
Временной ряд — это набор наблюдений, сделанных в определенный период времени. Прогнозирование временных рядов относится к использованию статистических моделей для прогнозирования будущих значений с использованием ранее записанных наблюдений. В целом его можно разделить на две части:
- Прогнозирование одномерных временных рядов. Включает одну переменную.
- Многомерное прогнозирование временных рядов: задействует несколько переменных.
Построение модели статистического прогнозирования часто включает стандартную процедуру. На изображении ниже показаны шаги, которые необходимо выполнить для построения модели прогнозирования. В этом руководстве мы будем использовать алгоритм ARIMA, который широко используется в краткосрочных прогнозах.
Давайте углубимся в анализ данных:

Анализ данных
В этом уроке мы будем использовать набор данных авиапассажиров, доступный на Kaggle. Это достаточно простые временные ряды данных с признаками Временная метка и Количество пассажиров. Он содержит около 144 рядов и охватывает 11 лет пассажиропотока.
Давайте посмотрим на тенденцию.
import pandas as pd
import plotly.express as px
air_passengers = pd.read_csv('AirPassengers.csv')
fig = px.line(air_passengers, x='Month', y="Passengers")
fig.show()

Разложение временных рядов
Понимание всего временного ряда может быть сложной задачей. К счастью, временной ряд можно разложить на комбинацию компонентов тренда, сезонности и шума. Эти компоненты обеспечивают ценную концептуальную модель для размышлений о прогнозировании временных рядов.
- Аддитивная декомпозиция. Предполагается, что временной ряд представляет собой линейную комбинацию тренда, сезонности и остатка.

- Мультипликативная декомпозиция. Предполагается, что временной ряд является продуктом тренда, сезонности и остаточного компонента.

Модель аддитивной декомпозиции предпочтительнее, когда сезонные колебания в некоторой степени постоянны во времени, тогда как мультипликативная модель полезна, когда сезонные колебания увеличиваются во времени. Для конкретного понимания посетите этот блог. Мультипликативный временной ряд можно преобразовать в аддитивный ряд с помощью логарифмического преобразования.
Yt = Tt * St * Rt
log(Yt) = log(Tt) + log(St) + log(Rt)
В нашем случае сезонность увеличивается со временем, поэтому мы должны использовать мультипликативную декомпозицию временного ряда. Давайте разложим наш временной ряд!
from statsmodels.tsa.seasonal import seasonal_decompose decomposed = seasonal_decompose(series, model='multiplicative') decomposed.plot()
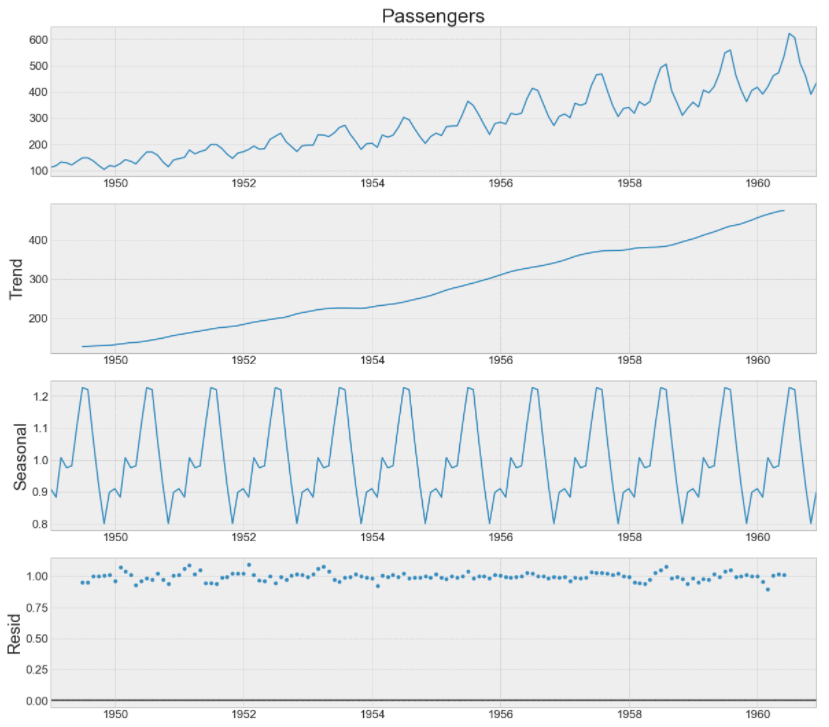
Из приведенной выше декомпозиции временного ряда мы можем сделать вывод, что временной ряд имеет период сезонности 1 год, и тенденция строго возрастает. У нас также есть некоторые остатки или шум в данных, которые мы попытаемся разрешить позже.
Стационарный тест

