Топ-5 профессиональных советов по решению самой распространенной проблемы в науке о данных

Замена отсутствующих значений может показаться тривиальной, но это может быть самый важный шаг в процессе машинного обучения. То, как вы это делаете, может оказать большое влияние на вашу модель машинного обучения.
Кроме того, поскольку вы будете создавать некоторые новые данные, у вас есть некоторые важные обязанности по отношению к отделам данных в организации. Данные — один из самых важных активов. Таким образом, как специалист по данным, если вы создаете новые данные, используя замену отсутствующих значений, вам придется обосновывать вывод с деловыми людьми.
В этой статье я покажу вам 5 лучших советов по замене недостающего значения, чтобы вы выглядели как профессионал в такой важной теме. Я буду использовать алгоритм K-Nearest Neighbor (KNN) в качестве алгоритма замены отсутствующего значения. Однако советы применимы и к другим методам замены отсутствующих значений.
Позвольте мне начать с набора данных, который я буду использовать в этой истории. Я нашел один очень интересный набор данных на Kaggle под названием Spaceship Titanic (ссылка на источник данных доступна в конце статьи). Это данные, основанные на фантастическом рассказе. Космический корабль «Титаник» был межзвездным пассажирским лайнером, в который попала аномалия пространства-времени. Хотя корабль остался цел, почти половина пассажиров была перенесена в другое измерение!

Звучит знакомо с проблемой Титаника, но она более футуристична! Данные содержат сведения о пассажирах, такие как родная планета, пункт назначения, возраст и различные услуги. Во многих столбцах отсутствуют значения. Итак, теперь давайте перейдем к основным советам, которые помогут вам заменить недостающую ценность.
1. Определите и определите, чего не хватает
Лучший способ определить и определить, что является недостающим значением, — это сделать визуализацию. Он избегает использования каких-либо предубеждений. Вот гистограмма поля родной планеты. Тот факт, что чего-то не хватает, бросается в глаза. Это хороший способ идентифицировать и определить недостающее значение. Можно сказать, что отсутствующее значение является пустым. Поскольку у каждого пассажира есть родная планета, нам нужно заменить пробел на какое-то значение.

