
Ранее, в продолжающейся хронике нашего поиска создания музыкального визуализатора для записывающихся артистов, я рассказывал о своей попытке отрендерить тридцать аудиомодулированных кадров в секунду с помощью Three.js и отправить их на сервер в реальном времени для компиляции в видео. . Я обнаружил, что это невозможно с обычным оборудованием, которое могут использовать наши потенциальные клиенты.
Это действительно очень плохо, так как я мог видеть почти в два раза больше кадров, пролетающих в браузере, с объектами в сцене, которые все танцевали в такт. Так близко, но все же так далеко. Падение заключалось в том, что время, необходимое для извлечения каждого отрендеренного кадра из холста.
В этой части я выбрал метод извлечения спектральных аудиоданных за один проход, а затем использовал эти снимки во втором проходе рендеринга. Это занимает немного больше времени, но есть и преимущество: я могу выводить с более высокой частотой кадров! 48 кадров в секунду намного плавнее, чем 30, а поскольку нас больше не волнует генерация кадров в реальном времени, почему бы не снимать луну?
Я не буду публиковать здесь весь код, поскольку он в значительной степени представляет собой эволюцию демонстрации прошлой недели, но вы можете взять его из этого GitHub Gist. Достаточно сказать, что попытка этой недели увенчалась успехом. Вы можете загрузить произвольный аудиофайл, и будет отображено музыкальное видео.
Читайте дальше, чтобы понять, как все части сочетаются друг с другом, чтобы это стало возможным.
Случайная асинхронность
В коде, связанном с предыдущим экспериментом, я только рендерил кадры. Я расширил это, чтобы извлечь моментальный снимок звуковой активности на лету, используя API веб-аудио и, в частности, обратный вызов аудиопроцесса AudioBufferSourceNode.
Эти снимки использовались в режиме реального времени для управления визуализируемой сценой. Через мгновение мы рассмотрим, как это достигается, но как только это было сделано, моей первой мыслью было, что я должен иметь возможность просто помещать каждый снимок в массив и передавать их в процесс рендеринга позже.
Это было наивно. Я понятия не имел, как часто вызывается обратный вызов. В свою защиту скажу, что я придумал это, пока спал. Позже, в душе, здравый смысл взял верх, и я понял, насколько это неработоспособно.
В переработанном демо происходило два независимых цикла асинхронной обработки: обработка звука и рендеринг кадров. Единственной связью между ними был объект значения, который содержит извлеченные аудиоданные. Как часто извлекался звук? Как часто рендерилась сцена? Оба могут быть случайными. Просто каждый раз при рендеринге кадра использовались последние извлеченные аудиоданные.
Однако, чтобы создать видео с заданной частотой кадров, мы не можем полагаться на случайность. Это означает, что нам нужно четко понимать, как управлять синхронизацией обработки звука.
