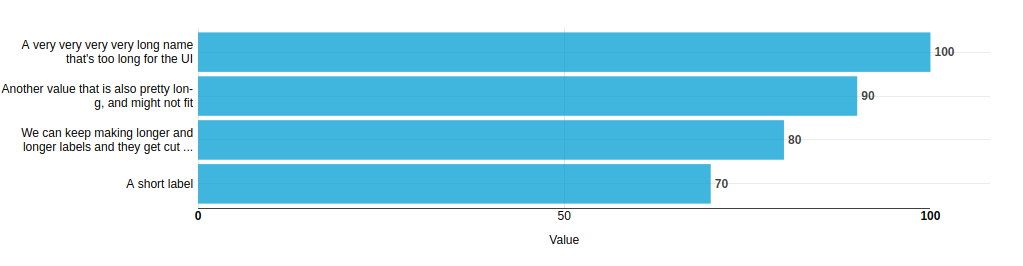
Если метки вашей горизонтальной гистограммы слишком длинные для вашего левого поля, по умолчанию в NVD3 метки просто переполняют пространство и исчезают слева, что раздражает и выглядит непрофессионально. На этих диаграммах пространство для меток вертикальной оси крайне ограничено, поэтому для хорошей работы недостаточно реализовать перенос на уровне слов, нам нужно включить перенос через дефис и усечение метки.
Одна из причин, по которой пространство для этих меток может быть ограничено, - это соблазн сделать ваши горизонтальные полосы вокруг одной высоты текстовой строки. В этом случае упаковка этикеток вас не спасет (хотя усечение может). Я бы порекомендовал при работе с данными, имеющими длинные метки, которые вы также рассматриваете, увеличивая толщину полосы для размещения, с бонусом, который, как мне кажется, делает диаграммы более красивыми и удобными для пользователя.
В этом сообщении описывается алгоритм, который можно использовать с NVD3 и, действительно, с любым дисплеем на основе SVG, чтобы взять длинную строку, обернуть ее (используя дефисы, если необходимо) и усечь ее, когда пространство закончится.