Прежде чем применять какие-либо модели прогнозирования к набору данных временных рядов, этот временной ряд должен быть стационарным. Временной ряд называется стационарным, если его статистические свойства (среднее значение, дисперсия и автокорреляция) не изменяются со временем на далекое значение.
Из приведенного выше графика временных рядов видно, что среднее значение нашего временного ряда со временем увеличивается. Мы знаем, что он не является стационарным, но давайте просто подтвердим это.
Существует несколько методов проверки стационарности временного ряда. Одним из таких методов является Тест Дики-Фуллера.
Примечание. Если временной ряд не является стационарным, мы можем доказать, что стандартные предположения для прогнозного анализа не будут считаться действительными.
Тест Дики-Фуллера:
Тест Дики-Фуллера — это тест статистической значимости, который дает результаты при проверке гипотез. Проверка гипотезы рассматривает нулевую и альтернативную гипотезы. Гипотеза, сделанная для теста Дики-Фуллера, выглядит следующим образом:
Нулевая гипотеза (H0): временной ряд не является стационарным.
Альтернативная гипотеза (Ha): временной ряд является стационарным.
В нулевой гипотезе мы сначала считаем, что данные временного ряда нестационарны, а затем вычисляем значение теста Дики-Фуллера (ADF). Если тестовая статистика теста Дики-Фуллера (ADF) меньше критического значения (значений), то отклонить нулевую гипотезу о нестационарности (ряд стационарен). Напротив, если ADF больше критического значения (значений), нам не удалось отвергнуть нулевую гипотезу (ряд нестационарен).
Проще говоря, тест ADF — это способ проверки стационарности временного ряда. Тест ADF сопоставляет временные ряды с разностными временными рядами с использованием модели линейной регрессии, и это помогает нам в вычислении t-статистики, которая совпадает со значением теста Дики-Фуллера (ADF). Затем это значение статистики t сравнивается с критическим значением (уровнями значимости) для получения результата.
Давайте проверим стационарность временного ряда с помощью теста Дики-Фуллера:
from statsmodels.tsa.stattools import adfuller result = adfuller(air_passengers["Passengers"]) print(‘ADF Statistic: %f’ % result[0]) print(‘p-value: %f’ % result[1]) print(‘Critical Values:’) for key, value in result[4].items(): print(‘\t%s: %.3f’ % (key, value)) if result[0] < result[4][“5%”]: print(“Reject Ho — Time Series is Stationary!”) else: print(“Failed to reject Ho — Time Series is not Stationary!”)

Наша серия нестационарна, что видно по самому тренду, но проверять вещи всегда хорошо. Нам нужно применить некоторые операции, чтобы сделать ряд стационарным. Есть несколько вариантов сделать серию стационарной:
- Разность временных рядов
- Трансформация силы
- Разность первого порядка
- Преобразование журнала
Не существует идеального способа сделать ряд стационарным. Поиск оптимального преобразования требует эмпирического процесса проб и ошибок. Мы будем использовать метод разности, который представляет собой не что иное, как получение разности Y(t)-Y(t-1). Эта операция обычно приводит к стационарному временному ряду. Если нет, мы можем снова применить разность к уже разным временным рядам.
Давайте реализуем разность для нашего временного ряда:
differenced = air_passengers["Passengers"].diff().dropna() fig = px.line(differenced) fig.show()
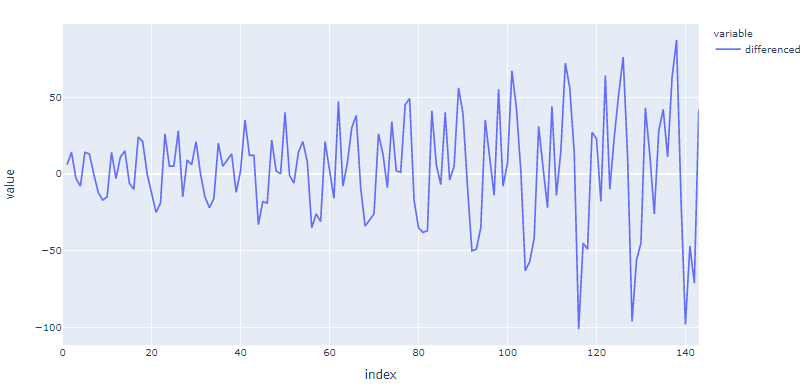
На этот раз разностные временные ряды кажутся стационарными. Мы можем снова применить тест Дики-Фуллера, чтобы подтвердить стационарность разностных временных рядов.
АРИМА
Теперь, когда у нас есть стационарный ряд, мы можем двигаться дальше с нашими моделями прогнозирования. Мы будем использовать модель ARIMA, которая означает авторегрессивную интегративную скользящую среднюю для прогнозирования. Это обобщенная версия модели ARMA и просто комбинация двух разных авторегрессивных и скользящих средних. модели.
Разберемся по компонентам:
Авторегрессионный (AR(p)). Авторегрессионная модель прогнозирует значение в текущей временной метке с помощью уравнения регрессии, полученного на основе значений в предыдущие временные метки. Только прошлые данные используются для прогнозирования значения в текущей отметке времени. Ряды, имеющие автокорреляцию, указывают на необходимость авторегрессионного компонента в ARIMA.

