Доктор Вероника Эспиноза, 2022 г. / Twitter @Verukita1

Nocode functions — это веб-приложение, которое делает лучшие в своем классе функции анализа данных доступными для всех.
Nocode functions — это бесплатное веб-приложение без регистрации для анализа данных по клику и точке. Долгосрочная цель nocodefunctions — предоставить бесплатное, удобное и надежное веб-приложение, помогающее разным аудиториям использовать общие (но сложные) функции анализа данных, предлагаемые в лучших в своем классе версиях.
Функции Nocode были разработаны Клеманом Леваллуа, профессором из Парижа, страстно увлеченным извлечением информации из социальных сетей и сетей. Он публиковал исследования в академических журналах.
Узнайте больше о Клементе Леваллуа в группе Facebook для Gephi, Twitter, LinkedIn или просмотрите его веб-сайт.
Как начать использовать этот инструмент?
а) Сначала откройте инструмент здесь

б) Подготовьте свои данные. Все, что вам нужно, это файл (Excel, pdf, csv, txt…) или таблица Google, содержащая ваши данные.
c) Выберите функцию. Выберите интересующую вас функцию в зависимости от вашего исследовательского проекта, ваших целей и ваших данных.
г) Выполните следующие 3 шага: загрузите свои данные › проанализируйте › просмотрите результаты.

В этом разделе описаны основные функции инструмента.
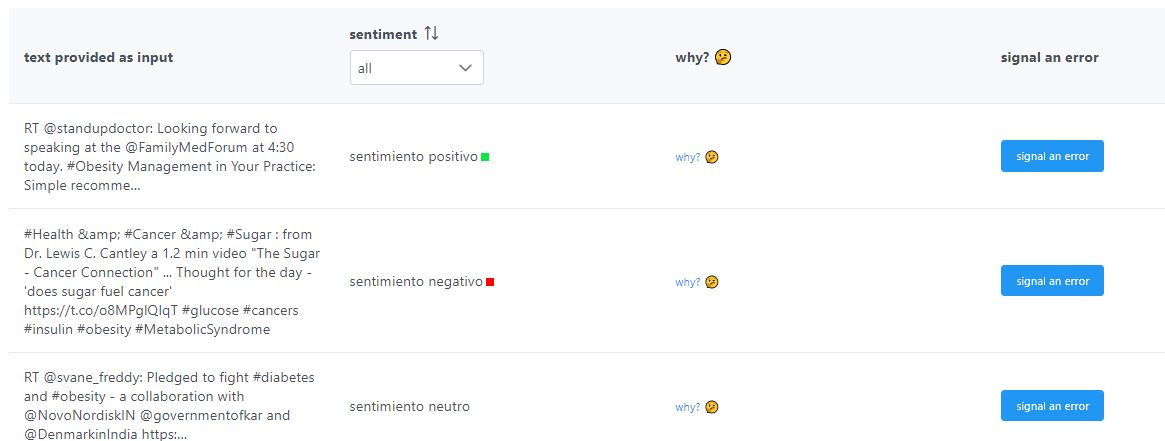
- –Анализ настроений.
Эта функция выполняет анализ настроений, также называемый анализом мнений. Он анализирует текст и определяет, является ли настроение нейтральным, положительным или отрицательным. Лучше всего он работает в социальных сетях, таких как твиты для Twitter, комментарии к постам в Instagram и другие очень короткие тексты на английском, французском и испанском языках. По сравнению с 23 альтернативами этот инструмент оказался лучшим инструментом для анализа настроений в социальных сетях. Эти функции, созданные в 2012 году, постоянно развиваются.
Принципы, которым следует эта функция, описаны в этой академической публикации об Umigon, опубликованной в Антологии Ассоциации компьютерной лингвистики.
Этапы процесса анализа настроений:

2.- Преобразование текста в сети.
Функция определяет пары терминов в каждой строке текста. Эти пары называются совпадающими. Объединяя все пары терминов и выбирая наиболее часто встречающиеся, строится сеть терминов, в которой любые два термина связаны, если они часто встречаются в тексте вместе.
Модель
Принципы, которым следует этот инструмент, описаны в этой академической публикации, посвященной тому, как находить сообщества и темы в Твиттере. Технология состоит из следующих этапов:
- очистка текста: сведение к ASCII, удаление URL-адресов, удаление знаков препинания.
- лемматизация.
- разложение текста по n-граммам до четырех-грамм, удаление менее релевантных n-грамм. Этот шаг идентичен тому, за которым следует функция анализа настроений.
- количество совпадений: какие пары n-грамм чаще всего встречаются в одних и тех же строках текста?
- список совпадающих n-грамм используется для создания сети: он состоит из наиболее часто встречающихся n-грамм. Две n-граммы связаны, если они часто встречаются вместе.
- сила соединений в сети корректируется с помощью процедуры, называемой Поточечная взаимная информация (PMI).
Этапы преобразования текста в семантические сети:


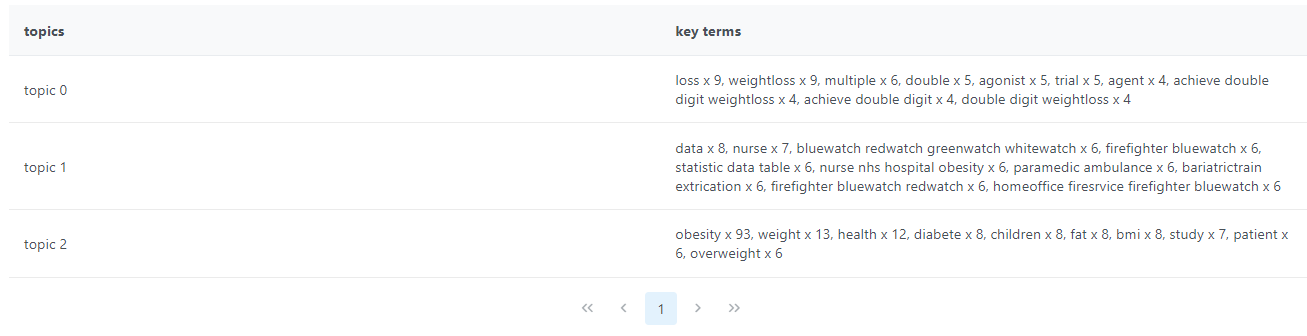
4.-Находите ключевые темы в тексте.
Эта функция автоматически определяет ключевые темы в тексте. Эта операция называется извлечение темы или моделирование темы. Он анализирует текст построчно и определяет группы слов и выражений, которые имеют тенденцию группироваться вместе, образуя темы.
Он работает с текстами, написанными на самых разных языках (включая тексты на других языках). латинский алфавит). Эта функция следует принципам обучения без учителя, которое является разновидностью машинного обучения.
Как определить количество тем, которые нужно найти?
Самый классический подход к обнаружению темы основан на методе кластеризации, который называется "k-means". С его помощью пользователь решает, сколько тем должно быть в тексте, а затем алгоритмы находят эти темы.
Такой подход может иметь смысл, когда мы заранее знаем, сколько тем в тексте. Но какой смысл в обнаружении темы, если мы уже знаем темы?
В функциях nocode количество тем, которые нужно найти, заранее не определено. Аналитик многому научится, обнаружив, сколько тем алгоритм может найти в тексте без заранее заданного ограничения. Аналитик сохраняет полный контроль благодаря параметру точности, который помогает настроить алгоритм для поиска большего или меньшего количества тем, но всегда со степенью свободы в отношении точного числа.
Как найти ключевые темы в тексте:

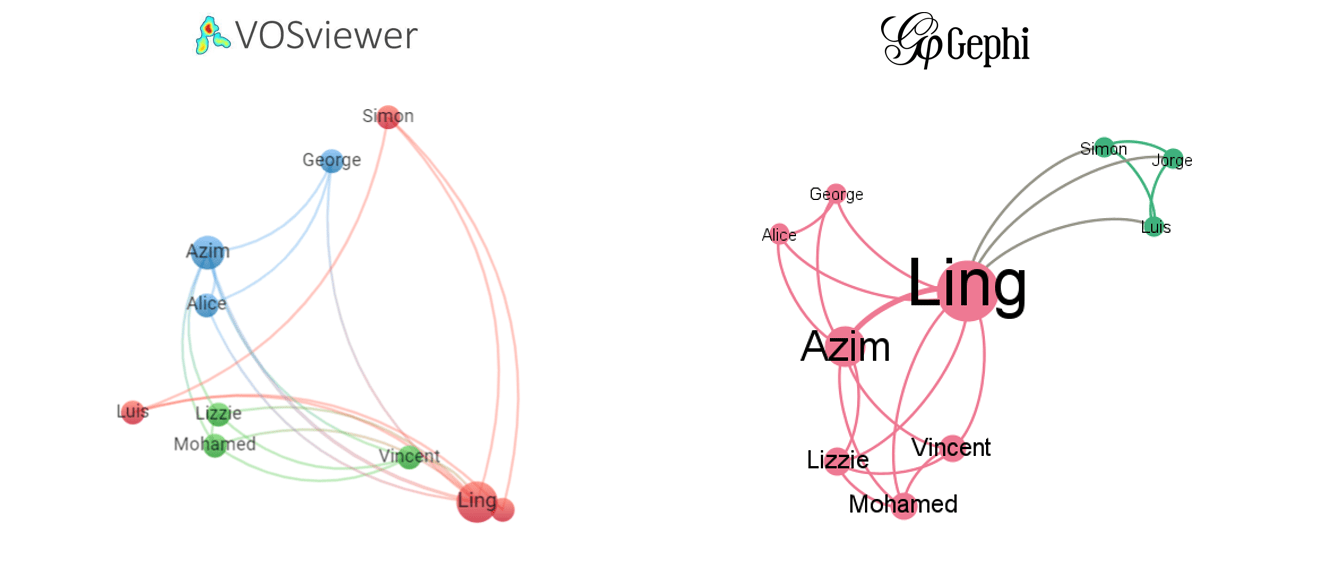
5.-Создавайте сети из списков.
Создайте сети двумя способами: 1.-совпадения и 2.-источники и цели, как показано в следующих примерах:

Исследование графа.
Для исследования семантической сети, созданной функцией, рекомендуется использовать два бесплатных программного обеспечения:
· Gephi предоставляет наилучшие функции для фильтрации, раскрашивания, изменения размера и запуска описательной графической статистики в вашей сети (например, промежуточная центральность).
· VOSviewer обеспечивает визуализацию, которая является самой чистой и простой для интерпретации для семантических сетей. VOSviewer разработан с использованием наукометрии в качестве первого варианта использования, но он полезен для любого типа семантической сети.
Этапы создания сетей из списков:

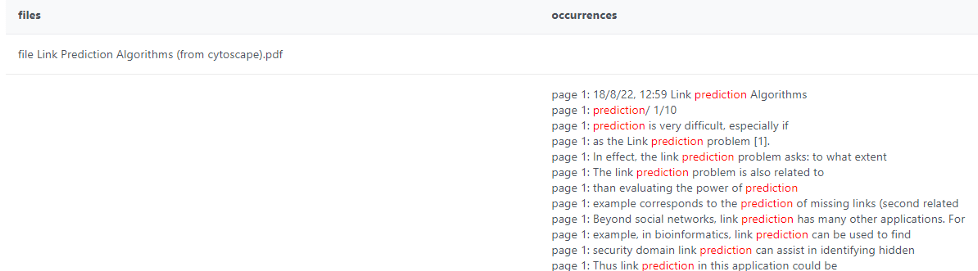
6.-Предсказывать новые ссылки в сети.
Эта функция является прямым приложением подключаемого модуля Gephi, разработанным Марко Романутти и Саскией Шулер под руководством Майкла Хеннингера из FHNW. Их код виден на Github.
Прогноз основан на предпочтительном прикреплении. Он ограничен ненаправленными, невзвешенными сетями. Рассуждение простое: наиболее вероятная ссылка, которая будет создана, — это связь между двумя узлами, которые имеют наибольшее количество соседей, но еще не имеют соединения.
Как интерпретировать этот прогноз ссылок? Отсутствие ссылки может означать, что:
- У этой ссылки нет потенциала (она не «актуальна» для задействованных узлов).
- Существует потенциал для создания этой связи, и этот потенциал еще не реализован.
- Существует потенциал для связи, но два узла предпочитают не актуализировать связь.
Это означает, что «предсказание» ссылки может относиться к одному из этих трех случаев.
Шаги для прогнозирования новых ссылок в сети:


7.-Поиск текста в файлах PDF.
Эта функция позволяет идентифицировать в pdf-файлах интересующее слово или фразу с учетом контекста.
Действия по поиску текста в файлах PDF:

👍Спасибо, что прочитали
😃Это мой Твиттер
ССЫЛКИ
- Исследуйте свои данные одним щелчком мыши [Интернет]. Функции без кода. [по состоянию на 9 ноября 2022 г.]. Доступно на: https://nocodefunctions.com/
- Levallois C. Umigon: анализ тональности твитов на основе списков терминов и эвристики. En: Вторая совместная конференция по лексической и вычислительной семантике (*SEM), Том 2: Материалы седьмого международного семинара по семантической оценке (SemEval 2013) [Интернет]. Атланта, Джорджия, США: Ассоциация компьютерной лингвистики; 2013 [по состоянию на 9 ноября 2022 г.]. п. 414–7. Доступно на: https://aclanthology.org/S13-2068
- Бенабделькрим М., Леваллуа С., Савиньен Дж., Робарде С. Открытие полей: методологический вклад в идентификацию гетерогенных акторов в неограниченных реляционных порядках. М@н@гемент. 31 марта 2020 г.;4–18.
- Блог N функций-. Точечная взаимная информация и тф идф, когда их использовать [Интернет]. [по состоянию на 10 ноября 2022 г.]. Доступно на: https://nocodefunctions.com/blog/pmi-tf-idf/