(Обратите внимание, что Майк Босток предлагает решение для этого, хотя оно выполняется на уровне слов и не усекается; приведенный ниже алгоритм использует аналогичные концепции и расширяется. В NVD3 также есть опция wrapLabels:true на дискретной гистограмме (которая Я предполагаю, что использует решение Майка), но это недоступно на горизонтальной многополосной панели)
Метод
Прежде чем мы перейдем к коду, давайте рассмотрим общий подход, который мы собираемся использовать.
Мы можем думать о проблеме с точки зрения размещения максимального количества текста в поле с определенной шириной и высотой. Точное количество текста, которое поместится в этом поле, будет зависеть от размера текста, высоты строки и - если используется шрифт переменной ширины - от того, какие именно буквы задействованы.
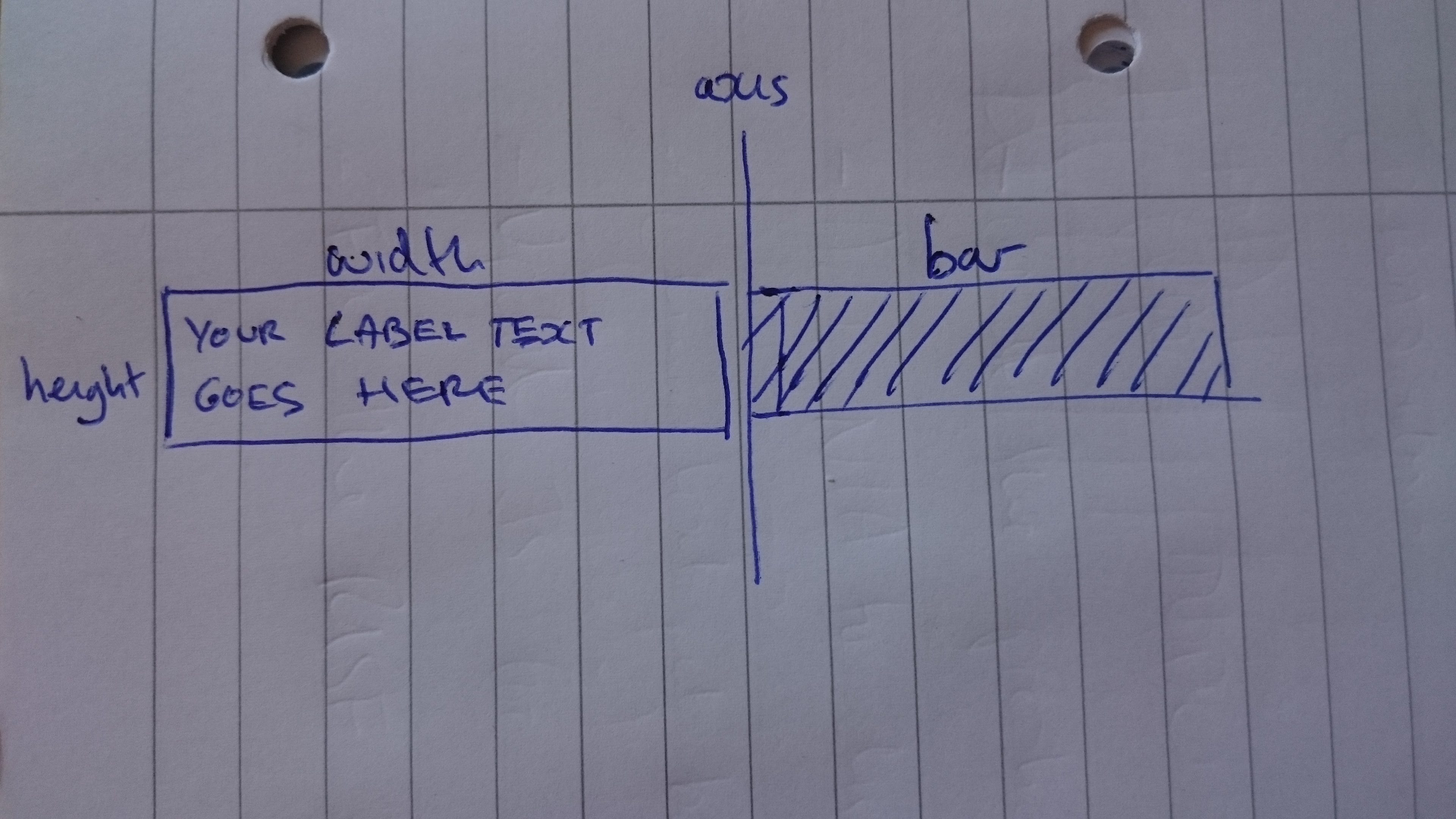
Мы можем решить проблему, атакуя горизонталь и вертикаль по отдельности:
Сначала разделите текст на строки, которые по горизонтали умещаются в доступном пространстве. Во-вторых, распределите текст по вертикали (то есть разместите все строки последовательно одна над другой) и определите, помещаются ли они в поле. Наконец, уменьшите количество текстовых строк до тех пор, пока они не уместятся в поле.
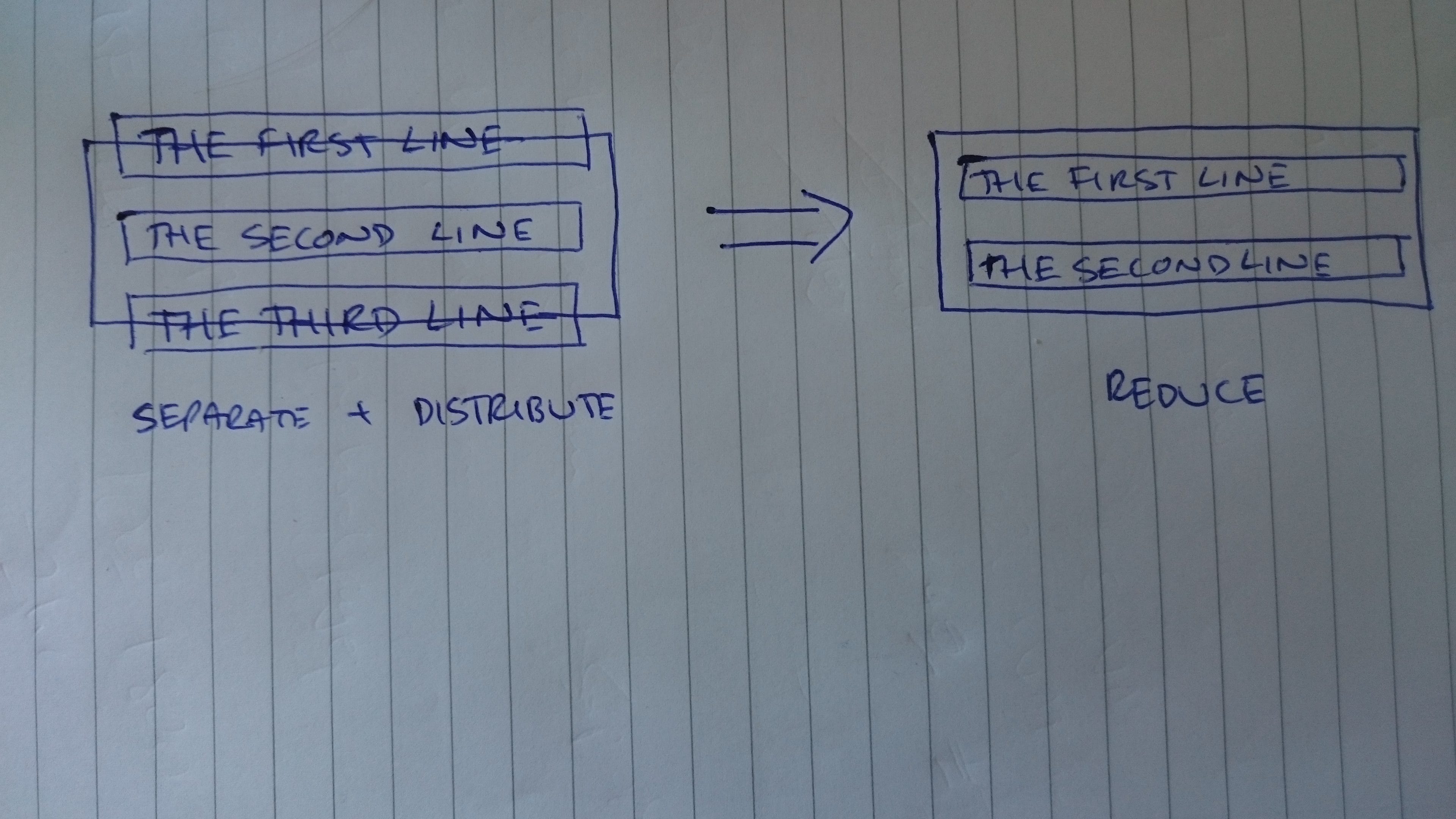