Настройка аудио узлов
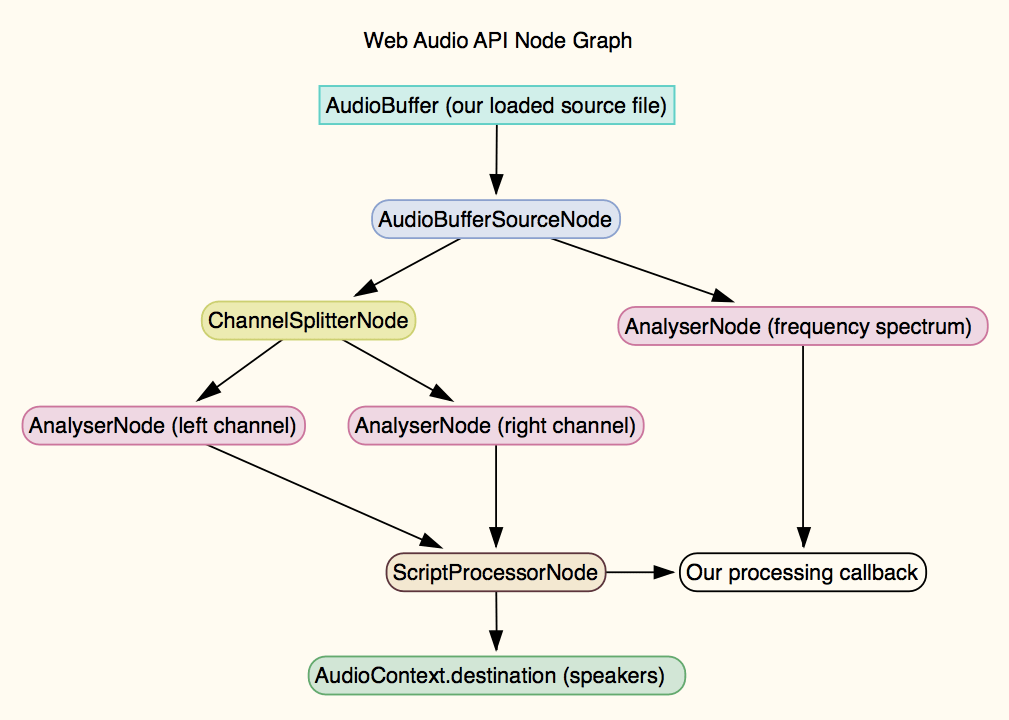
Чтобы сделать снимки атрибутов звука, которые будут использоваться для модуляции элементов 3D-сцены, мы должны настроить AudioContext и нетривиальный конвейер узлов, включая AudioBufferSourceNode, который представляет загруженные аудиоданные, ChannelSplitterNode, три AnalyserNode для захвата громкости левого канала, громкости правого канала и комбинированного частотного спектра и громкости, и, наконец, ScriptProcessorNode, который будет многократно вызывать нашу функцию обработки, предупреждая нас, когда воспроизведение звука прекращается, и выводить звук в место назначения AudioContext, динамики.
Вот как все это связано вместе:
// Set up audio nodes for playback and analysis
function setupAudioNodes() {
// If AudioContext is there, create the AudioVO and initialize its AudioContext
window.AudioContext = window.AudioContext || window.webkitAudioContext;
if (!window.AudioContext) {
console.log('No AudioContext found.');
} else {
// Set up the audio context
audioVO.context = new AudioContext();
// Set up a script processor node
audioVO.javascriptNode = audioVO.context.createScriptProcessor(2048, 1, 1);
// Set up channel and frequency analyzers
audioVO.analyser = audioVO.context.createAnalyser();
audioVO.analyser.smoothingTimeConstant = 0.5;
audioVO.analyser.fftSize = 1024;
audioVO.analyser2 = audioVO.context.createAnalyser();
audioVO.analyser2.smoothingTimeConstant = 0.5;
audioVO.analyser2.fftSize = 1024;
audioVO.analyserFreq = audioVO.context.createAnalyser();
audioVO.analyserFreq.smoothingTimeConstant = 0.3;
audioVO.analyserFreq.fftSize = 256;
// Create a buffer source node and splitter
audioVO.sourceNode = audioVO.context.createBufferSource();
audioVO.splitter = audioVO.context.createChannelSplitter();
// Connect buffer source node to frequency analyser and splitter
audioVO.sourceNode.connect(audioVO.splitter);
audioVO.sourceNode.connect(audioVO.analyserFreq);
audioVO.sourceNode.onended = finished;
// Connect outputs from splitter to channel analysers
audioVO.splitter.connect(audioVO.analyser, 0, 0);
audioVO.splitter.connect(audioVO.analyser2, 1, 0);
// Connect the analysers to the javascriptnode
audioVO.analyser.connect(audioVO.javascriptNode);
audioVO.analyser2.connect(audioVO.javascriptNode);
}
}
Предварительная обработка аудио
Если 48 кадров в секунду — желаемая частота кадров, нам нужно ровно 48 аудиоснимков в секунду, ни больше, ни меньше. И они должны быть разнесены как можно ближе к 0,0208 секунды. Для этого я создаю массив секунд, где каждый элемент представляет собой массив предварительно заданного размера из 48 снимков. Но как узнать, когда нужно сохранить один из этих снимков?
