Мы будем учиться вместо того, чтобы читать скучные определения✌Давайте начнем путешествие…
Для предсказания рукописной цифры мы будем использовать набор данных MNIST. Итак, прежде чем углубляться, давайте обсудим Keras и MNIST.
Так что же такое Керас??
Это не что иное, как нейросетевая библиотека Python для глубокого обучения.
Лучшее в ней — скорость, отсутствие нескольких строк кода, простота в использовании и написание на Python. Это высокоуровневый API и, следовательно, он не может работать с низкоуровневыми вычислениями, поэтому он передает их другой библиотеке, называемой серверной частью, не чем иным, как TensorFlow, Theano, CNTK.
Итак, Keras интегрирован в TensorFlow.
Это все еще сбивает с толку?? не волнуйтесь, имейте в виду, что это всего лишь популярная библиотека Python для обучения нейронных сетей, популярная благодаря своей скорости и удобству для начинающих.
Если вы, ребята, уже знаете о Keras и путаетесь с Keras Vs TensorFlow или хотите узнать больше, прочитайте абзац ниже или просто пропустите его!
Tensorflow – это платформа глубокого обучения, разработанная Google для выполнения нескольких задач машинного обучения.
Она лучше всего подходит для работы с большими данными (как высокоуровневыми, так и низкоуровневыми API) и, следовательно, сложнее, чем Keras.
Исследователи обращаются к TensorFlow при работе с большими наборами данных и обнаружении объектов и когда им нужна отличная функциональность и высокая производительность. Keras предназначен для глубоких нейронных сетей, а TensorFlow — для приложений машинного обучения. Мы должны выбрать структуру в зависимости от задачи, которую мы собираемся выполнить.
Надеюсь, вы понимаете, что такое Керас. Хорошо, теперь что такое MNIST??
Итак, для нашего проекта мы собираемся использовать набор данных MNIST (модифицированный набор данных Национального института стандартов и технологий). Значит ли это, что MNIST — это набор данных? нет, это не так. На самом деле это группа людей, которые разработали множество наборов данных. Они разработали множество наборов данных, таких как мода MNIST, язык жестов MNIST и так далее.

Итак, для нашего проекта мы будем использовать «набор данных рукописных цифр MNIST». Это набор данных из 60 000 небольших квадратных изображений 28 × 28 (784) пикселей в градациях серого с рукописными одиночными цифрами от 0 до 9 для обучения и 10 000 изображений для тестирования.

Хорошо, давайте перейдем к следующему шагу…
Теперь мы собираемся импортировать необходимые библиотеки для нашего проекта…
››импортировать keras
››из keras.datasets import mnist
››из keras.layers импортировать Dense
››из keras.optimizers импортировать SGD
››из keras.models импорт последовательный
Итак, вы видите, что мы импортируем наборы данных Keras и mnist, но что это за слои? оптимизаторы? а модели??
Модель Keras — это не что иное, как фактическая модель нейронной сети, и keras предоставляет два режима для создания модели. Так что это??
- простой, удобный и гибкий последовательный API
- расширенный функциональный API
Итак, в нашем проекте мы будем использовать Sequential API.
Прежде чем углубляться, давайте обсудим слои!!
В нейронной сети у нас будет входной и выходной слой, а также у нас может быть несколько скрытых слоев.
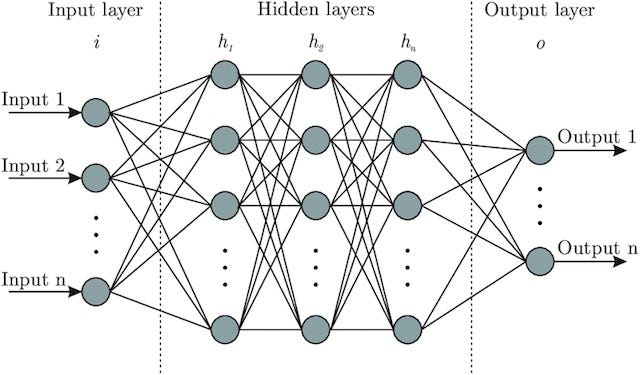
Нейронная сеть должна иметь только один входной слой (но может иметь несколько входов во входном слое). Он принимает и обрабатывает входные данные, а затем передает выходные данные на последующий слой только в скрытый слой.
Так что же будет делать скрытый слой??
Скрытый слой берет выходные данные из входного слоя и создает новые полезные или необходимые функции для нашей классификации. В нашем проекте скрытый слой может выглядеть так:
Нейронная сеть – это набор нейронов, организованных слоями.
1-й нейрон в скрытом слое активируется, если там есть круглая форма
2-й нейрон в скрытом слое активируется, если там есть горизонтальная линия
3-й нейрон в скрытом слое активируется, если там есть вертикальная линия
4-й Нейрон в скрытом слое активируется, если там есть наклонная линия
то же самое происходит и с другими нейронами.