Одна из ключевых деталей, которые мы хотим включить, чтобы максимально использовать небольшой объем доступного места, - это перенос слов там, где это возможно. К сожалению, расстановка переносов не всегда выглядит правильно - например, вы не хотите делать это после первых букв или двух слов. Кроме того, расстановка переносов вводит в текст новый символ, который затем необходимо учитывать при расчете ширины, поэтому вы не можете просто поставить дефис в конце строки, который разрывает слово.
Вот блок-схема, которая определяет работоспособное правило максимизации горизонтального пространства для расстановки переносов:
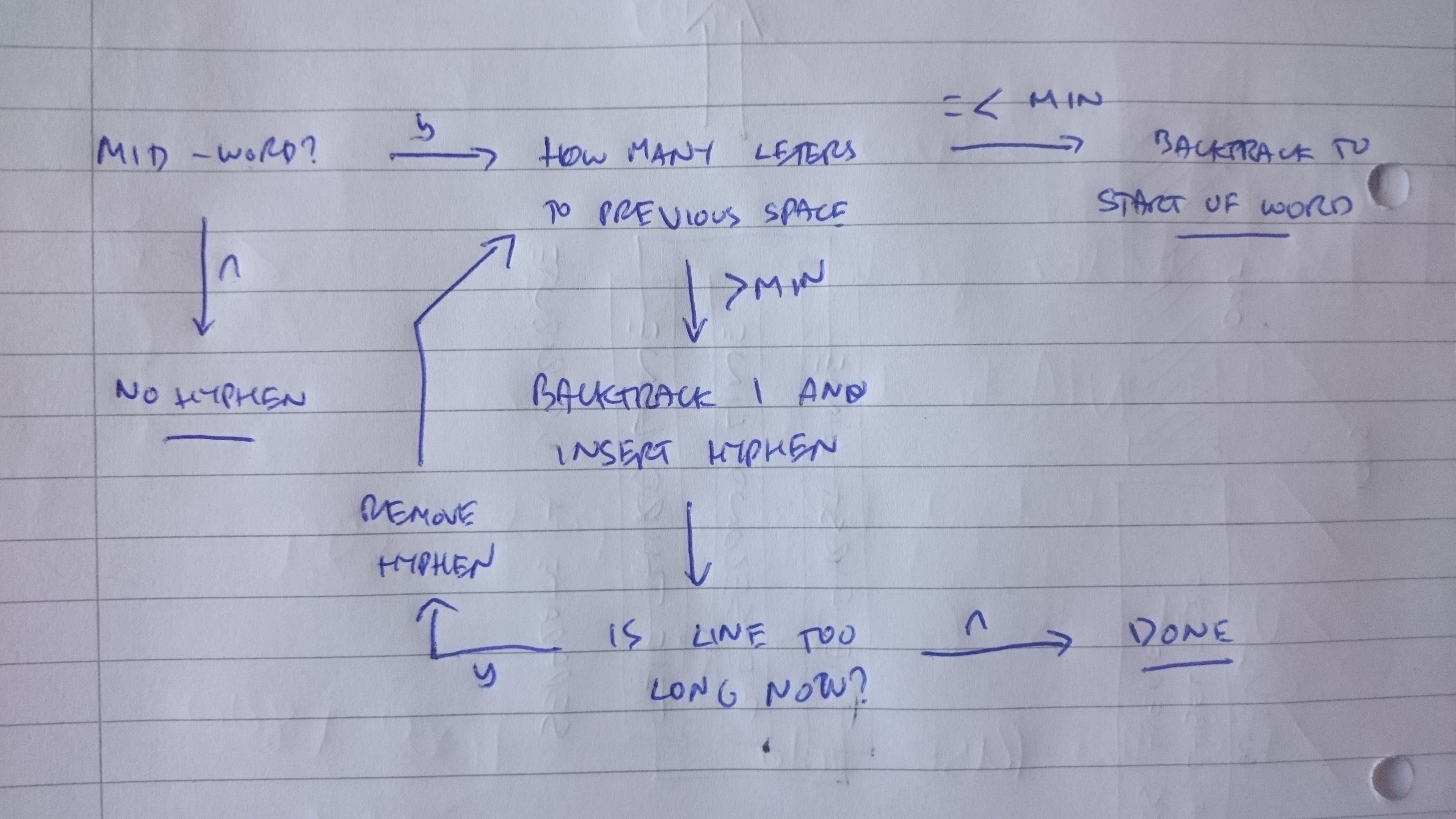
Это работает так: в конце нашего горизонтального пространства, если мы оказываемся в середине слова, узнаем, сколько букв оно вернулось к предыдущему разрыву слова. Если расстояние до разрыва слова меньше некоторого минимального предела, мы не пытаемся переносить перенос, мы просто возвращаемся к началу слова и прерываем его. Это мешает нам делать такие вещи, как «м-е» или «йо-у», что выглядело бы странно. Мы установим наш минимум примерно на 3.