API веб-аудио предоставляет собственную систему синхронизации, которая, как сообщается, намного лучше, чем часы JavaScript. AudioContext.currentTime возвращает время, прошедшее с момента создания AudioContext. К сожалению, многое происходит после того, как я создаю аудиоконтекст, например, настраиваю буферы и анализаторы, добавляю обратный вызов обработки звука и т. д., прежде, чем я могу начать воспроизведение дорожки. Невозможно узнать текущее время самого трека. Итак, в моем обратном вызове обработки звука при первом вызове я должен вычислить смещение. Это позволяет мне быть в курсе времени отслеживания и, таким образом, знать, не пора ли сохранить последний сделанный моментальный снимок в следующую корзину времени кадра в массиве секунд.
Как будто с таймингом не все в порядке, есть тот факт, что начало обработки звука и начало воспроизведения на самом деле не могут быть синхронизированы. AudioBufferSourceNode начинает вызывать свою функцию onaudioprocess, как только вы устанавливаете для него обратный вызов. Воспроизведение звука начинается (на моей машине) примерно через 11 миллисекунд после вызова AudioBufferSourceNode.start(), поэтому я запускаю воспроизведение звука, а затем устанавливаю обратный вызов. В любом случае, обычный результат — несколько тихих звуковых кадров в начале моих снимков. Их достаточно легко выбросить позже.
Другая проблема заключается в том, что вызовы обратного вызова onaudioprocess не гарантируются. Если ваш компьютер занят, он может пропустить несколько кадров между вызовами. Если бы я просто загружал моментальные снимки в массив, это было бы трудно обнаружить и исправить. Таким образом, в моем массиве секунд каждый раз, когда правильно смещенное значение currentTime AudioContext (которое возвращается в секундах, а не в миллисекундах, как часы JavaScript) переходит в новую секунду, я добавляю еще один массив снимков с предварительно заданным размером 48 (или любой другой частотой кадров). есть) элементы. И когда я сохраняю снимок, я помещаю его в то, что я считаю правильным сегментом, в зависимости от времени.
В конце воспроизведения у нас есть массив массивов, загруженных снимками. Некоторые элементы моментальных снимков могут отсутствовать из-за случайных сбоев во времени обратного вызова, и, вероятно, в начале есть несколько кадров молчаливых снимков из-за проблемы с синхронизацией при запуске. Но снимки, которые у нас есть, относительно друг друга находятся в нужном месте.
Чтобы создать поток снимков, которые может использовать процесс рендеринга, я выполняю проход по извлеченным данным, отбрасывая все начальные молчащие кадры, а когда натыкаюсь на пустой элемент, заполняю его копией предыдущего снимка. В качестве будущей оптимизации я заполню эту дыру ближайшим снимком, а не предыдущим, так что, если промежуток составляет четыре кадра, первые две дыры заполняются последним хорошим снимком, а последние две заполняются следующий. Или, возможно, даже интерполировать значения между следующим и предыдущим. К счастью, эти сбои случаются не часто и не надолго, и есть способ подстраховаться: выбрать правильный размер буфера для желаемой частоты кадров.
Как размер аудиобуфера влияет на частоту кадров
Когда вы вызываете AudioContext.createScriptProcessor(), первым параметром является размер буфера, и он влияет на то, как часто будет вызываться ваш обратный вызов обработки звука. Значение должно быть степенью двойки, начиная с 512 (512, 1024, 2048, 4096...). ScriptProcessor ждет, пока этот буфер не заполнится, прежде чем вызывать вас, поэтому, как и следовало ожидать, соотношение между размером буфера и частотой вызовов обратно пропорционально; чем больше размер буфера, тем реже будет вызываться ваш обратный вызов. Однако ничто не гарантируется, поскольку ваша система иногда может быть слишком занята, чтобы сделать звонок.
Вы хотите, чтобы обратные вызовы происходили по крайней мере так же часто, как желаемая частота кадров, желательно намного чаще, чтобы уменьшить влияние любых сбоев. Итак, я провел небольшое тестирование, чтобы определить оптимальный размер буфера, воспользовавшись возможностью FireFox сообщать о повторяющихся строках журнала консоли. Если об одной и той же строке сообщается более одного раза, она отображается с красной табличкой, указывающей количество повторяющихся строк. Я добавил вызов console.log() в конце моей функции обработки звука, сообщая о секунде, для которой я обрабатывал звук.
