
В этом посте описываются методы, используемые для построения модели определения ключевых точек лица в рамках программы Udacity AI Nanodegree. Код, используемый для этого проекта, можно рассматривать как записную книжку Jupyter. Полную версию проекта можно посмотреть здесь. Если вам нужен доступ к собственно записной книжке, их можно найти в репозитории GitHub проекта.
Обзор
В этом последнем проекте для AIND от Udacity цель состояла в том, чтобы создать модель определения ключевых точек лица. Затем эта модель была интегрирована в полный конвейер, который берет изображение, идентифицирует любые лица на изображении, а затем определяет ключевые точки этих лиц.
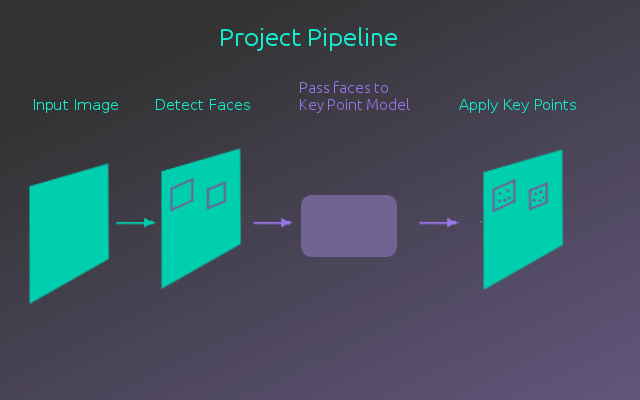
Предварительная обработка с OpenCV
Частью этого проекта было знакомство с библиотекой OpenCV. В частности, чтобы использовать его при предварительной обработке входных изображений. В случае этого проекта он использовался для преобразования изображения в оттенки серого и обнаружения лиц на изображении. Еще одна полезная функция OpenCV - размытие по Гауссу, которое можно использовать для сокрытия личности обнаруженного лица.
На следующем рисунке показан результат применения функции обнаружения лица и размытия по Гауссу к изображению.

Используя детектор лиц из библиотеки OpenCV, лица на изображении можно затем обрезать, чтобы загрузить в модель обнаружения ключевых точек.
Набор данных
Для обучения модели обнаружения ключевых точек использовался набор данных лиц с соответствующими метками ключевых точек. Этот набор данных взят из Kaggle, состоящий из изображений лиц в градациях серого 96x96 с 15 координатами (x, y), обозначающими ключевые точки лица. Исходный набор данных содержал 7049 изображений, однако не все изображения имели полные 15 меток ключевых точек. Чтобы справиться с этим, использовались только изображения с полными 15 ключевыми точками. В результате осталось 2140 изображений, 500 из которых были разбиты на тестовый набор. На следующем рисунке показан образец набора данных.

Увеличение
При относительно небольшом обучающем наборе из 1640 изображений данные были расширены несколькими способами, чтобы увеличить количество примеров изображений, на которых модель могла бы учиться. Это было немного усложнено из-за того, что нужно было не только расширить входные изображения, но также необходимо было расширить метки ключевых точек, чтобы они соответствовали одной и той же точке на недавно увеличенном изображении. Были применены два типа дополнений, код, описывающий этот процесс, можно найти в блокноте проектов Jupyter.
Переворот по горизонтали. Это было относительно просто. Значения x изображений и ключевых точек отражались над центром изображения. Ключевые точки, соответствующие левой стороне лица, были заменены соответствующей правой ключевой точкой. Это удвоило обучающие данные. Ниже приведен пример горизонтального переворачивания.

Поворот и масштабирование. Поворот и масштабирование были немного сложнее, но благодаря OpenCV было легко построить матрицу поворота / масштабирования, которая применялась как к изображению, так и к его ключевым точкам. Добавление повернутой / масштабированной версии набора данных к обычному набору данных снова удвоило обучающие примеры. Ниже приведен пример этого дополнения.

