Исследователи Facebook представили два новых метода предварительного обучения кросс-языковых языковых моделей (XLM). Неконтролируемый метод использует одноязычные данные, тогда как контролируемая версия использует параллельные данные с новой межъязыковой языковой моделью. Исследование направлено на создание эффективного кросс-языкового кодировщика для предложений на разных языках в одном и том же встроенном пространстве - подход с общим пространством кодирования, который обеспечивает преимущества для таких задач, как машинный перевод.
Результаты исследований демонстрируют повышенную эффективность в различных задачах межъязыкового понимания и современные результаты межъязыковой классификации, неконтролируемого и контролируемого машинного перевода.
Проект Facebook XLM содержит код для:
- Предварительная подготовка языковой модели:
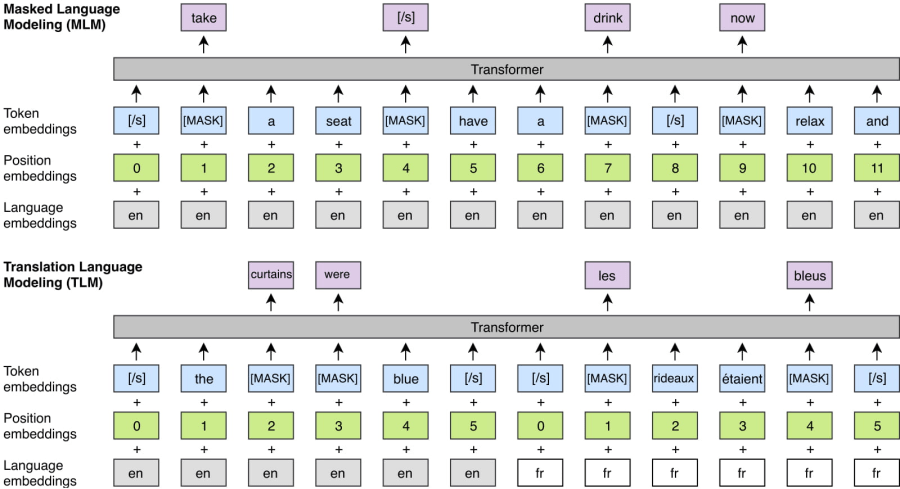
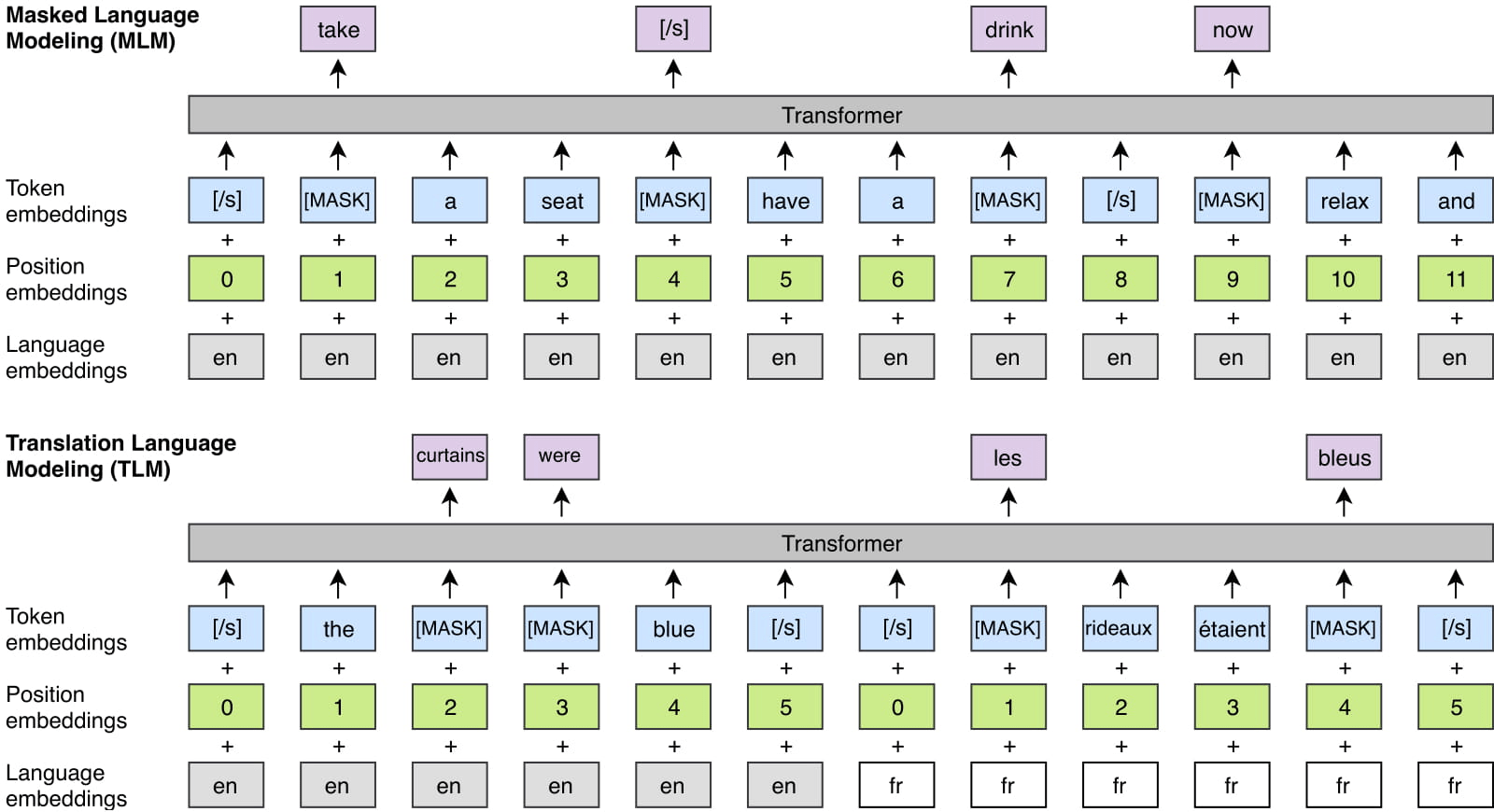
Модель каузального языка (CLM) - одноязычная
Маскированная языковая модель (MLM) - одноязычная
Модель языка перевода (TLM) - межъязыковая
- Обучение машинному обучению под присмотром / без учителя:
Автоматический кодировщик шумоподавления
Параллельное обучение данных
Обратный перевод онлайн
- Тонкая настройка XNLI
- КЛЕЙ точная настройка
XLM также поддерживает обучение с использованием нескольких графических процессоров и нескольких узлов.
Создание межъязычных представлений предложений
Проект предоставляет образец кода, который может быстро получить представления предложений на разных языках из предварительно обученных моделей. Эти межъязыковые представления предложений полезны для машинного перевода, вычисления сходства предложений или реализации межъязыковых языковых классификаторов. Примеры, представленные в проекте, в основном написаны на Python 3 и требуют поддержки со стороны библиотек Numpy, PyTorch, fastBPE и Moses.
Для создания кросс-языковых представлений предложений первым шагом является импорт файлов кода и библиотек и загрузка модели предварительного обучения:
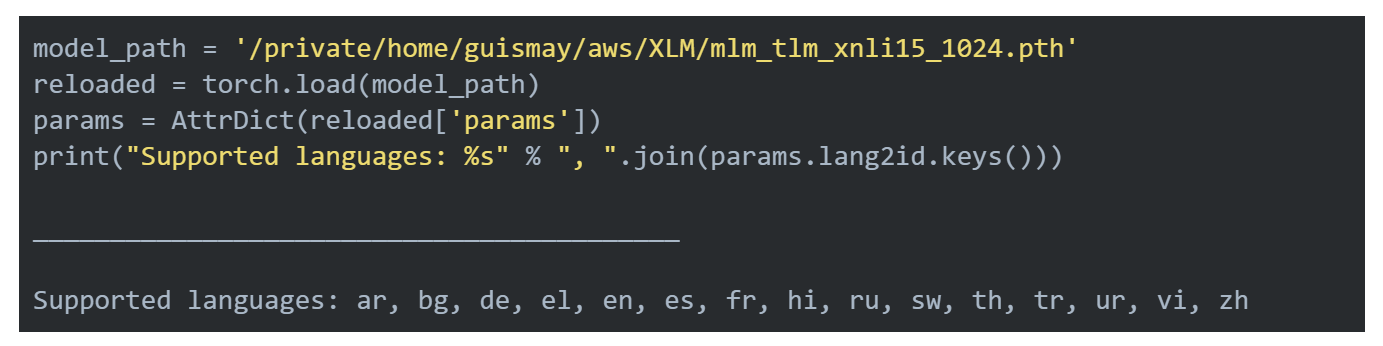
Затем создайте словарь, обновите параметры и постройте модель:

Ниже приводится список случаев в формате BPE (на основе библиотеки fastBPE), в которых исследователи извлекали представления предложений на основе модели предварительного обучения:

Последним шагом является создание пакета и завершение прямого распространения для создания вектора встраивания окончательного предложения:

Окончательную форму выходного тензора (sequence_length, batch_size, model_dimension) можно дополнительно настроить для выполнения 11 задач NLP или задач XNLI в GLUE.
Исследователи сообщают, что их метод без учителя получил оценку 34,3 BLEU по немецко-английскому тесту WMT’16, превзойдя предыдущий лучший подход более чем на 9 BLEU. Что касается управляемого машинного перевода, то результаты теста румынско-английского языка WMT’16 выросли более чем на 4 балла по шкале BLEU, установив новый современный балл - 38,5 BLEU.
Статья Предварительное обучение межъязыковой языковой модели посвящена arXiv.
Автор: Виктор Лу | Редактор: Майкл Саразен
Вышел Отчет об адаптивности AI для публичной компании Fortune Global 500 за 2018 год!
Приобретите отчет в формате Kindle на Amazon.
Подайте заявку на участие в Партнерской программе Insight, чтобы получить бесплатный полный отчет в формате PDF.

Подпишитесь на нас в Twitter @Synced_Global, чтобы получать ежедневные новости об ИИ!
Мы знаем, что вы не хотите пропустить ни одной истории. Подпишитесь на наш популярный Synced Global AI Weekly , чтобы получать еженедельные обновления AI.