Результаты:
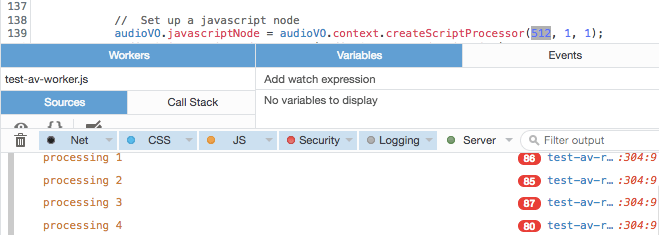
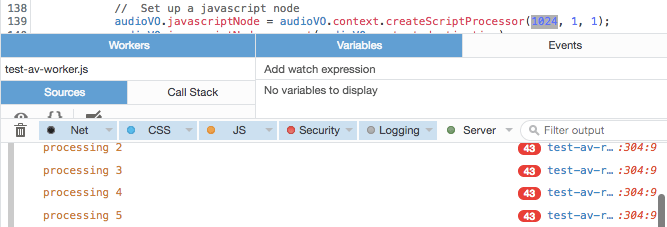
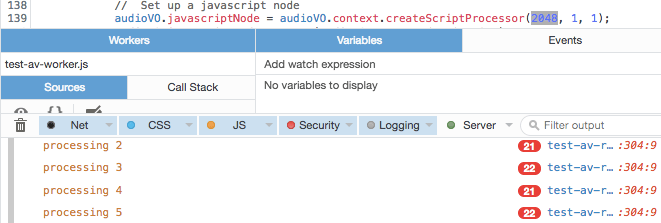
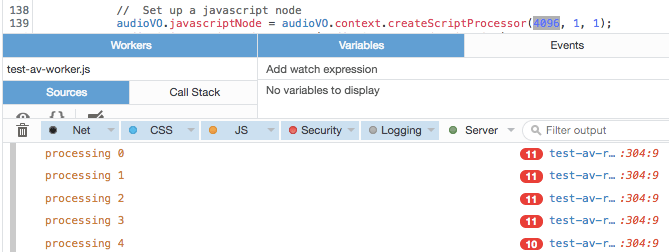
Следовательно, если нам нужна частота кадров 48 кадров в секунду, нам нужно установить буфер наименьшего размера: 512, что дает примерно 80 обратных вызовов в секунду. В противном случае мы можем не получить достаточно снимков на более медленной или перегруженной машине, а икота может оказать более пагубное влияние на результирующий поток данных.
Наш обратный вызов обработки звука хранит данные в объекте-значении с именем audioVO:
// Audio value object.
// Values extracted on each audio sample that affect rendered scene.
var audioVO = {
context: null,
sourceNode: null,
javascriptNode: null,
splitter: null,
analyser: null,
analyser2: null,
analyserFreq: null,
audio_freqArray: [],
audio_lAverage: 0,
audio_rAverage: 0,
audioVolume: 0,
audioBass: 0,
audioHigh: 0,
audioMid: 0
};
Вот что он делает каждый раз, когда ScriptProcessorNode вызывает нас обратно:
// Audio processing callback
//
// Collects an array of arrays: seconds and snapshots.
// We don't know duration of the audio, so we track
// each second, collecting an array of snapshots,
// each taken at its calculated offset within the second.
// Since there could be hiccups in timing, and we have
// no assurance that we'll be called exactly on time for
// each snapshot, we take a snapshot (in audioVO) each
// time we're called, and when we reach (or pass) the
// next target frame time, we use last one taken.
function process() {
// On first call, get offset since context was created
if (!offset) offset = audioVO.context.currentTime;
// Get the adjusted time in seconds since we started playback
currentTime = audioVO.context.currentTime - offset;
// Get the array of frames for the current second
currentSecond = Math.floor(currentTime);
if (seconds.length > currentSecond) {
currentFrameSet = seconds[currentSecond];
} else {
currentFrameSet = new Array(FPS);
seconds.push(currentFrameSet);
currentFrame = 0;
}
// Calculate the target time for this frame
// Frame frequency of 0.03333 yields 30 fps
// Frame frequency of 0.02083 yields 48 fps
// Frame frequency of 0.01666 yields 60 fps
targetTime = currentSecond + (currentFrame * frameFreq);
// Have we passed the target time?