Если, с другой стороны, расстояние до разрыва слова больше этого минимума, то мы должны попытаться расставить дефис. Мы делаем это, возвращаясь к одной букве и добавляя дефис. Теперь нам нужно проверить, подходит ли линия по-прежнему по горизонтали, если дефис шире, чем буква, которую он заменяет.
Если линия подходит, отлично, мы сделали! В противном случае мы удаляем дефис и продолжаем переход с возвратом + перенос дефиса до тех пор, пока строка не уместится в отведенном месте. Если мы дойдем до точки, когда количество букв, оставшихся в начале слова, станет ниже нашего минимума, мы просто обернем строку на границе слова.
Этот алгоритм представляет собой простейшую стратегию расстановки переносов, которую я обнаружил, которая дает разумные результаты для сильно ограниченных пространств. На самом деле расстановка переносов сложна, и при наборе текста есть даже правила о том, где разделять разные типы слов (например, по границам слогов), которые для нас слишком сложны. Кроме того, наш алгоритм учитывает только то, правильно ли выглядит начало слова, и не заботится о конце слова. Итак, мы можем видеть обертки вроде «lon-g» или «joi-n», которые начинаются хорошо, но заканчиваются странно. Мы пока не будем обращать на это внимание, так как исправление этого может сделать использование горизонтального пространства менее эффективным.
