В последнее десятилетие с достижениями в области открытого банковского обслуживания и быстрым ростом агрегаторов данных данные о транзакциях превратились из простой записи финансовой деятельности в богатый вспомогательный слой для множества продуктов и услуг, предлагаемых конкурентами в сфере финансовых технологий и даже технологическими компаниями. вне финансового пространства.
Финансовые операции - один из самых богатых источников информации как о поведении потребителей, так и о поведении бизнеса. Тем не менее, понимание этих данных в масштабе все еще остается нерешенной проблемой. Вот почему.
В США насчитывается более 10 тысяч финансовых организаций, и каждое из них может свободно выбирать информацию, которую они включают в описание каждой транзакции, и то, как они представляют ее.
Давайте посмотрим на пример:

Здесь мы показываем только некоторые из основных функций для одной транзакции, необработанное описание, направление и сумму. Хотя это на первый взгляд загадочно, это технически возможно для человека прочитать, если учесть достаточный опыт, доступ к Интернету, коммерческим базам данных и различным поисковым таблицам. Однако модель машинного обучения может быть на много порядков быстрее, дешевле, надежнее и, если обучающие данные не содержат систематического шума, даже более точной.
Чтобы модель могла анализировать и извлекать из нее значимую информацию, помимо информации о различных продавцах, платежных системах, именах людей, адресах, словах услуг и т. Д., Она должна иметь возможность адаптироваться к произвольным изменениям в формате; разрешать между сущностями с похожими именами в зависимости от контекста; из заданного списка возможных меток назначьте соответствующие; угадайте значение сокращений, которых он раньше не видел, и многое другое.
В прошлом были испробованы различные подходы к программному синтаксическому анализу транзакционных данных.
Хотя большинство из них работают в 75% случаев с одним из нескольких тысяч крупнейших продавцов, до сих пор ни одно решение не было успешным для семейных магазинов, небольших магазинов, недавно открывшихся предприятий и других небольших и менее популярных учреждений. . Действительно, имея доступ только к единственному источнику данных внутри финтех-компании, почти невозможно избежать уязвимости в длинном хвосте. Может показаться целесообразным охват только основных продавцов и типов транзакций, но издержки от промахов намного превышают выгоды от попаданий. Потеря денег по нераспределенной бизнес-ссуде, демонстрация человеку неправильной разбивки расходов или неправильный расчет квартальной налоговой декларации может привести к значительным неудачам для финансовых компаний и их клиентов. Чтобы быть надежными, нам нужна постоянная ›95% -ная точность выходных данных моделей не только для общих случаев, но и для« длинного хвоста ».
Чтобы достичь такого уровня производительности в Ntropy, мы решаем проблему, комбинируя данные из всей нашей сети клиентов с предварительно обученными встраиваемыми языками, данными из поисковых систем, контекстными пользовательскими функциями и другой вспомогательной информацией. Многое из этого стало возможным лишь совсем недавно, параллельно с достижениями в обобщении задач, активном обучении, масштабируемой маркировке данных услуги и методах сохранения конфиденциальности.
