
Data in Motion — это автоматизированная служба публикации для социального взаимодействия, основанная на изменениях важных данных. Его основная цель — инициировать оповещения при изменении данных.
Алехандро Лопес:
разработчик программного обеспечения, постоянно работающий над решением проблем с помощью творчества, критического мышления и самообучения. Всегда адаптируемся к новым технологиям благодаря страсти к развитию.
Роль Алехандро в проекте заключается в том, чтобы придумывать и разрабатывать решения для бэкенда, анализирующего внешние источники данных.
Даниэль Родригес:
исполнитель, который любит участвовать в сложных проектах, думать и создавать нестандартные решения, мотивированные совместной работой.
Роль Даниэля в проекте заключается в создании и развитии триггерных сервисов, которые подключают сообщения к системам рассылки.
Виктор Эрнандес:
творческий человек, претворяющий идеи в жизнь, ищущий новые способы использования и делающий технологии доступными людям.
Роль Виктора в проекте заключается в создании пользовательского потока, UX-взаимодействий, создании инфраструктуры, развертывании и масштабировании решения.
Что особенного в нашем проекте?
Простое в использовании веб-приложение, в котором вы можете выбрать источник данных, переменную, которая изменяется (триггер), и сообщение социального взаимодействия, которое будет опубликовано, когда это произойдет.

Мы живем в мире, управляемом данными, но мы видим, что многие усилия по сбору, хранению и обработке данных определяются как репозиторий или своего рода резервная копия.
Даже с ИИ результаты этих усилий очень ограничены с точки зрения его использования в реальном мире.
Наша цель состоит в том, чтобы сломать эти ограничения на данные. мы хотим перестать рассказывать истории о данных из прошлого.
Поэтому наша идея с Data in Motion состоит в том, чтобы быть сервисом публикации аналитических данных в режиме реального времени для социального взаимодействия.
Мы хотим мобилизовать людей, сообщая им об изменениях в схемах важных источников данных.
Мы можем инициировать события и анализ данных, которые положительно повлияют на решения, когда это важно.
что мы получаем сейчас с этим MVP?
Для этого MVP мы достигаем этого:
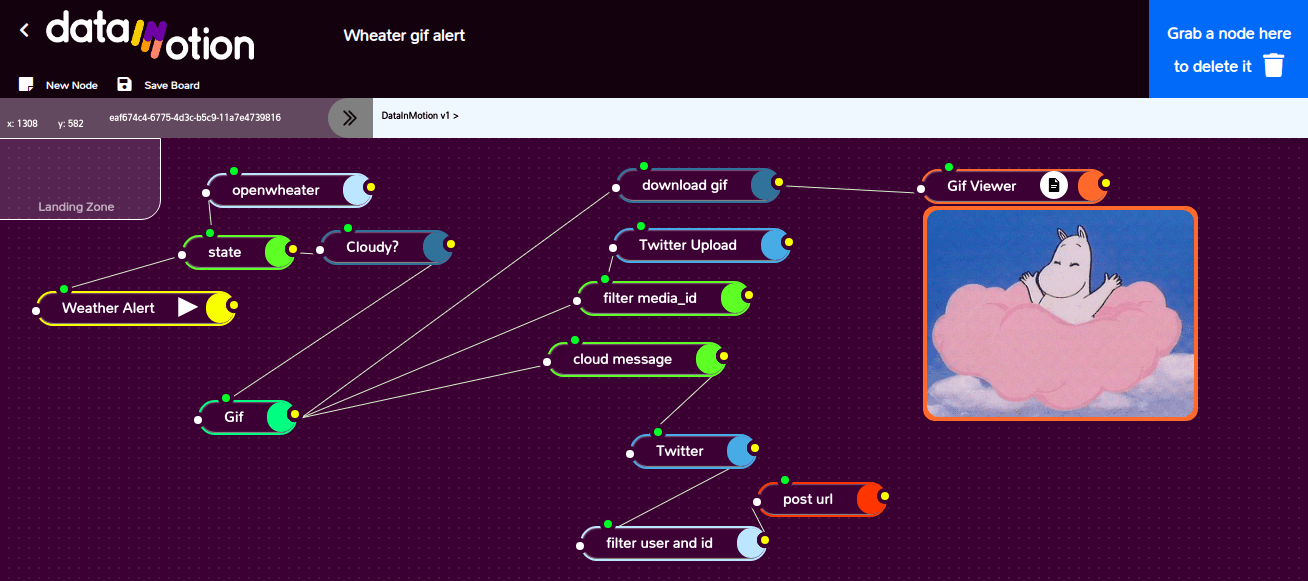
Полный поток, который может получать внешнюю информацию через API, отслеживать изменения в данных и настраивать триггер, а затем полную конфигурацию пользовательского сообщения, и для этого MVP публиковать базовое сообщение в твиттере.
Всю эту демонстрацию мы достигаем с помощью следующих инструментов:

Проблемы
Источник, местоположение, вариант и цель — это ключевые переменные, необходимые нашему решению для создания одного триггера на основе данных, которые мы читаем. хотите быть решением plug / configure / and play, которое может обрабатывать множество сценариев, которые могут возвращать выходные данные.