// If so, store the last snapshot for the target.
if (currentTime > targetTime) {
displayMessage('Processing audio for second: ' + snapshot.second + ' / frame: ' + snapshot.frame );
currentFrameSet[currentFrame] = snapshot;
currentFrame++;
}
// Get average for the first channel
var array = new Uint8Array(audioVO.analyser.frequencyBinCount);
audioVO.analyser.getByteFrequencyData(array);
var average = getAverageVolume(array);
// Get average for the second channel
var array2 = new Uint8Array(audioVO.analyser2.frequencyBinCount);
audioVO.analyser2.getByteFrequencyData(array2);
var average2 = getAverageVolume(array2);
// Get frequency spectrum
var freqArray = new Uint8Array(audioVO.analyserFreq.frequencyBinCount);
audioVO.analyserFreq.getByteFrequencyData(freqArray);
// Load the audioVO with the actionable values
audioVO.audio_lAverage = average;
audioVO.audio_rAverage = average2;
audioVO.audioVolume = (average + average2) / 2 / 100;
audioVO.audio_freqArray = freqArray;
audioVO.audioBass = getAverageVolume(freqArray.slice(0, 7)) / 200;
audioVO.audioMid = getAverageVolume(freqArray.slice(8, 65)) / 125;
audioVO.audioHigh = getAverageVolume(freqArray.slice(65, 128)) / 75;
// Snapshot just the actionable values and timing info
snapshot = {
second: currentSecond,
frame: currentFrame,
currentTime: currentTime,
targetTime: targetTime,
audio_lAverage: audioVO.audio_lAverage,
audio_rAverage: audioVO.audio_rAverage,
audioVolume: audioVO.audioVolume,
audioBass: audioVO.audioBass,
audioHigh: audioVO.audioHigh,
audioMid: audioVO.audioMid
};
// Uncomment to determine how often this method is called
// console.log("processing "+currentSecond);
// Inner private function to get average volume
function getAverageVolume (array) {
var values = 0;
var average;
var length = array.length;
// get all the frequency amplitudes
for (var i = 0; i < length; i++) {
values += array[i];
}
average = values / length;
return average;
}
}
// The audio playback complete handler
function onPlaybackComplete() {
displayMessage('Audio playback complete');
audioVO.sourceNode.stop(0);
audioVO.sourceNode.disconnect(audioVO.context.destination);
audioVO.javascriptNode.disconnect(audioVO.context.destination);
audioVO.javascriptNode.onaudioprocess = null;
postProcessAudio();
}
Рендеринг кадров
Процесс рендеринга во многом такой же, как и в предыдущей статье, за исключением нескольких настроек.
Во-первых, я отображаю холст вместо того, чтобы отображать его вне экрана. По какой-то причине при рендеринге за кадром я видел куски черных кадров. Я понятия не имею, была ли это проблема, связанная с реализацией браузера или с чем-то еще. Когда вы изучаете закадровый рендеринг в Интернете, вы обычно находите советы, говорящие вам об использовании WebGLRenderTarget, но, к сожалению, вы не можете использовать canvas.toDataURL('image/png') для захвата изображения, которое можно просто протолкнуть через провод к серверу. Для целей этой демонстрации я не хотел добавлять уровень сложности, связанный с использованием gl.readPixels для получения данных и последующего преобразования их в PNG. Простым ответом было просто показать рендеримые кадры. В последней демонстрации мы были озабочены тем, чтобы пытаться делать что-то в реальном времени, а рендеринг вне экрана был способом сократить количество циклов процесса. Теперь, освободившись от этого ограничения, мы можем бросить все заботы и наблюдать за визуализацией кадров.
Кроме того, я отказался от простого вращающегося куба в сцене, выбрав что-то более веселое. Куб движется против часовой стрелки, положение и вращение зависят от музыки. По пути он оставляет своих клонов, которые постоянно выпадают из камеры, их масштаб пульсирует в общий объем. Вращение привязано к объему канала, и им назначаются случайные скорости x, y и z (привязанные к разным спектральным диапазонам) при их рождении. И, наконец, камера вращается по оси z, скорость ее вращения также регулируется громкостью, поэтому толчок заставляет все вращаться немного быстрее, а тишина заставляет все замедляться.