Можно сказать, что они обнаруживают подкомпоненты рукописных цифр.
Теперь на основе этих функций внешний слой делает прогнозы, например.
Если вы пройдете девять,
чем нейрон, обнаруживающий круглую форму, и нейрон, обнаруживающий вертикальную линию, активируются в скрытом слое, и это приведет к активации выходного нейрона, обнаруживающего девять.
Если вы пройдете семь,
чем нейрон, обнаруживающий наклонную линию, и нейрон, обнаруживающий горизонтальную линию, активируются в скрытом слое, и это приведет к активации выходного нейрона, обнаруживающего семь.
Наконец, мы получаем фактический вывод нашей программы из выходного слоя.
Теперь давайте обсудим, что такое последовательный API, как видно из самого названия, он упорядочивает слои Keras в последовательном порядке. Данные передаются от одного уровня к другому в заданном порядке, пока данные, наконец, не достигнут выходного уровня.
Последовательный API позволяет создавать модели слой за слоем для большинства задач. Он ограничен тем, что не позволяет создавать модели с общими слоями или с несколькими входами и выходами.
Функциональный API позволяет создавать модели с гораздо большей гибкостью, поскольку вы можете легко определять модели, в которых слои соединяются не только с предыдущим и следующим слоями. На самом деле, вы можете соединить слои (буквально) с любым другим слоем. В результате становится возможным создание сложных сетей, таких как сиамские сети и остаточные сети.
Итак, если вам нужна гибкость и глубокий доступ к каждому нейрону, вы должны выбрать функциональный API.
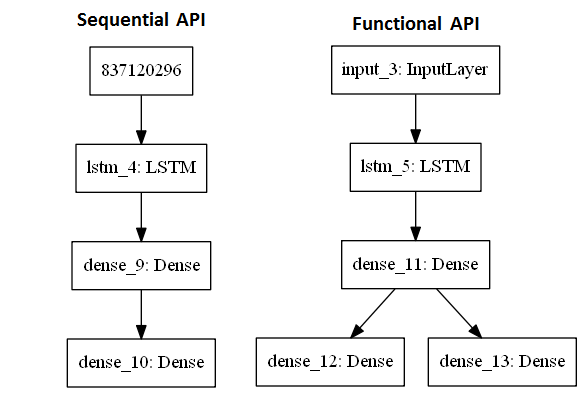
Не запутайтесь на картинке выше, просто посмотрите на архитектуру.
Итак, наконец, что такое Оптимизатор?
Прежде чем углубляться в это, мы должны знать о функции веса и потери. Итак, что это??
Я не собираюсь подробно объяснять вес, просто посмотрите на картинку ниже, и вы это поймете.
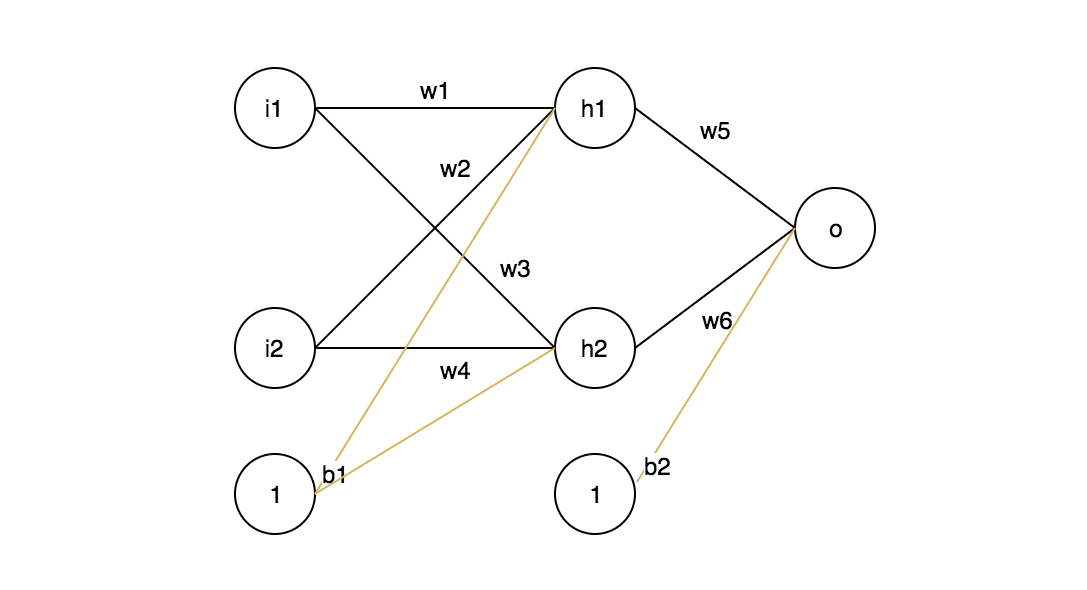

Таким образом, вес — это модель параметров, которая преобразует входные данные в скрытых слоях сети.