После пополнения исходного набора данных у модели было 6560 примеров для обучения.
Построение модели
Архитектура, использованная для этой модели, была основана на модели VGG16, сверточной нейронной сети, построенной для классификации в ImageNet. Модель VGG16 использует 5 сверточных блоков для извлечения функций из изображения. Эти блоки состоят из нескольких сверточных слоев, за которыми следует слой максимального объединения, где размеры изображения уменьшаются вдвое. В модели, используемой для этого проекта, каждый сверточный блок имеет только один сверточный слой. Причина этого заключается в том, что при ограниченном объеме данных более простая модель с меньшей вероятностью переборщила.
Помимо использования меньшего количества сверточных слоев, к первым трем сверточным блокам добавлялись выпадающие слои со скоростью выпадения 20%, а слои пакетной нормализации добавлялись после каждого сверточного слоя. Оба этих новых метода отсутствовали в исходной сети VGG16 и помогают предотвратить чрезмерную подгонку.
Используя эту архитектуру для извлечения функций изображения, выходные данные сверточных слоев подавались на слой Global Average Pooling, а затем на полностью связанный выходной слой из 30 узлов (значения x, y для каждой из 15 ключевых точек). На следующем рисунке показана полная архитектура модели.
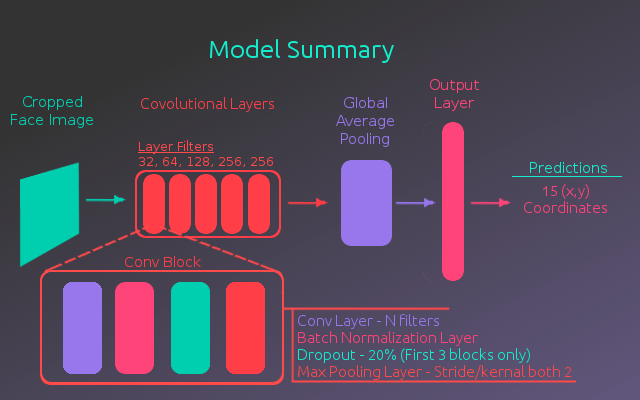
Обучение
Для обучения модели потери были рассчитаны с использованием среднеквадратичной ошибки помеченных ключевых точек и прогнозируемых ключевых точек. Было обнаружено, что оптимизатор Adam дает наилучшие результаты. Также было обнаружено, что наименьшие потери были достигнуты за счет увеличения размера пакета и скорости обучения. Начиная со скоростью обучения 0,001, модель обучалась в течение 15 эпох с размером пакетов 32, 64 и 128. Это было повторено для скорости обучения 0,0001 и 0,00001. Причина в том, что при меньшем размере пакета шаг градиентного спуска более стохастический (более случайный), поскольку он усредняется по меньшему количеству примеров. Когда оптимизация достигает минимального значения, шаги параметра должны представлять более общее решение, обеспечиваемое взятием среднего градиента для большего размера партии.
На следующих рисунках показаны тренировочные кривые, причем последние показывают более близкое представление последних эпох. Как вы можете видеть в последние эпохи, шаги в потере обучения производятся увеличением размера пакета для каждой скорости обучения.
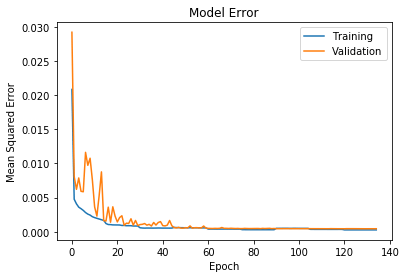
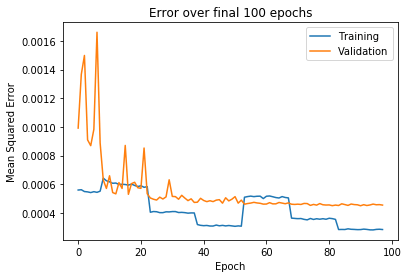
Псевдо-маркировка
После первого раунда обучения модель относительно точна. Чтобы использовать все данные в исходном наборе данных, обученная модель использовалась для прогнозирования ключевых точек для недостающих значений и использования их в качестве меток. По сути, в наборе данных было большое количество неполных примеров, которые были выброшены, но в них все еще была полезная информация по ключевым моментам, которые у них были. Чтобы извлечь уроки из этой информации, модель заполнила неполные точки своим лучшим предположением.
Взяв псевдо-помеченный полный набор данных и расширив его, как и раньше, был создан новый обучающий набор данных с 29520 примерами. Затем модель продолжила обучение на этом наборе данных, после чего последовал еще один цикл обучения на исходном полностью размеченном наборе данных. В конечном итоге ошибка модели была обучена ниже 0,0005. Я был очень доволен этим, поскольку в блокноте проекта говорилось: «Очень хорошая модель дает потерю около 0,0015». Кроме того, при нанесении на тестовые изображения прогнозы ключевых точек оказываются там, где вы ожидаете.
Резюме
После обучения модели обнаружения ключевых точек детектор лиц и модель были объединены, чтобы применить ключевые точки к лицам на изображении. На следующем рисунке показан пример продукта этого процесса.

Кроме того, модель была расширена для работы с веб-камерой и использования ключевых функций для применения фильтра маски (в данном случае солнцезащитные очки).

Я был в восторге от результатов этого проекта. Используя простую сверточную архитектуру с некоторыми обновленными методами, увеличением данных и псевдо-метками, эта модель смогла дать полезные результаты на относительно небольшом наборе данных.
Первоначально опубликовано на macbrennan90.github.io.