Код
Полную функцию для этого можно найти внизу этого сообщения. Мы рассмотрим важные моменты, чтобы вы увидели, как это работает.
Мы собираемся сделать это как одну функцию с другими функциями, определенными внутри нее. Мы передадим набор параметров, которые будут определять среду (закрытие).
function wrapLabels(params) {
var axisSelector = params.axisSelector;
var maxWidth = params.maxWidth;
var maxHeight = params.maxHeight;
var lineHeight = params.lineHeight || 1.2;
var wordBreaks = params.wordBreaks || [" ", "\t"];
var minChunkSize = params.minChunkSize || 3;
// implementation goes here
}
- axisSelector - строка селектора, которая может использоваться d3 для выбора оси, метки которой мы собираемся перенести.
- maxWidth - максимальная ширина поля, в которое должен уместиться текст. Это, вероятно, равно левому полю, которое вы даете столбчатой диаграмме.
- maxHeight - максимальная высота поля, в которое должен уместиться текст. Это, вероятно, равно толщине стержня.
- lineHeight - высота строки, которую вы хотите использовать, которая определяет необходимое разделение между строками текста.
- wordBreaks - список символов, которые вы считаете точками разрыва между словами. По умолчанию мы используем пробел и табуляцию.
- minChunkSize - минимальное количество букв перед дефисом при разрыве слова.
После того, как мы нарисовали нашу диаграмму с помощью NVD3 обычным способом, мы применяем упаковку как модификацию пост-рендеринга. Для этого нам нужно захватить каждую метку оси и выполнить на ней преобразование. Мы разберем алгоритм точно так же, как описано выше: разделить, распределить, уменьшить:
d3.selectAll(axisSelector + " .tick text").each(function(i, e) {
var text = d3.select(this);
var tspans = separate(text);
do {
distribute(text, tspans);
}
while (reduce(text, tspans))
});
Мы берем текст для каждой метки и используем нашу отдельную функцию, чтобы преобразовать его в список tspan объектов. Затем мы распределяем эти tspans по вертикали и затем применяем функцию reduce, которая возвращает true, если мы уменьшили текст, или false, если текст теперь умещается.
Отдельный
Разделение текста - наиболее сложная функция, поскольку предполагает расстановку переносов.
Мы определяем функцию, которая принимает узел text метки оси:
function separate(text) { ... }
Сначала мы берем текстовое содержимое как массив символов, затем заменяем текстовое содержимое на tspan, которое мы можем использовать для проверки ширины текста:
var chars = text.text().trim().split("");
text.text(null);
var x = text.attr("x");
var tspan = text.append("tspan").attr("x", x).attr("y", 0);
Теперь мы перебираем этот chars массив, наращивая каждую строку, пока она не заполнится, и применяем наш алгоритм расстановки переносов:
var lines = [];
var currentLine = [];
while (chars.length > 0) {
var char = chars.shift();
...
}
Мы создали два реестра: один для записи списка lines, а другой - для записи хода выполнения currentLine. Затем мы выполняем цикл до тех пор, пока массив chars не станет пустым. Мы не можем использовать для каждого через массив chars, потому что мы собираемся отслеживать вперед и назад в этом массиве, поэтому мы не обязательно будем использовать только один символ на итерацию. Затем наше первое действие - shift первый символ в начале массива.
Следующий шаг прост: просто добавьте первый char к currentLine и поместите currentLine в tspan:
currentLine.push(char);
tspan.text(currentLine.join(""));
Теперь мы проверяем, подходит ли строка, а если нет, то подгоняем ее и обрабатываем перенос. Мы рассмотрим все это целиком, а затем обсудим это ниже:
var maxed = false;
var hyphenated = false;
while(_isTooLong(tspan)) {
maxed = true;
if (hyphenated) {
currentLine.splice(currentLine.length - 1);
hyphenated = false;
}
_backtrack(1, currentLine, chars);
if (_isMidWord(currentLine, chars)) {
var toPrevSpace = _toPrevSpace(currentLine);
if (toPrevSpace === -1 || toPrevSpace - 1 > minChunkSize) {
_backtrack(1, currentLine, chars);
currentLine.push("-");
hyphenated = true;
} else {
_backtrack(toPrevSpace, currentLine, chars);
}
}
currentLine = currentLine.join("").trim().split("");
tspan.text(currentLine.join(""));
}
Начнем с вопроса: не слишком ли длинная эта строка? Если это не так, никакой из этого кода не выполняется, и массив chars продолжает использоваться до тех пор, пока строка не станет слишком длинной.