Интегративный (I(d)): этот компонент помогает сделать ряд стационарным с помощью дифференцирования. Разность — это просто операция, при которой наблюдение вычитается из наблюдения на предыдущем временном шаге. Эта операция делает временной ряд стационарным (удаляет компоненты тренда и сезонности из временного ряда). Мы уже применили его на последнем шаге.
Скользящее среднее (MA(q)). Модель скользящего среднего использует ошибки прошлых прогнозов в уравнении регрессии. Эта модель предполагает, что значение в текущей временной метке можно предсказать, используя ошибки прошлых прогнозов.

Интегрируйте все эти компоненты, чтобы сформировать уравнение ARIMA:
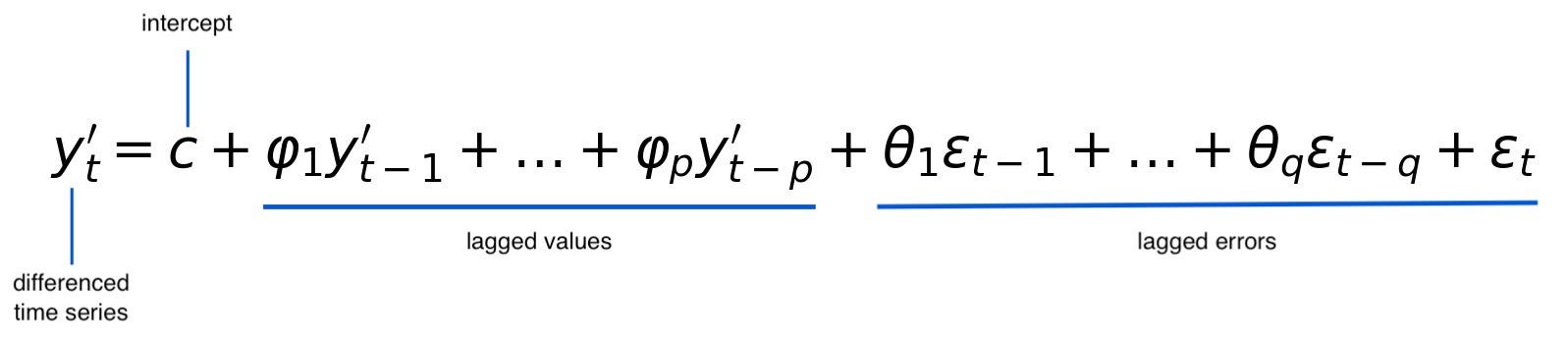
Как найти значения p, d, q?
При использовании модели auto-ARIMA гораздо проще найти оптимальную сезонную авторегрессионную составляющую (p), разностную составляющую (d) и составляющую сезонного скользящего среднего (q). Однако нас интересует ручное определение этих компонентов p, d, q.
Ниже приведены некоторые способы определения параметров p, d и q ARIMA:
- График автокорреляции помогает определить оптимальный набор параметров q для модели скользящего среднего.
- График частичной автокорреляции помогает определить оптимальный набор параметров p для авторегрессионной модели.
- Расширенный график автокорреляции данных подтверждает, требуется ли комбинация условий AR и MA для прогнозирования.
- Информационный критерий Акаике (AIC) помогает определить оптимальный набор p, d, q. Обычно предпочтение отдается модели с меньшим абсолютным значением AIC.
- Байесовский информационный критерий Шварца (BIC) является еще одной альтернативой AIC, и более низкий BIC лучше подходит для выбора оптимальных p, d, q.
Нахождение набора значений p и q:
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf plot_acf(air_passengers["Passengers"].diff().dropna()) plot_pacf(air_passengers["Passengers"].diff().dropna()) plt.show()