Во всяком случае, вот этот цикл рендеринга:
// The render loop
var done = false;
var frame = 0;
var clones = [];
var i;
function render() {
if (!done) {
// Tie cube location to audio low, mid, high and l/r averages
// Also, rock it around the clock
var radius = 2;
var angle = frame.mod(360);
var newX = (radius + audioVO.audioHigh) * Math.cos(angle / audioVO.audio_lAverage);
var newY = (radius + audioVO.audioMid) * Math.sin(angle / audioVO.audio_rAverage);
var newZ = (radius - audioVO.audioBass) / Math.tan(angle * audioVO.audioVolume);
cube.position.set(newX, newY, newZ);
// Tie rotation to averages
cube.rotation.x += audioVO.audio_lAverage;
cube.rotation.y += audioVO.audio_rAverage;
// Tie cube scale to audio bass
var scale = (frame).mod(audioVO.audioBass);
var newScale = scale / audioVO.audioBass;
cube.scale.set(newScale,newScale,newScale);
// Throw the occasional clone
if (Math.floor(Math.random() * 2)){
var clone = new THREE.Mesh( geometry, material );
clone.scale.set(newScale / 5, newScale / 5, newScale / 5);
clone.position.set(newX, newY, newZ);
clone.rotation.x -= audioVO.audio_rAverage;
clone.rotation.y -= audioVO.audio_lAverage;
clone.velocity = {
x: (Math.random() * audioVO.audioBass)/2,
y: (Math.random() * audioVO.audioMid)/2,
z: (Math.random() * audioVO.audioHigh)/2
};
scene.add(clone);
clones.push(clone);
}
// Adjust the clones
for (i=0; i<clones.length; i++){
clone = clones[i];
clone.position.z -= (clone.velocity.z - angle.mod(-newZ / i));
clone.position.y += (clone.velocity.y + angle.mod(-newY / i));
clone.position.x -= (clone.velocity.x - angle.mod(newX / i));
newScale = audioVO.audioVolume.mod(i) / 2;
clone.scale.set(newScale, newScale, newScale);
}
// Kick the camera rotation based on volume
camera.rotation.z -= audioVO.audioVolume/2;
// Render and increment frame
requestAnimationFrame(render);
renderer.render(scene, camera);
frame++;
} else {
// Clear canvas after final frame is rendered
renderer.clear();
}
}
Актеры и коммуникационный протокол
Предыдущая демонстрация была посвящена одному: выяснить, можем ли мы рендерить и отправлять кадры на сервер в реальном времени. Обратная связь по процессу была минимальной, а протокол межкомпонентной связи — не очень. Все, что меняет это с обходом.
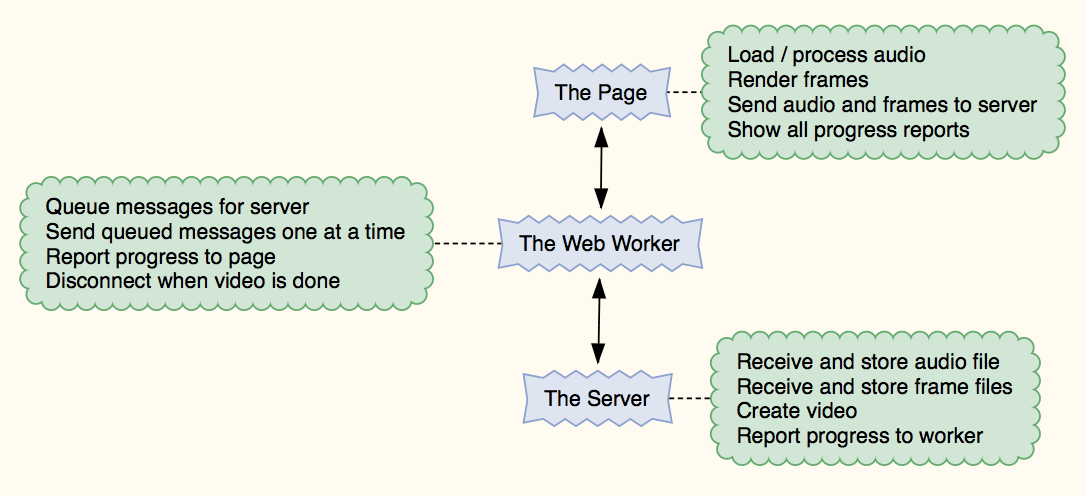
В системе есть три движущихся части:
- Скрипт на странице
- Веб-работник
- Скрипт сервера Node.js
У каждого есть свои обязанности, и нам нужно знать, что они правильно общаются друг с другом и действуют в соответствии с переданными сообщениями, как и ожидалось. За работающими отчетами журналов из всех трех частей системы трудно следить, поэтому я добавил местоположения отчетов о состоянии для всех трех участников в верхней части веб-страницы.