Если пока игнорировать maxed и hyphenated, следующее, что происходит, - это мы возвращаемся назад на 1 символ. Это удалит последний символ из currentLine и поместит его обратно в chars.
Теперь зададим другой вопрос: мы на середине слова? В противном случае обновляются currentLine и tspan (в последних двух строках цикла), а затем цикл завершается на следующей итерации, поскольку строка больше не будет слишком длинной. Если бы мы не хотели переносить символы через дефис, этого было бы достаточно - мы бы максимально заполнили строку символами из нашего массива chars.
Если мы находимся в середине слова, то применим наш алгоритм расстановки переносов: сначала определите, как далеко он находится от предыдущего пробела. Это может быть -1, если мы дойдем до начала текста до того, как найдем пробел, или какое-то число, если мы найдем пробел.
Если это число меньше нашего minChunkSize, мы не будем переносить дефис (в противном случае мы получили бы текст вроде «m-e»), поэтому мы возвращаемся к началу слова и заканчиваем на нем.
В противном случае мы возвращаемся назад на 1 символ, вставляем «-» и продолжаем, и обратите внимание, что мы установили путевой провод hyphenated на true. Это вступает в игру на следующей итерации цикла. Если мы начинаем цикл с hyphenated, установленным на true, то первое, что мы делаем, это удаляем последний символ (дефис) перед тем, как продолжить. Это связано с возможностью того, что дефис шире, чем символ, который он заменяет, и позволяет нам возвращать столько букв, сколько нам нужно, чтобы строка поместилась в tspan.
Это полностью реализует наш алгоритм расстановки переносов, описанный выше. Я не буду вдаваться в подробности о других функциях, используемых здесь, за исключением _isTooLong, поскольку он содержит ключевую деталь о том, как выполняется проверка ширины. Вот функция:
function _isTooLong(tspan) {
return tspan.node().getComputedTextLength() >= maxWidth
}
Он использует getComputedTextLength на tspan узле и определяет, является ли он шире некоторого указанного (в данном случае в закрытии) maxWidth. Таким образом мы должны определить, выходит ли текст за пределы пространства, поскольку мы можем вычислить только ширину элемента DOM, мы не можем вычислить ширину текста до того, как он войдет в DOM.
Завершаем цикл над массивом chars некоторыми условиями завершения:
if (!maxed && chars.length > 0) {
continue;
}
if (maxed || chars.length === 0) {
lines.push(currentLine);
currentLine = [];
}
Если мы еще не исчерпали линию, а еще есть персонажи, которые нужно поглотить, продолжайте. Если мы исчерпали весь массив или не осталось символов для использования, запишите currentLine в список lines и сбросьте currentLine на пустой, готовый к заполнению следующей строкой символов.
Теперь мы выходим из цикла while по массиву chars и создаем полный список tspans, чтобы вернуть его вызывающему.
while (chars.length > 0) {
var char = chars.shift();
// see above for detail...
}
tspan.remove();
var tspans = [];
for (var i = 0; i < lines.length; i++) {
tspan = text.append("tspan").attr("x", x).attr("y", 0);
tspan.text(lines[i].join(""));
tspans.push(tspan);
}
return tspans;
Обратите внимание, что мы удаляем исходный tspan, который мы создали здесь - мы использовали этот элемент только для измерения ширины текста, поэтому мы очищаем его и начинаем заново, когда у нас есть наш список строк.
Распространять
Теперь у нас есть набор из tspan элементов, содержащих текст, который по горизонтали помещается в предоставленное пространство, и мы можем подумать, подходит ли текст по вертикали.
Наша отдельная функция выравнивает созданный tspans с исходной позицией x заменяемого text, но оставляет y равным 0, что означает, что все элементы располагаются друг над другом. Функция distribute исправляет это, располагая линии вертикально, при этом центр группы центрируется в доступном пространстве (которое, в свою очередь, центрирует ее относительно полосы на диаграмме).
function distribute(text, tspans) {
var pmax = lineHeight * (tspans.length - 1);
var dy = parseFloat(text.attr("dy"));
for (var j = 0; j < tspans.length; j++) {
var pos = (lineHeight * j) - (pmax / 2.0) + dy;
var tspan = tspans[j];
tspan.attr("dy", pos + "em");
}
}
Мы начинаем с определения максимальной высоты набора элементов (pmax) при их распределении и получения dy атрибута исходного текста - это говорит нам, какое исходное смещение NVD3 использовало для центрирования строки текста с полосой. Это будет что-то вроде 0,32em.
