Алгоритм совместной фильтрации на основе элементов (IBCF) получил признание проверки временем в 2017 году, на год позже AlphaGo Master, нейронная сеть (NN) Google, которая может научиться играть в го, выиграла одно из самых ярких человеческих достижений в го. игроков, Ли Седол.
На работе мне всегда нравится выбирать простые алгоритмы вместо более сложных - когда оба работают одинаково - более простые алгоритмы требуют меньше времени для запуска и реализации, но теперь я не могу удержаться от выяснения того, как базовый автокодировщик NN выполняет рекомендации, учитывая все шумиха вокруг NN и, в частности, глубокого обучения, а также доступность пакетов (читай: tensorflow), которые упрощают реализацию моделей NN, от обучения до производства.
Давайте посмотрим, как простой автоэнкодер (нейронная сеть, имеющая столько же входов, сколько и выходов) конкурирует с классическим алгоритмом IBCF.
Мы будем использовать набор данных MovieLens 100K, и мы будем использовать его в неявном режиме, что означает, что рекомендатель будет предсказывать, основываясь на известных рейтингах фильмов для каждого пользователя, какие еще фильмы человек будет смотреть (или, строго говоря, , ставка).
Чтобы набор данных соответствовал неявному представлению, оценки преобразуются в 1, если был какой-либо рейтинг, и в 0 в противном случае. Термин «взаимодействие» используется далее для описания того факта, что пользователь оценил данный фильм.
Данные делятся на обучающие и тестовые, 80% и 20%.
Оценка производительности модели выполняется путем сокрытия одного взаимодействия из набора взаимодействий каждого пользователя, вывода k основных рекомендаций и оценки среднего показателя успешности на уровне k (HR @ k) , HR = TP / P (в наших настройках P всегда равно 1, так как на каждого пользователя приходится только 1 скрытое взаимодействие, а TP может быть 1 или 0 в зависимости от того, скрытое взаимодействие входит в рекомендуемый набор из k элементов или нет.
Выбранная метрика производительности менялась в зависимости от элемента, который был скрыт, поэтому оценка производительности выполнялась 10 раз для каждой модели, и сообщалось среднее значение HR @ k.
Несколько вспомогательных функций (доступны здесь) используются для форматирования данных, оценки производительности и составления прогнозов:
- makeRecommendlabTrainSets () форматирует данные как двоичную матрицу элементов пользователя, разбивает данные на обучающие и тестовые наборы;
- maskInteraction () используется для отбрасывания одного из взаимодействий пользователя, чтобы иметь возможность позже восстановить его с помощью модели, полезной для оценки производительности модели;
- AssessmentGuess () сравнивает фактическое отброшенное взаимодействие со списком взаимодействий, предложенным моделью - IBCF, NN и простой прогноз с k наиболее часто встречающимися фильмами;
- netPredictOne () - это функция-оболочка для создания одного прогноза с моделью NN, немного избыточной для этой статьи, используемой как есть в другом моем проекте;
Для классического алгоритма используется алгоритм совместной фильтрации элемент-элемент из пакета R Recommenderlab со всеми настройками по умолчанию, а для модели NN - простой автокодер с одним скрытым слоем размером 1/3 входного размера, обученный с помощью керас . Чтобы сравнить обе модели с простейшей альтернативой, также была оценена модель наиболее частых взаимодействий, MFM. Все модели предсказали максимальное k = 10 взаимодействий.
Полный код воспроизводимых результатов доступен здесь.
Модель NN была наиболее точной, давая HR @ 10 0,22, что вдвое больше, чем модель IBCF (0,11), и почти в 3 раза больше, чем модель наиболее частого взаимодействия (0,08).
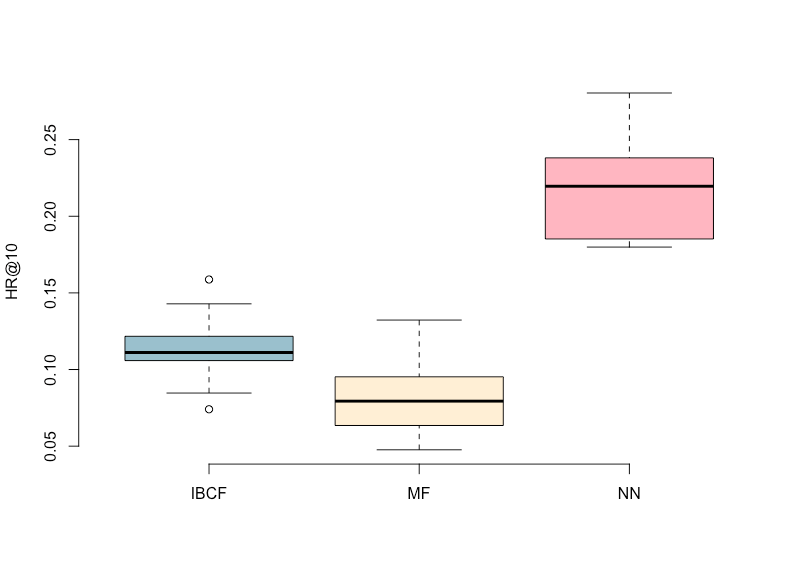
Точность рекомендаций модели IBCF соответствует точности, полученной на том же наборе данных другими. Модель MF, как и ожидалось, имела наименьшую точность.
В нашем небольшом эксперименте по сравнению моделей NN и IBCF для неявных рекомендаций NN показал себя на удивление хорошо, намного лучше, чем классическая модель IBCF. Однако никакой очистки данных не проводилось, и для модели IBCF не применялись никакие различные меры расстояния. Кроме того, настройка гиперпараметров не производилась, за исключением размера скрытого слоя или 1/3 размера входных данных, что лучше всего работало в предыдущем опыте.
При обучении модели NN наборы для тестирования и проверки были равны, поскольку набор данных довольно мал, но не использование набора тестов во время обучения и остановка, когда ошибка поезда не улучшилась, дала те же результаты.
Обычно я довольно скептически отношусь к использованию нейронных сетей для обучения чему-либо еще, кроме данных, сгенерированных машиной (изображение / видео / звук), но, учитывая, насколько легко передать вспомогательные входные данные в нейронные сети и, возможно, еще больше улучшить качество рекомендаций, похоже, что у нейронных сетей есть все шансы стать еще лучшими советчиками.
- Статья с рекомендациями автоэнкодера, к сожалению, без оценки производительности
- Статья по шумоподавлению автокодировщиков для рекомендаций, по каким-то причинам очень разные результаты
- Подобные результаты для метода IBCF в модуле Python LightFM
- Еще одна статья об автоэнкодере, которую я использовал для вдохновения, очень красиво написана.
- Множественные сети ввода-вывода