Сервер

Этот скрипт должен быть запущен до загрузки страницы браузера. Поскольку каждый клиент (сокетное соединение) имеет свой уникальный идентификатор, мы можем использовать его для разделения полученных и сгенерированных данных для одновременных клиентов. Этот скрипт сохраняет все входящие и сгенерированные данные в /var/tmp/test-av-server/‹client-id›/, создавая любые недостающие биты пути к папке на лету, по мере необходимости.
С помощью Socket.io серверный скрипт начинает прослушивать настраиваемый порт, а при получении соединения устанавливает прослушиватели для следующих сообщений:
- frame — свойство data этого сообщения представляет собой двоичный фрагмент, который нужно сохранить как изображение .png. У него также есть свойство порядковый номер, указывающее номер сохраняемого кадра. Сервер отвечает, сохраняя данные в файл в папке клиента, используя формат: frame_000000.png, заменяя числовую часть номером кадра, дополненным нулями.
- аудио — также имеет свойство data, двоичный фрагмент, который будет сохранен в виде аудиофайла с использованием имени, указанного в свойстве сообщения filename.
- done — это сообщение является просто уведомлением о том, что клиент завершил отправку кадров. В ответ сервер запускает команду FFMpeg для создания видео. Как и при нашей первой встрече с FFMpeg, я ставлю на видео водяной знак. Для демонстрации на этой странице я использовал один прозрачный PNG с названием моего проекта записи и названием трека, размещенным внизу видео.
- disconnect — отправляется автоматически при закрытии браузера, обновлении страницы или закрытии сокета клиентом. Когда это сообщение получено, сервер удаляет прослушиватели событий из объекта соединения. В реальном приложении он будет дополнительно очищаться после любого преждевременно прерванного разговора, полностью удаляя связанную временную папку. Для успешного обмена он удалит только кадры и звук, оставив полученное видео для последующего просмотра и загрузки на видеосайты, такие как YouTube.
После получения всех данных запускается процесс создания видео, и скрипт сервера отправляет следующие сообщения:
- video-progress — это сообщение имеет свойство data, которое представляет собой отформатированную строку, указывающую продолжительность видео, обработанного на данный момент. FFMpeg отправляет эти обновления довольно часто, поэтому клиенту не отправляются дубликаты.
- video-error — свойство data содержит дословную копию любой ошибки, о которой сообщает FFMpeg при попытке создать видео.
- video-done — это последнее сообщение, которое будет отправлено клиенту, а его свойство data содержит полный путь и имя файла завершенного видео.
Каждое сообщение также имеет свойство id, которое является уникальным идентификатором клиента. Обработчики сообщений frame и аудио также вызывают функцию обратного вызова, переданную клиентом, для подтверждения получения сообщения.
Веб-работник
Работая в отдельном потоке от сценария на странице, основная обязанность рабочего сценария заключается в обработке связи между страницей и сервером. Поскольку большинство сообщений, поступающих со страницы, содержат большие фрагменты данных, рабочий процесс ставит в очередь все исходящие сообщения, отправляя следующий элемент очереди только после получения подтверждения от сервера о том, что предыдущее сообщение благополучно доставлено. Информация об этих передачах и подтверждениях передается обратно на страницу для отчета о состоянии.