Что такое функция потерь?
Это метод оценки того, насколько хорошо ваш алгоритм моделирует набор данных. Если ваши прогнозы полностью ошибочны, ваша функция потерь выдаст более высокое число. Если они довольно хороши, он выведет меньшее число. Простой не так ли?
Хорошо, давайте перейдем к следующему шагу… Что такое оптимизатор??
В процессе обучения мы меняем веса, чтобы минимизировать функцию потерь и максимально точно предсказать правильный результат. Итак, здесь мы будем иметь дело с оптимизатором, он обновляет модель в ответ на вывод функции потерь.
В нашем проекте мы будем использовать SGD (стохастический градиентный спуск) для оптимизации. Проще говоря, SGD — это не что иное, как определение того, как мы меняем вес (параметры), чтобы мы могли получить наилучший результат из заданного ввода.
Если каждый нейрон слоя связан, то этот слой называется плотным слоем.
Каждый нейрон в слое получает входные данные от всех нейронов, присутствующих в предыдущем слое, поэтому они плотно связаны.
Другими словами, плотный слой — это полностью связанный слой, то есть все нейроны в слое связаны с нейронами в следующем слое.
Переходя к следующей части, мы назначим некоторые значения.
››num_classes = 10
››batch_size = 128
››epochs = 20
num_classes: он просто присваивает каждый номер в каждом классе. Например, класс 1→ цифра 0, класс 2→ цифра 1, класс 3→ цифра 2,……… и класс 10 → цифра 9.
Итак, у нас есть 10 классов от 1 до 10 для чисел от 0 до 9.
эпоха: эпоха — это не что иное, как количество прохождений всего обучающего набора данных через всю нейронную сеть.
batch_size: мы не можем передавать весь набор данных за раз через сеть, поэтому мы собираемся разделить его на несколько пакетов, а batch_size — это не что иное, как количество пакетов в эпоху.
В нашем наборе данных у нас 60000 значений, и мы присвоили 128 batch_size… Итак, 60000 разделить на 128 — это количество итераций в одной эпохе.
Итак, как выбрать значение эпохи??? Это полностью зависит от вашей модели и размера набора данных.
Допустим, если у вас наилучшая оптимальная точность при 30 эпохах, точность останется прежней, даже если для эпохи установлено значение 100.
››(x_train, y_train), (x_test, y_test) = mnist.load_data()
В приведенном выше коде mnist.load_data() загружает набор данных в четыре переменные, а именно: x_train, y_train, x_test и y_test.
››print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
Он печатает текущую форму массива набора данных.
Вывод будет таким → (60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
В приведенном выше выводе (60000,28,28) это означает набор обучающих данных 60000 и 28 x 28 (ширина и высота), что составляет 784 пикселя. Точно так же (10000,28,28) здесь 10000 тестовых наборов данных.
››x_train = x_train.reshape(60000, 784) # 28x28 = 784(одна матрица)
››x_test = x_test.reshape(10000, 784)
На предыдущем шаге мы изменяем наши данные, чтобы они имели 784 пикселя.
››x_train = x_train.astype(‘float32’)
››x_test = x_test.astype(‘float32’)
На предыдущем шаге мы преобразовываем данные в тип float32.
››x_train /= 255 # 0–255 … 0–1
››x_test /= 255 # нормализуем наши данные
у нас есть цветной ввод 256 в диапазоне от 0 до 255. Машине будет легко обучаться только между значениями 0–1, чем значениями 256… Вот почему мы нормализуем наши данные.
››print(x_train.shape[0], ‘образцы поездов’) #output -60000 образцов поездов
››print(x_test.shape[0], ‘тестовые образцы’) #output -10000 тестовых образцов
››print(x_train.shape) #output -(60000,784)
››print(y_train.shape) #output-(60000, )
››y_train[0] # вывод-5
Эй, прежде чем перейти к следующему шагу, давайте узнаем об одном горячем векторном кодировании.
Горячее кодирование представляет собой представление категориальных переменных в виде двоичных векторов.
Например, если у нас есть целое число 5, оно будет представлено как 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.
Значение других чисел, кроме 5, равно 0, но для 5 это 1.
Это делается,
››y_train = keras.utils.to_categorical(y_train, num_classes)
››y_test = keras.utils.to_categorical(y_test, num_classes)
Мы уже обсуждали последовательный API, поэтому мы установим модель как последовательную модель.