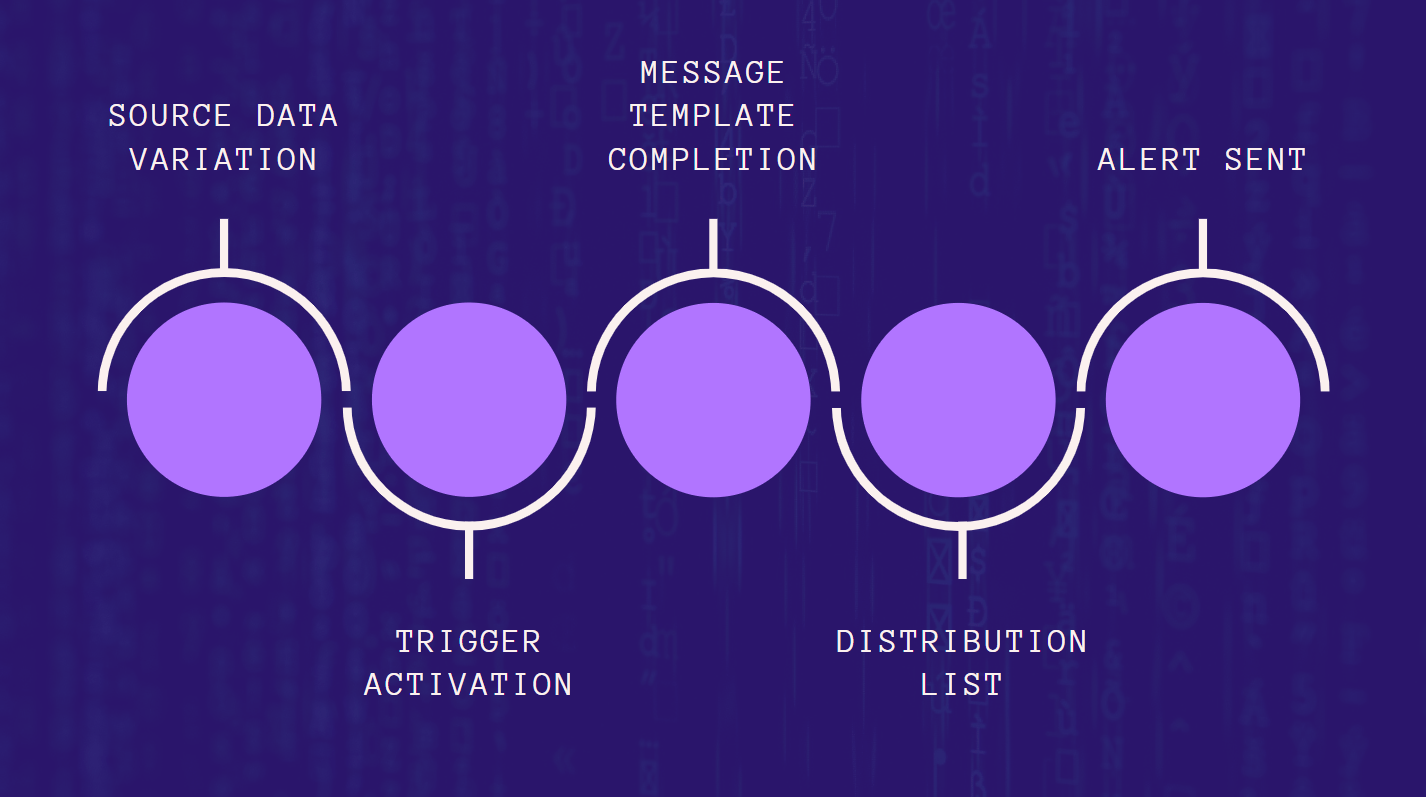
Это наша первая диаграмма, которая пытается наглядно показать решение и то, как передать определенную схему ввода-вывода другому «модулю/сервису», мы не пытаемся решить проблему дезагрегированных данных, манипулирования данными, интеллектуального анализа данных и создание новых наборов данных.
Основная цель состоит в том, чтобы получить источник, который выделяет информацию, которую можно активировать для создания ценности в реальном времени и которую можно подключить к любым существующим данным.
Вот некоторые из наихудших сценариев, которые могут возникнуть при реализации проекта:
- Плохие источники данных/плохой доступ к источникам данных: если данные находятся в старой инфраструктуре, их вычислительная мощность ограничена для выполнения запроса в заданное время (это может быть запланировано), у нас могут возникнуть проблемы с вызовом и срабатыванием триггера.
- Триггеры устанавливаются с параметрами, которые никогда не достигают EJ (получите климатические данные с 1000 ° F, чтобы поднять предупреждение), мы можем получить «никогда не встречающиеся триггеры», поэтому мы думаем подключить данные и сделать автоматическую рекомендацию / рецепт, чтобы быстро начать решение .
- Много триггеров на разных источниках данных. Мы думаем об объеме памяти решения, потому что вычислительная мощность не требовательна, а требует получения внешних данных.
- Непонимание клиентом и завышенные ожидания относительно того, что и когда получить. Поэтому нам нужно с самого начала иметь четкое представление о масштабах решения, хорошо задокументированных пользовательских случаях и т. д.
Что мы узнаем в процессе
1 Потенциальные клиенты начинают видеть практическое применение своих собственных данных с примерами и примерами. Итак, мы проверяем, как создавать заинтересованные.
2. Python обладает большим потенциалом для манипулирования данными и подходит нам для построения нашего MVP.
3. Визуальные программные интерфейсы. » являются ключом к тому, как взаимодействовать с системой.
4. Работающий процесс crontab, который нам нужно разработать для отслеживания изменений во внешних службах данных, этот процесс необходимо обновить позже ;-)
5 , MVP использует Jquery, но сложность должна начинаться с этого ограничения обработки сложных объектов. много автоматизации, поэтому получение своевременных обновлений во время процесса приветствуется в начале.
Ссылки в изобилии