Аналогичная гистограмма для числового столбца «Обслуживание номеров» и «Возраст» показана ниже.
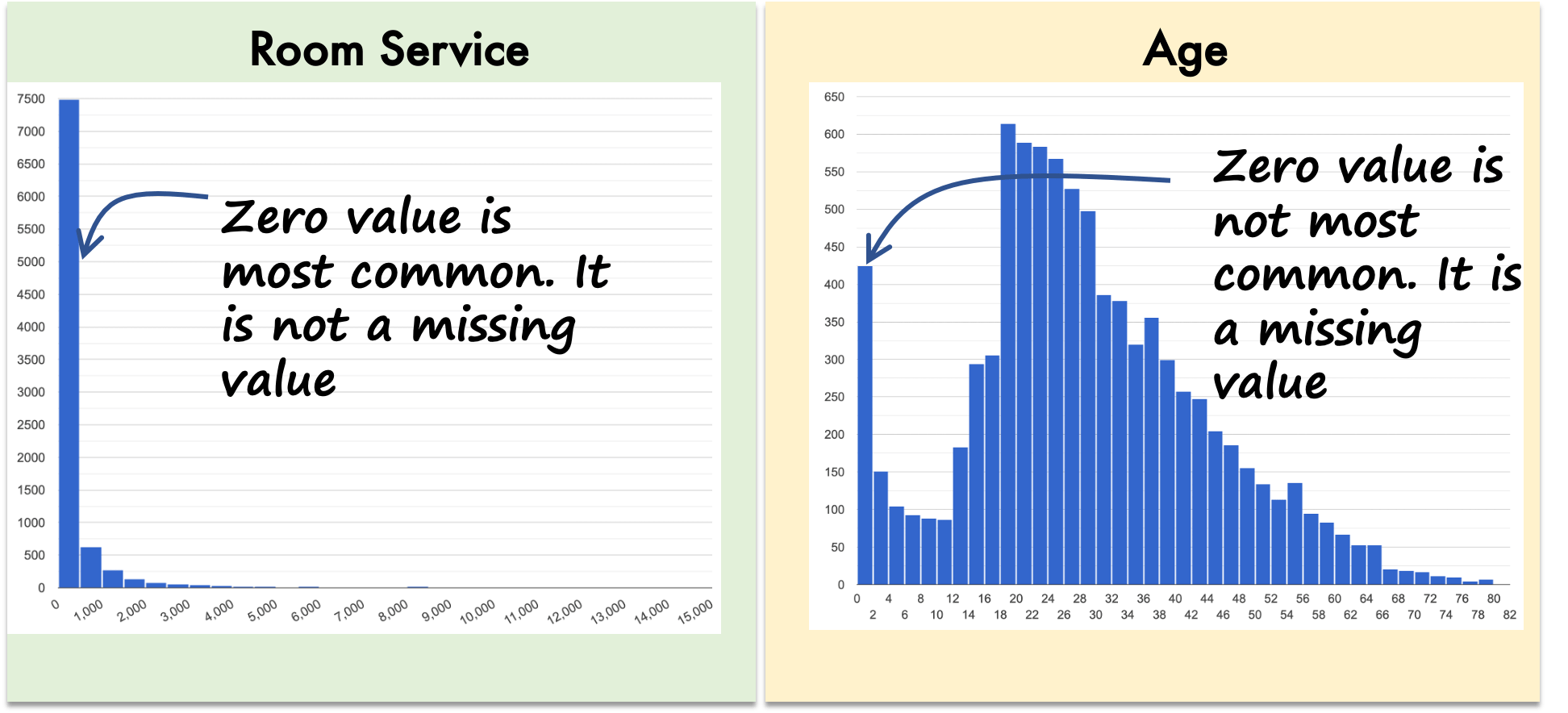
Для обслуживания номеров нулевые значения очень распространены. Это нормально, так как не все пассажиры пользуются обслуживанием номеров. Однако для возраста существуют нулевые значения, и они не самые распространенные. Несмотря на то, что мы в будущем, я уверен, что нерожденные люди не считаются пассажирами! Таким образом, нулевое значение для возраста определенно является отсутствующим значением.
2. Определить долю пропущенных значений по отношению к целевой переменной
Как правило, усилия по отсутствию ценности выполняются в контексте машинного обучения. Поэтому важно проверить отсутствующее значение по отношению к целевому классу. Замена отсутствующих значений обычно работает хорошо, если распределение данных относительно целевого класса остается сбалансированным.
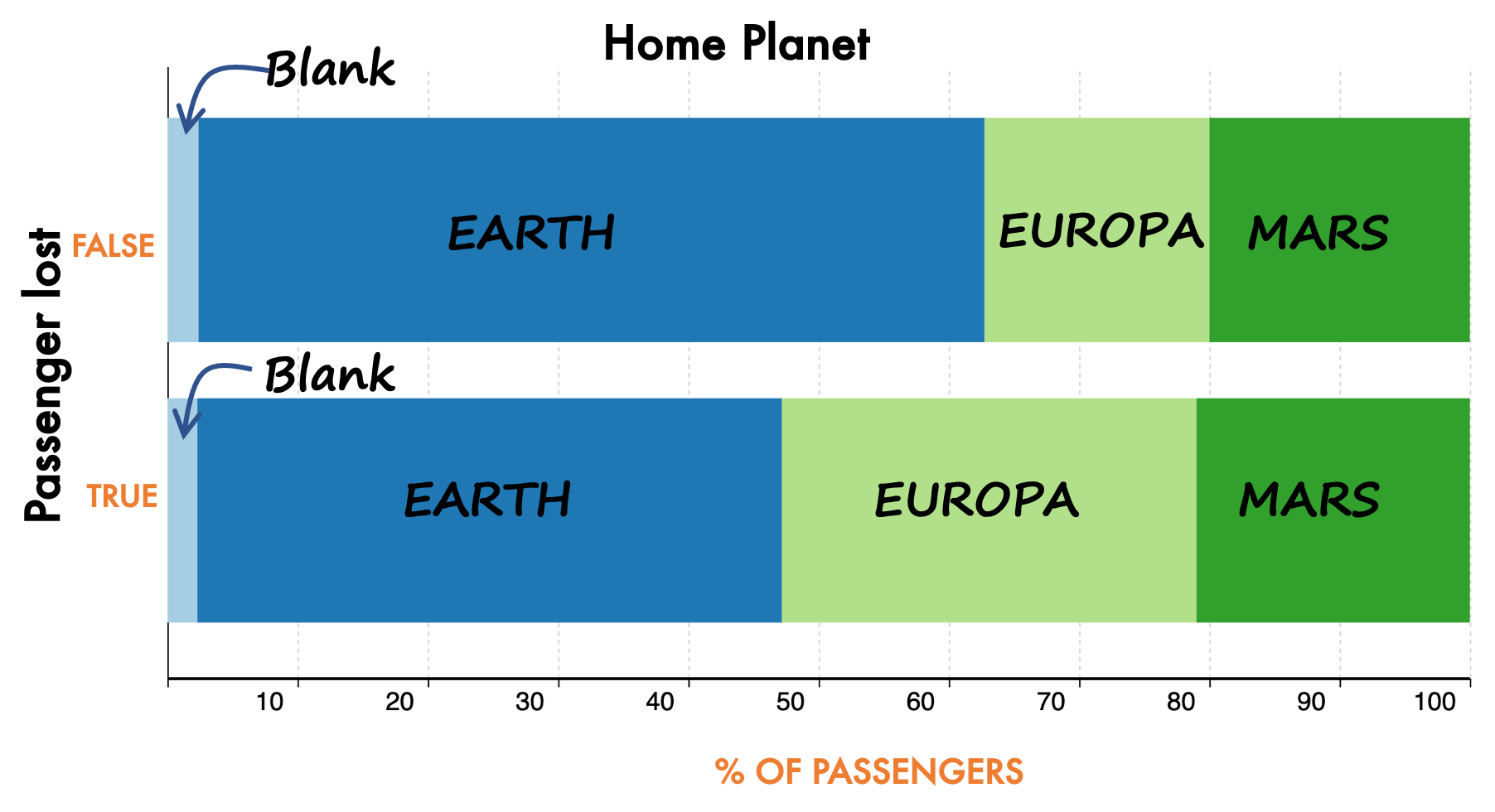
Целевая переменная в наборе данных — это потеря пассажира из-за того, что его перевезли в другое измерение. Визуализация ниже показывает распределение Родной планеты относительно целевой переменной. Мы можем заметить, что доля пустых значений одинакова для обоих целевых классов. Кроме того, доля пропущенных значений очень меньше. Это означает, что замена отсутствующих значений не приведет к радикальному изменению формы данных. Это хорошая новость, и мы можем быть уверены в том, что донесем информацию об упущенной ценности до специалистов по данным и бизнесу. Это не вызовет паники у богов данных внутри компании!
Мы проводим аналогичный анализ для числового столбца «Возраст», используя анализ коробчатой диаграммы, как показано ниже. Вы заметите, что блочная диаграмма для обоих целевых классов более или менее похожа. Кроме того, нулевое значение, которое необходимо заменить, далеко от медианы. Это означает, что нулевых значений не так много. Итак, еще раз, мы не будем кардинально менять форму данных и, таким образом, радовать богов данных в компании!