Затем мы просто вычисляем dy позицию каждого tspan по простой формуле:
var pos = (lineHeight * j) - (pmax / 2.0) + dy;
- Высота строки, умноженная на число
tspan, сообщает нам необработанное смещение от вершины набораtspans, к которому мы хотим переместиться. - Максимальная высота блока, превышающая 2, говорит нам, как далеко назад нужно сдвинуть текст, чтобы он находился в правильном относительном положении по отношению к полосе.
- Добавление
dyвосстанавливает исходное смещение элементаtextдля выравнивания центра текста с центром полосы
Как только это pos известно, мы просто устанавливаем dy из tspan соответствующим образом.
Уменьшать
Имея набор tspans, которые помещаются по горизонтали и распределяются по вертикали, мы теперь можем окончательно определить, помещаются ли они в коробку.
Наша функция сокращения смотрит на используемое пространство по сравнению с выделенным пространством и удаляет последний элемент, если есть переполнение. В качестве бонуса он также заменяет последние буквы предыдущей строки эллипсами для обозначения усечения.
function reduce(text, tspans) {
var reduced = false;
var box = text.node().getBBox();
if (box.height > maxHeight && tspans.length > 1) {
tspans[tspans.length - 1].remove();
tspans.pop();
var line = tspans[tspans.length - 1].text();
if (line.length > 3) {
line = line.substring(0, line.length - 3) + "...";
}
tspans[tspans.length - 1].text(line);
reduced = true;
}
return reduced;
}
Здесь используется функция getBBox или getBoundingBox, которая сообщает нам ширину, высоту и положение элемента. Если высота блока превышает некоторую максимальную высоту, и еще tspans осталось удалить, мы просто удаляем последний из DOM и из списка в памяти. Затем мы удаляем последние 3 буквы последней строки и заменяем их эллипсами, обновляем пользовательский интерфейс новым текстом, затем возвращаем true. Если никакие элементы не были удалены, мы возвращаем false, и именно это делает эту функцию подходящей для цикла do ... while, который мы ввели в начале.
Собираем все вместе
Мы собираем весь код в одну функцию, которая сама содержит другие функции, которые мы определили, что дает нам хорошее завершение:
function wrapLabels(params) {
var axisSelector = params.axisSelector;
var maxWidth = params.maxWidth;
var maxHeight = params.maxHeight;
var lineHeight = params.lineHeight || 1.2;
var wordBreaks = params.wordBreaks || [" ", "\t"];
var minChunkSize = params.minChunkSize || 3;
function _isMidWord(currentLine, remainder) {...}
function _toPrevSpace(currentLine) {...}
function _backtrack(count, currentLine, remainder) {...}
function _isTooLong(tspan) {...}
function separate(text) {...}
function distribute(text, tspans) {...}
function reduce(text, tspans) {...}
d3.selectAll(axisSelector + " .tick text").each(function(i, e) {
var text = d3.select(this);
var tspans = separate(text);
do {
distribute(text, tspans);
}
while (reduce(text, tspans))
});
}
Затем все, что нам нужно сделать, это вызывать эту функцию каждый раз при обновлении диаграммы (и не забывать вызывать ее при первой визуализации диаграммы):
function updateChart() {
chart.update();
edges.nvd3.tools.wrapLabels({
axisSelector: "#mychart .nv-x.nv-axis",
maxWidth: 200, // the left margin
maxHeight: 40 // the bar height
});
}
updateChart();
nv.utils.windowResize(updateChart);
Единственный важный момент здесь - это понять, как правильно выбирать оси. На горизонтальной мультибаре это .nv-x.nv-axis, и мы локализуем его на #mychart, чтобы не применять перенос ко всем диаграммам на странице.
В идеале метки диаграммы должны быть короткими, так как это проще всего для пользователя. Однако иногда это невозможно, и когда вы разрабатываете общие визуализации, которые представляют данные, которые вы не контролируете, у вас нет большого выбора. В таких случаях вам нужно что-то сделать, чтобы улучшить стандартный подход «переполнить поле», который вы получаете от NVD3, и этот подход с переносом меток, переносом и усечением очень подходит.
