
Мотивация:
Существует множество данных, которые могут быть представлены в виде графика в реальных приложениях, таких как сети цитирования, социальные сети (граф последователей, сеть друзей,…), биологические сети или телекоммуникации.
Использование функций извлечения Graph может повысить производительность прогнозных моделей, полагаясь на информационный поток между соседними узлами. Однако представление данных графа непросто, особенно если мы не намерены реализовывать функции, созданные вручную, поскольку большинство моделей машинного обучения ожидают ввода фиксированного размера или линейного ввода, что не относится к данным графа.
В этом посте мы будем изучить некоторые способы работы с общими графами для классификации узлов на основе представлений графов, полученных непосредственно из данных.
Набор данных:
Набор данных сети цитирования Cora будет служить базой для реализации и экспериментов в этом посте. Каждый узел представляет научную статью, а края между узлами представляют собой отношение цитирования между двумя статьями.
Каждый узел представлен набором двоичных функций (мешком слов), а также набором ребер, которые связывают его с другие узлы.
Набор данных содержит 2708 узлов, отнесенных к одному из семи классов. В сети есть 5429 ссылок. Каждый узел также представлен функциями двоичного слова, указывающими на наличие соответствующего слова. Всего существует 1433 двоичных (разреженных) функций для каждого узла. Далее мы только используем 140 образцов для обучения, а остальные - для проверки / тестирования.
Постановка проблемы:

Проблема: присвоение метки класса узлам на графике при небольшом количестве обучающих выборок.
Интуиция / Гипотеза: близкие узлы на графике, скорее всего, будут иметь похожие метки.
Решение: найдите способ извлекать элементы из графика, чтобы помочь классифицировать новые узлы.
Предложил подход :
Базовая модель:
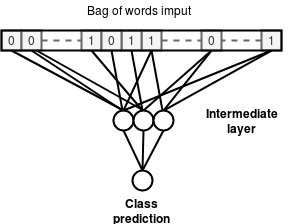
Сначала мы экспериментируем с простейшей моделью, которая учится предсказывать классы узлов, используя только двоичные функции и отбрасывая всю информацию о графах.
Эта модель представляет собой полностью подключенную нейронную сеть, которая принимает на вход двоичные функции и выводит вероятности классов для каждый узел.
Точность базовой модели: 53,28%
Это начальная точность, которую мы постараемся улучшить, добавив функции на основе графиков.
Добавление функций графика:
Один из способов автоматического изучения функций графа путем встраивания каждого узла в вектор путем обучения сети вспомогательной задаче прогнозирования обратной длины кратчайшего пути между двумя входными узлами, как показано на рисунке и фрагменте кода ниже:

Следующим шагом является использование встраивания предварительно обученного узла в качестве входных данных для модели классификации. Мы также добавляем дополнительный вход, который представляет собой средние двоичные характеристики соседних узлов с использованием расстояния изученных векторов внедрения.
Полученная классификационная сеть описана на следующем рисунке:

Точность модели классификации встраивания графиков: 73,06%
Мы видим, что добавление изученных графических элементов в качестве входных данных в модель классификации помогает значительно повысить точность классификации по сравнению с базовой моделью с 53,28% до 73,06% 😄.
Улучшение изучения функций Graph:
Мы можем стремиться к дальнейшему улучшению предыдущей модели, продвигая предварительное обучение дальше и используя двоичные функции в сети внедрения узлов, а затем повторно используя предварительно обученные веса из двоичных функций в дополнение к вектору внедрения узла. Это приводит к модели, которая полагается на более полезные представления двоичных функций, извлеченных из структуры графа.
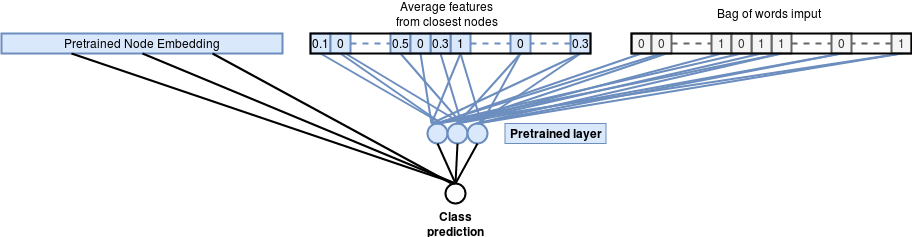
Улучшенная модель классификации встраивания графиков Точность: 76,35%
Это дополнительное улучшение добавляет несколько процентов точности по сравнению с предыдущим подходом.
Заключение :
В этом посте мы увидели, что можем изучать полезные представления из структурированных данных графа, а затем использовать эти представления для повышения эффективности обобщения модели классификации узлов с 53,28% до 76,35% 😎.
Код для воспроизведения результатов доступен здесь: https://github.com/CVxTz/graph_classification
Не стесняйтесь комментировать, если у вас есть какие-либо предложения или вам нужны указатели для запуска кода на вашем компьютере 😉