3. Сделайте до и после проверки алгоритма замены
Теперь все готово для замены отсутствующих значений в полях Родная планета и Возраст. Одним из очень эффективных алгоритмов для этой работы является алгоритм K-ближайших соседей (KNN). Алгоритм попытается найти ближайшего соседа для записей с пропущенными значениями. Для числовых значений он заменяется средним значением ближайших соседей. Для категориальных значений он заменит наиболее распространенные значения.
После выполнения алгоритма очень полезно провести анализ тепловой карты того, сколько значений было заменено.

Мы можем заметить, что все отсутствующие значения для Age и Home Planet были заменены. Для обслуживания номеров и других полей мы не решили заменять отсутствующие значения, поэтому они остаются неизменными до и после.
4. Отлично, пропущенное значение заменено. Но с чем?
Отлично, алгоритм KNN сотворил чудо, заменив пропущенные значения. Но с чем? Мы можем быть уверены в алгоритме замены только в том случае, если понимаем, что такое значение после замены.
Этот шаг зависит от того, какой алгоритм вы использовали. В этой статье я использовал KNN, поэтому я укажу подход для этого алгоритма. Поскольку KNN основан на поиске ближайшего соседа, будет полезно иметь представление о том, каковы ближайшие соседи замененных значений. Одним из алгоритмов, который может помочь визуализировать «близость», является алгоритм уменьшения размерности TSNE (t-распределенное стохастическое соседнее встраивание).
Здесь показаны результаты TSNE, нанесенные на двумерную диаграмму рассеяния.

Зеленые точки указывают на то, что в точке данных были отсутствующие значения, и она была заменена с использованием алгоритма KNN. Фиолетовые точки — это точки данных без пропущенных значений. Поскольку большинство зеленых точек окружено фиолетовыми точками, мы можем быть уверены в подходе KNN. Это означает, что KNN — хороший подход, поскольку ближайшие соседи для отсутствующих значений не слишком далеко.
Имеется изолированный кластер зеленых точек, который увеличен на рисунке ниже. При ближайшем рассмотрении видно, что, несмотря на то, что это изолированный кластер, есть несколько соседей, которые помогли заполнить недостающие значения.

Мы также можем проверить пропорцию на основе целевого класса и сравнить ее с более ранними результатами. Ниже показан анализ Родной планеты. Мы можем заметить, что пустые значения (4%) были заменены Землей (+2%), Европой (+%1) и Марсом (+1%). Это имеет смысл, поскольку большинство домашних планет соответствуют Земле, за которой следуют Европа и Марс.

Точно так же мы можем наблюдать, что большинство значений нулевого возраста были заменены возрастами 12–14 и 24–25 лет. Общая гистограмма практически не изменилась, что не может не радовать.

5. Убедитесь, что замена отсутствующих значений улучшила модель.
Итак, настал момент, которого мы ждали. Нам нужно продемонстрировать, стоили ли того все усилия по управлению отсутствующим значением или нет. Лучший способ показать это — дважды обучить и протестировать модель машинного обучения — до и после замены отсутствующих значений.

Показатель ROC повышается, а это означает, что все усилия по замене отсутствующих значений того стоят! Даже увеличение счета на 1% может помочь подняться на доске объявлений Kaggle и отдать должное пассажирам галактики!
Заключение
Таким образом, замена отсутствующего значения изменяет данные. Поэтому важно сделать это с достаточным количеством доказательств того, почему и что изменилось. 5 лучших советов, описанных здесь, помогут вам справиться с проблемой замены отсутствующего значения.
Посмотрите демонстрацию и попробуйте сами
Вы можете посетить мой веб-сайт, чтобы выполнить замену отсутствующих значений, а также другую аналитику без кодирования: https://experiencedatascience.com
Вот пошаговое руководство и демонстрация на моем канале Youtube. Вы сможете настроить демонстрацию под свои данные с нулевым кодированием.
Пожалуйста, подпишитесь, чтобы быть в курсе, когда я публикую новую историю.
Если вам нравится то, что вы читаете, вы также можете присоединиться к Medium по моей реферальной ссылке. Это прямой способ поддержать меня, и я буду вам очень благодарен.
Ссылка на источник данных
Данные доступны здесь: https://www.kaggle.com/competitions/spaceship-titanic/overview
Как указано в правилах (https://www.kaggle.com/competitions/spaceship-titanic/rules), в разделе 7 А данные могут быть использованы для любых целей.
A. Доступ к данным и их использование. Вы можете получать доступ к Данным Конкурса и использовать их для любых целей, будь то коммерческих или некоммерческих, в том числе для участия в Конкурсе и на форумах Kaggle.com, а также для академических исследований и образования.