Ричард - основатель и старший партнер Cottage Labs, консалтинговой компании по разработке программного обеспечения, специализирующейся на всех аспектах жизненного цикла данных. Иногда он в Твиттере по адресу @richard_d_jones
PS - вот полный фрагмент кода
function wrapLabels(params) {
var axisSelector = params.axisSelector;
var maxWidth = params.maxWidth;
var maxHeight = params.maxHeight;
var lineHeight = params.lineHeight || 1.2;
var wordBreaks = params.wordBreaks || [" ", "\t"];
var minChunkSize = params.minChunkSize || 3;
function _isMidWord(currentLine, remainder) {
var leftChar = $.inArray(currentLine[currentLine.length - 1], wordBreaks) === -1;
var rightChar = $.inArray(remainder[0], wordBreaks) === -1;
return leftChar && rightChar;
}
function _toPrevSpace(currentLine) {
for (var i = currentLine.length - 1; i >= 0; i--) {
var char = currentLine[i];
if ($.inArray(char, wordBreaks) !== -1) {
return currentLine.length - i;
}
}
return -1;
}
function _backtrack(count, currentLine, remainder) {
for (var i = 0; i < count; i++) {
remainder.unshift(currentLine.pop());
}
}
function _isTooLong(tspan) {
return tspan.node().getComputedTextLength() >= maxWidth
}
function separate(text) {
// get the current content then clear the text element
var chars = text.text().trim().split("");
text.text(null);
// set up registries for the text lines that they will create
var lines = [];
// create a tspan for working in - we need it to calculate line widths dynamically
var x = text.attr("x");
var tspan = text.append("tspan").attr("x", x).attr("y", 0);
// record the current line
var currentLine = [];
// for each character in the text, push to the current line, assign to the tspan, and then
// check if we have exceeded the allowed max width
while (chars.length > 0) {
var char = chars.shift();
currentLine.push(char);
tspan.text(currentLine.join(""));
var maxed = false;
var hyphenated = false;
while(_isTooLong(tspan)) {
// record that we pushed the tspan to the limit
maxed = true;
// if we already added a hyphen, remove it
if (hyphenated) {
currentLine.splice(currentLine.length - 1);
hyphenated = false;
}
// if we have exceeded the max width back-track 1
_backtrack(1, currentLine, chars);
if (_isMidWord(currentLine, chars)) {
var toPrevSpace = _toPrevSpace(currentLine);
if (toPrevSpace === -1 || toPrevSpace - 1 > minChunkSize) {
_backtrack(1, currentLine, chars);
currentLine.push("-");
hyphenated = true;
} else {
_backtrack(toPrevSpace, currentLine, chars);
}
}
currentLine = currentLine.join("").trim().split("");
tspan.text(currentLine.join(""));
}
// if we didn't yet fill the tspan, continue adding characters
if (!maxed && chars.length > 0) {
continue;
}
// otherwise, move on to the next line
if (maxed || chars.length === 0) {
lines.push(currentLine);
currentLine = [];
}
}
// create all the tspans
tspan.remove();
var tspans = [];
for (var i = 0; i < lines.length; i++) {
tspan = text.append("tspan").attr("x", x).attr("y", 0);
tspan.text(lines[i].join(""));
tspans.push(tspan);
}
return tspans;
}
function distribute(text, tspans) {
var imax = tspans.length;
var pmax = lineHeight * (imax - 1);
var dy = parseFloat(text.attr("dy"));
for (var j = 0; j < tspans.length; j++) {
var pos = (lineHeight * j) - (pmax / 2.0) + dy;
var tspan = tspans[j];
tspan.attr("dy", pos + "em");
}
}
function reduce(text, tspans) {
var reduced = false;
var box = text.node().getBBox();
if (box.height > maxHeight && tspans.length > 1) {
tspans[tspans.length - 1].remove();
tspans.pop();
var line = tspans[tspans.length - 1].text();
if (line.length > 3) {
line = line.substring(0, line.length - 3) + "...";
}
tspans[tspans.length - 1].text(line);
reduced = true;
}
return reduced;
}
d3.selectAll(axisSelector + " .tick text").each(function(i, e) {
var text = d3.select(this);
var tspans = separate(text);
do {
distribute(text, tspans);
}
while (reduce(text, tspans))
});
}