Когда веб-воркер получает от сервера сообщение video-done или video-error, он перенаправляет их на страницу для отчета, а затем закрывает сокет и себя.
Страница
Этот скрипт имеет довольно длинный список обязанностей:
- Создайте веб-воркера
- Разрешить пользователю выбирать аудиофайл
- Загрузите аудиофайл
- Создайте конвейер узлов и фильтров API веб-аудио для воспроизведения и анализа аудиоконтента.
- Отправить аудиофайл на сервер (через сообщение воркеру)
- Делайте покадровые снимки низких, средних и высоких частот, а также левой, правой и общей громкости.
- Заполните все пробелы в снимках
- Отменить все первоначальные молчаливые снимки
- Настройте 3D-сцену, камеру, средство визуализации и т. д.
- Рендеринг кадра для каждого снимка в списке
- Отправлять каждый кадр на сервер (опять же, через воркер)
- Сообщайте пользователю обо всех действиях в отдельных строках состояния для страницы, воркера и сервера.
Разговор
Ниже приведены ключевые поворотные моменты разговора, происходящего между этими актерами, когда они занимаются своими делами:
Шаг 1. Запрос аудиофайла

Шаг 2 — Обработка аудио

Шаг 3 — Рендеринг кадров

Шаг 4 — Создайте видео

Шаг 5 — Миссия выполнена
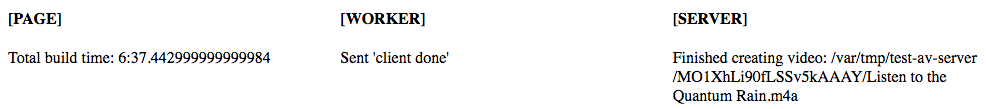
Вывод
Теперь у нас есть жизнеспособный процесс рендеринга и сборки, который дает законченное видео 48 FPS, 1080p HD, готовое для загрузки на YouTube. Этот процесс достаточно надежен для демонстрации и не требует огромных настроек, чтобы применить извлеченные здесь уроки к нашему реальному приложению.
В демоверсию включена страница предварительного просмотра в реальном времени (которая позволяет быстро протестировать обработку и рендеринг звука), страница записи (которая занимает где-то около 13 секунд на кадр для создания окончательного видео после загрузки звука), рабочий процесс. (отличный скелет для обработчика протокола передачи сообщений), а также код сервера, включающий пакет json, в котором объявляются зависимости, необходимые для запуска его в Node. Поскольку задействовано много кода, вы можете взять его из этого GitHub Gist.
Надеюсь, вам понравились эти отчеты, и я снова сообщу вам после нашей следующей важной вехи.
Примечание автора.Эта статья является частью серии, в которой мой партнер и я тестируем разработку нашего продукта "на открытом воздухе".
Это диаметрально противоположно моему типичному подходу «работы скунса», заключающемуся в том, чтобы месяцами сидеть взаперти в бессмысленных попытках сохранить в секрете то, что в конечном итоге все равно станет достоянием общественности. Мы не строим ничего ошеломляющего, изменяющего парадигму или строящего империю. Просто что-то классное, что служит нише, которую мы знаем и заинтересованы в помощи. Это визуализатор 3D-музыки, созданный на HTML5/WebGL с использованием Three.js, PureMVC, React и Node.js. Когда мы закончим, вы сможете создать классное видео для своей аудиодорожки и загрузить его на YouTube.
Преимущество ведения блога об этом в том, что у нас есть возможность передать некоторые из наших мыслительных процессов, когда мы преодолеваем препятствия и выбоины, разбросанные по нашему пути. Изложение этих мыслей, пока они еще свежи в памяти, может направить кого-то другого на тот же путь. Если мы потерпим неудачу из-за этих решений, возможно, это поможет вам избежать собственного дымящегося кратера. В любом случае, позже мы будем заняты погоней за разными белками в каком-нибудь другом парке.
The previous article in this series is: WebGL Performance Challenge: Render Thirty Frames per Second and Send them to the Server This article has been reblogged at the following sites: DZone: http://bit.ly/break-free-of-the-realtime-jail