››модель = последовательный()
Теперь мы добавим слои в нашу модель с помощью функции add()…
››model.add( Dense(512, активация='сигмоид', input_shape=(784,)) )
››model.add( Dense(512, активация='сигмоид' ) )
› ›model.add( Dense(num_classes, активация='softmax')) #это последний выходной слой
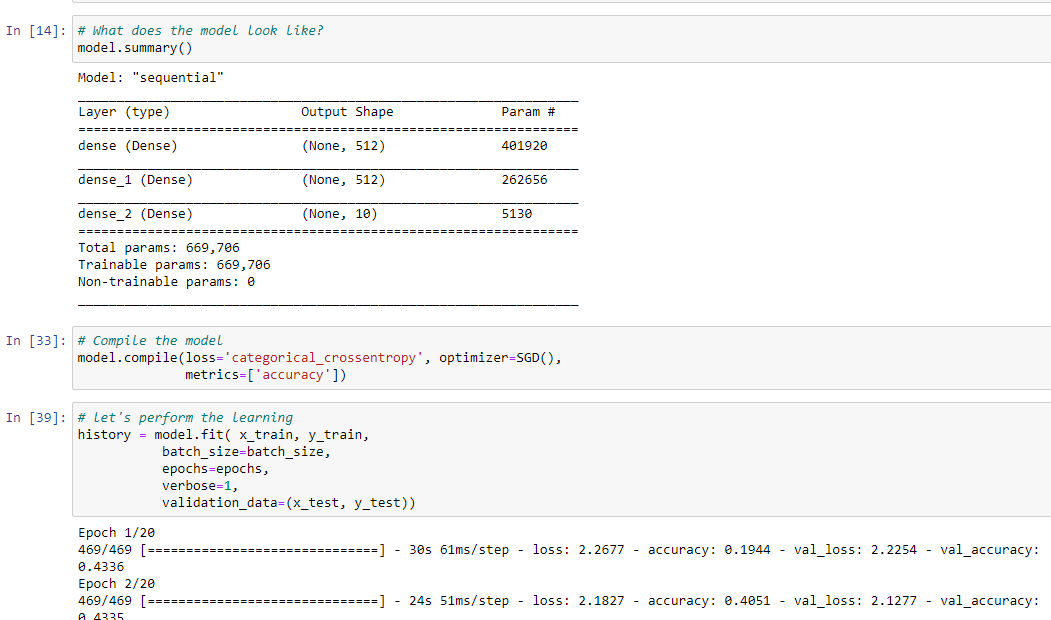
Тогда давайте посмотрим на нашу модель… Как она выглядит?
››model.summary()
Вывод будет таким 👇

Итак, у нас есть три плотных слоя. В первом и втором слоях у нас есть 512 нейронов (узлов), и ни один из них не предназначен для того, чтобы мы могли передать ему любое количество точек данных. Таким образом, очевидно, что в последнем слое будет 10 нейронов, так как это выходной слой.
Общее количество параметров для всей сети составляет 669 706.
На следующем шаге мы собираемся скомпилировать модель. Нам нужна скомпилированная модель для обучения (обучение использует функцию потерь и оптимизатор).
››model.compile(потеря=’categorical_crossentropy’, оптимизатор=SGD(),
metrics=[‘точность’])
Теперь займемся нашей моделью.
››history = model.fit( x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
данные проверки - это не что иное, как тестовые данные (x_test, y_test)
Вы думаете о многословном ?? Мы собираемся увидеть процесс обучения для каждой эпохи, установив подробное значение.
По умолчанию подробный = 1,
verbose = 1, который включает в себя как индикатор выполнения, так и одну строку на эпоху
verbose = 0, означает молчание
verbose = 2, одна строка на эпоху, т.е. номер эпохи/общее количество. эпох
Попробуйте изменить значение эпохи и посмотрите, что произойдет… обратите внимание на точность каждого шага.
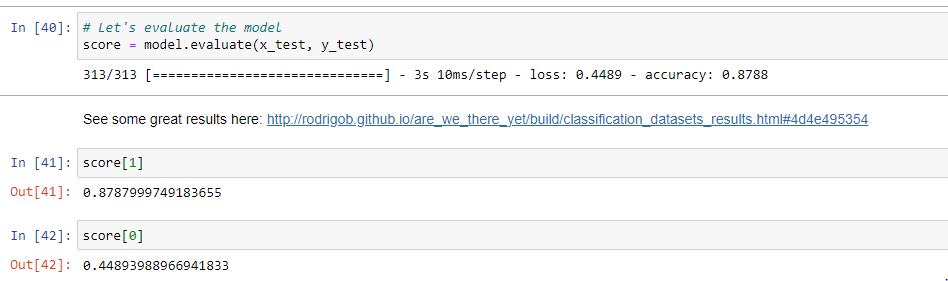
Давайте, наконец, оценим модель..!
››score = model.evaluate(x_test, y_test)
››score[0] # чтобы получить значение проигрыша
››score[1] #чтобы получить точность
Давайте взглянем на весь код…!