Чтобы найти компонент AR p, нам нужно найти резкое начальное падение на графике частичной автокорреляции. Это происходит сразу после первого пика. Таким образом, значение компонента p может иметь значение 1 или 2.
Чтобы найти значение q, нам нужно будет увидеть экспоненциальное уменьшение графика автокорреляции. Мы не ищем радикальных перемен; вместо этого мы ищем кривую, устанавливающуюся до насыщения. Мы можем видеть, что это происходит сразу после 1. Таким образом, q также можно принять либо за 1, либо за 2.
Давайте реализуем модель ARIMA(1, 1, 1):
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(air_passengers['Passengers'].diff(), order=(1,1,1))
results_ARIMA = model.fit()
plt.plot(air_passengers['Passengers'].diff())
plt.plot(results_ARIMA.fittedvalues, color='red')
print('Plotting ARIMA model')
print(results_ARIMA.summary())


residuals = pd.DataFrame(results_ARIMA.resid) residuals.plot(kind='kde') plt.show()

Среднее значение остатков приблизительно сосредоточено вокруг нуля, метрики AIC и BIC указывают на нормальное соответствие, а наш порядок ARIMA является оптимальным в соответствии с ACF и PACF. Но полагаться на PACF и ACF для нахождения оптимальных p и q часто не удается, поскольку истинный потенциал модели ARIMA не соответствует действительности. Мы всегда можем настроить параметры и посмотреть, дают ли они хороший прогноз проблемы, вместо того, чтобы следовать обычным правилам. Попробуем другую комбинацию:
model = ARIMA(air_passengers['Passengers'].diff(), order=(4,1,4))
results_ARIMA_updated = model.fit()
plt.plot(air_passengers['Passengers'].diff())
plt.plot(results_ARIMA_updated.fittedvalues, color='red')
print('Plotting ARIMA(4,1,4) model')
print(results_ARIMA_updated.summary())


residuals = pd.DataFrame(results_ARIMA_updated.resid) residuals.plot(kind='kde') plt.show()

ARIMA(4, 1, 4) немного лучше, чем ARIMA(1, 1, 1). Давайте также реализуем сезонный ARIMA, который аналогичен модели ARIMA, но также учитывает сезонность.
import statsmodels.api as sm model=sm.tsa.statespace.SARIMAX(air_passengers['Passengers'],order=(7, 1, 7),seasonal_order=(1,1,1,12)) results=model.fit() air_passengers['forecast']=results.predict(start=120,end=145) air_passengers[['Passengers','forecast']].plot(figsize=(12,8))

Сильные стороны и ограничения ARIMA
Ограничения:
- Прогнозы ненадежны для расширенного окна
- Данные должны быть одномерными
- Данные должны быть стационарными
- Выбросы сложно прогнозировать
- Плохо предсказывает поворотные моменты
Сильные стороны:
- Высоконадежные прогнозы на короткое окно
- Краткосрочные прогнозы часто превосходят результаты сложных моделей, но это также зависит от данных.
- Легко реализовать
- Беспристрастный прогноз
- Реалистичные доверительные интервалы
- Высокая интерпретируемость
Другие модели прогнозирования
- Экспоненциальное сглаживание
- Динамическая линейная модель
- Линейная регрессия
- Модели нейронных сетей
Возможные вопросы интервью
Задачи временных рядов довольно известны и очень полезны в разных отраслях. Интервьюеры задают вопросы о временных рядах в двух случаях:
- Если мы написали какой-то проект по временным рядам в нашем резюме.
- Если интервьюер хочет нанять вас для проекта временных рядов.
Вопросы по этой теме будут либо общими, освещенными в этом блоге, либо очень специфическими для наших проектов. Возможные вопросы по этой теме могут быть:
- Что такое данные временных рядов и чем они отличаются от других наборов данных?
- Что такое метод прогнозирования? Можете ли вы назвать некоторые популярные приложения этого?
- Зачем нам нужно декомпозировать набор данных временных рядов и каковы возможные способы?
- Что означает стационарный тест в наборах данных временных рядов?
- Что такое модель ARIMA и что мы делаем, чтобы найти значение параметров, участвующих в этом алгоритме?
Заключение
В этой статье обсуждались основные сведения о данных временных рядов и моделях прогнозирования. Мы играли с реальными данными, изучая стационарное тестирование, разность временных рядов и методы декомпозиции данных. После этого мы построили и оценили нашу модель ARIMA. Надеемся, вам понравилась эта статья.
Наслаждайтесь обучением! Наслаждайтесь алгоритмами!