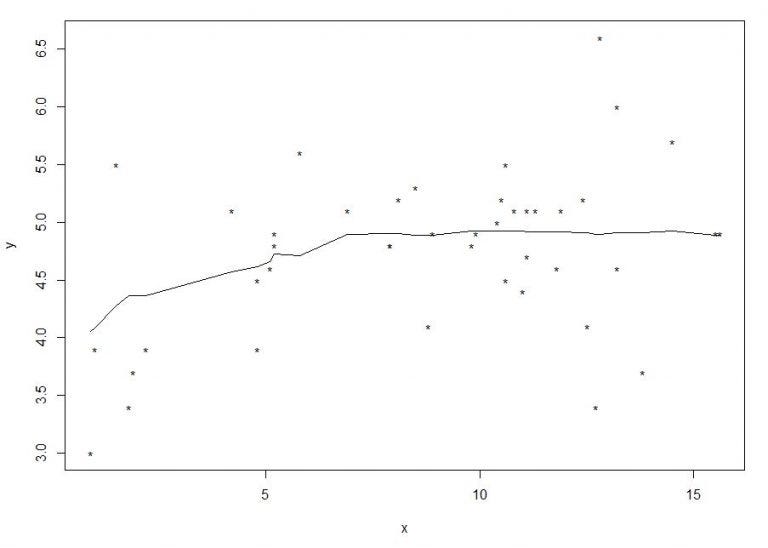
Оценка может быть определена с помощью параметра «est» в функции «rungen». Здесь «tmean» используется для усеченного среднего. Также значение диапазона (fr) определяется как 1. Глядя на этот график, можно сказать, что линия регрессии грубая. Поэтому в 2015 году Рэнд Уилкокс предложил альтернативный метод создания более плавной линии. Согласно альтернативному методу, он направлен на получение правильной линии регрессии с использованием метода RIS вместе с LOWESS. Для этого параметр «LP» в функции «rungen» должен быть определен как «ИСТИНА»:
rungen(age,c_peptide,est=tmean,fr=1,LP=TRUE,pch=”*”)
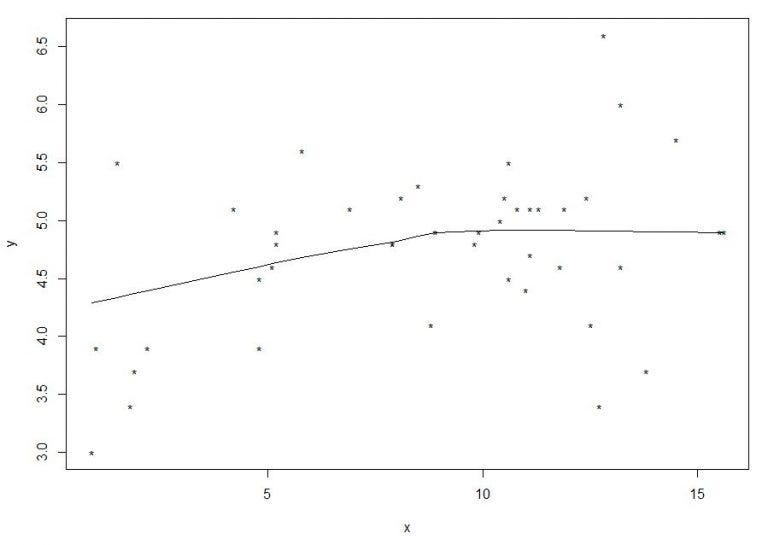
Как видно на рисунке, получается плавная линия регрессии. Если мы объясним этот график, его можно интерпретировать так, что, когда возраст ниже примерно 10, возрастает взаимосвязь между возрастом и c-пептидом, а если их больше 10, взаимосвязи нет.