Ниже представлен обзор нашей текущей архитектуры:
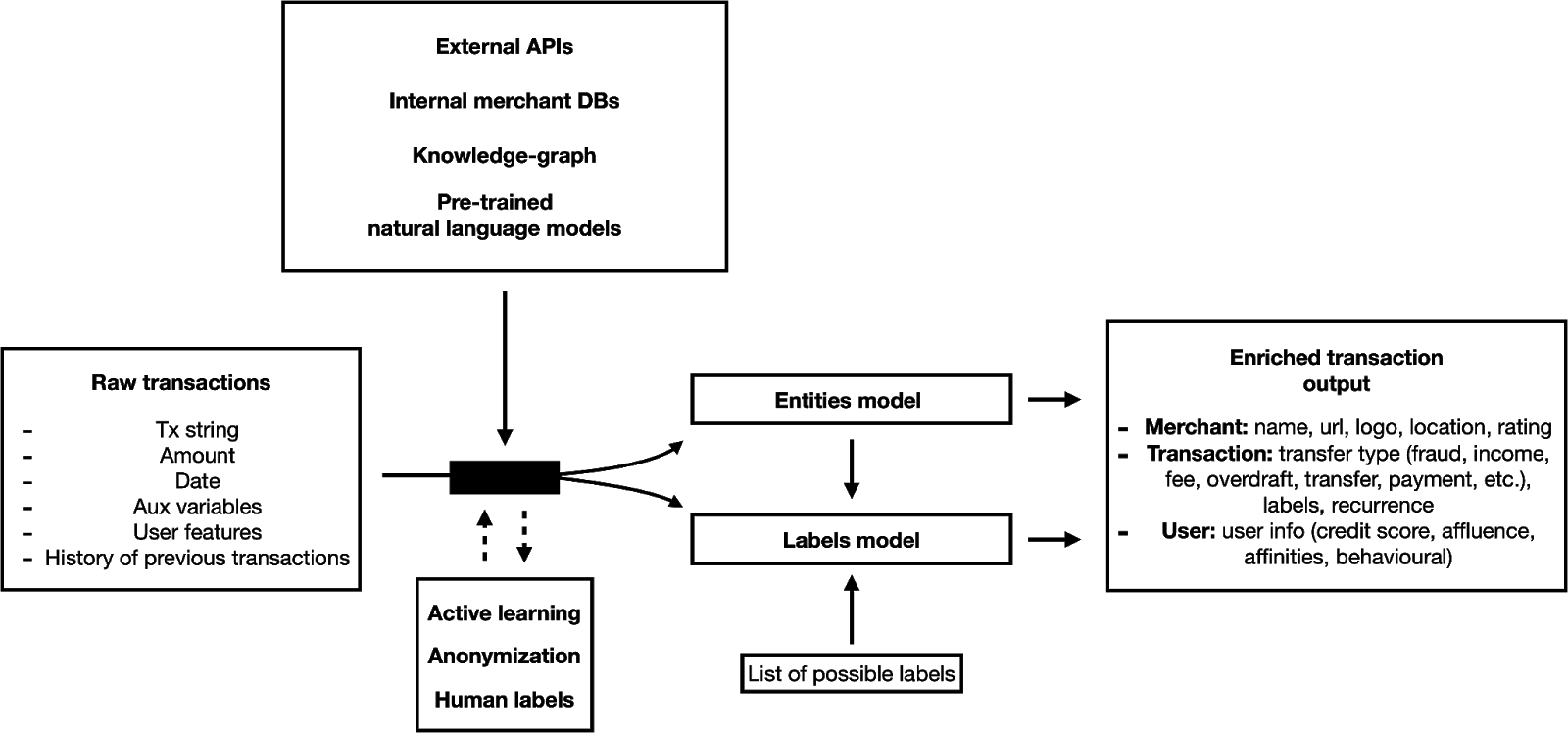
Конвейер преобразует необработанные потоки транзакций в контекстуализированную структурированную информацию, которая может быть непосредственно проанализирована как людьми, так и машинами. Он обеспечивает гораздо более широкое контекстное понимание каждой транзакции, чем это возможно с помощью всего лишь одного набора данных или эвристики, и, как показали некоторые тесты, превосходит даже людей-верификаторов.
В нашем предыдущем посте мы представили домен естественного языка как надежный носитель информации между моделями машинного обучения в организациях и барьерами конфиденциальности. В масштабе он может позволить моделям получать доступ к релевантным данным практически во всех отраслях, от сельского хозяйства до здравоохранения. По мере развития модели мы стремимся абстрагироваться от жесткой схемы для всех входных и выходных функций, чтобы сделать ее тривиальной для обобщения на другие области.
Чтобы ускорить внедрение этого подхода, мы со временем будем открывать исходный код для частей нашего стека, включая активную среду обучения, инструменты конфиденциальности, обученные модели, подходы для быстрой разработки и многое другое.
Спасибо моим коллегам-тропистам (в алфавитном порядке) Дэвиду Бухманну, Чады Димачкие, Джонатану Кернесу и Наре Варданян за их вклад в этот пост. Если вы инженер машинного обучения или бэкэнд-инженер, взволнованный нашей миссией, мы нанимаем вас и будем рады услышать от вас. Недавно мы опубликовали наш API, и ключ можно запросить здесь.