Метод RIS также работает с разными значениями квартилей. Давайте смоделируем взаимосвязь между переменными, используя квартили 0,1, 0,5 и 0,9. Для этого можно использовать «квантильную» оценку:
r1<-rungen(age,c_peptide,est=quantile,fr=1,LP=TRUE,pch=”*”,prob=0.1,pyhat = T) r2<-rungen(age,c_peptide,est=quantile,fr=1,LP=TRUE,pch=”*”,prob=0.5,pyhat = T) r3<-rungen(age,c_peptide,est=quantile,fr=1,LP=TRUE,pch=”*”,prob=0.9,pyhat = T) plot(age,c_peptide,xlab = “AGE”,ylab = “C-PEPTIDE”, pch=”*”) orderx<-order(age) lines(age[orderx],r1$output) lines(age[orderx],r2$output) lines(age[orderx],r3$output)
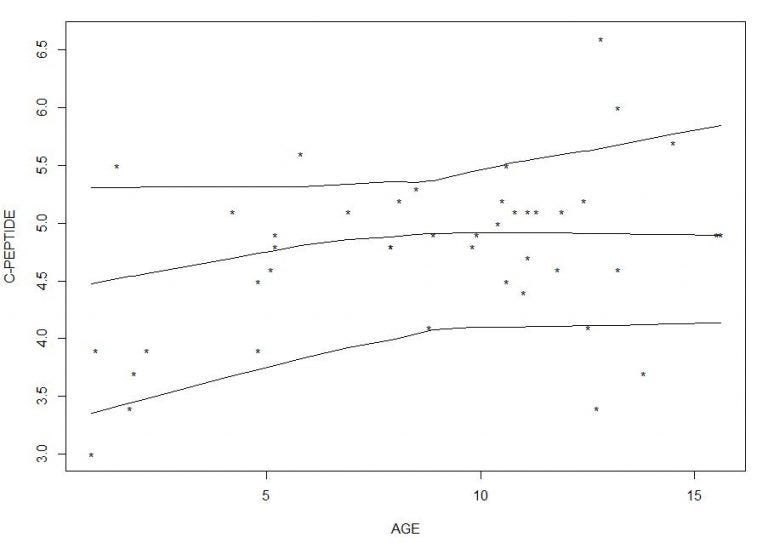
Таким образом, мы построили линии регрессии с 3 различными значениями квартилей. В то время как значение 0,1 кардил исследует нижнюю часть структуры данных, значение 0,9 квартиля исследует верхнюю часть структуры данных. Значение 0,5 квартиля указывает на медианное значение набора данных.
4. Сглаживание ограниченного B-сплайна (COBS)
Другой метод непараметрической регрессии - метод COBS. Метод COBS используется для оценки значения условного квартиля y, когда x известен. При проведении этой оценки используется «квантильная регрессия». Вы можете получить доступ к статье, которую я написал о квантильной регрессии, по ссылке ниже:
Этот метод также имеет пропускную способность, как и другие методы. Эта полоса пропускания упоминается здесь как значение «лямбда». Кроме того, он может работать с разными значениями квартилей. Для метода COBS функцию «cobs» можно использовать в пакете «cobs» в R. Давайте смоделируем взаимосвязь между переменными «age» и «c-пептид», используя метод COBS:
library(cobs) sbs1<-cobs(age,c_peptide,tau=0.1,lambda = 0) sbs2<-cobs(age,c_peptide,tau=0.5,lambda = 0) sbs3<-cobs(age,c_peptide,tau=0.9,lambda = 0) plot(age,c_peptide,xlab = “AGE”,ylab = “C-PEPTIDE”, pch=”*”) orderx<-order(age) lines(age[orderx],sbs1$fitted[orderx]) lines(age[orderx],sbs2$fitted[orderx]) lines(age[orderx],sbs3$fitted[orderx])

Значения квартилей можно определить с помощью параметра «tau» в функции «cobs». Таким образом, мы смоделировали взаимосвязь между переменными, используя метод COBS, используя различные значения квартилей (0,1, 0,5 и 0,9).
ЗАКЛЮЧЕНИЕ
Здесь мы сосредоточились на методах, которые следует использовать, когда связь между переменными не является параметрической. Увидимся в следующей статье ...
ИСПОЛЬЗОВАННАЯ ЛИТЕРАТУРА
- Дилбер Б. (2019). Методы робастной нелинейной регрессии. Докторская диссертация, Университет Докуз Эйлюль, Измир.
- Сокет, Э. Б., Данеман, Д. Кларсон, и К. Эрих, Р. М. (1987). Факторы, влияющие на остаточную секрецию инсулина в течение первого года развития сахарного диабета I типа (инсулинозависимого) у детей. Диабет, 30, 453–459.
- Тезкан, Н. (2009). Тахмин параметрик olmayan regresyon yöntemiyle yaklaşım. Докторская диссертация, Стамбульский университет, Стамбул.
- Уилкокс, Р. Р. (2012). Современная статистика для социальных и поведенческих наук. Лос-Анджелес: CRC Press.
- Уилкокс, Р. Р. (2016). Сравнение двух сглаживающих устройств квантильной регрессии. Журнал современных прикладных статистических методов, 5, 62–77.