В этой статье обсуждаются два метода машинного обучения. Это дерево решений (также известное как дерево классификации и регрессии), а затем случайный лес. Дерево решений, как следует из его названия, принимает форму дерева, чтобы решить, к какой классификации относятся новые наблюдения. В основном мы использовали этот метод дерева решений в повседневной жизни, чтобы принимать решения. Если произойдет A, выполните B. Или же выполните C. Это дерево решений в машинном обучении построит дерево решений в соответствии с данными, которые пользователь передает в модель. Если вы не знакомы с основами машинного обучения, найдите статью, в которой это обсуждается, здесь. После этого снова вернитесь сюда к этой статье.
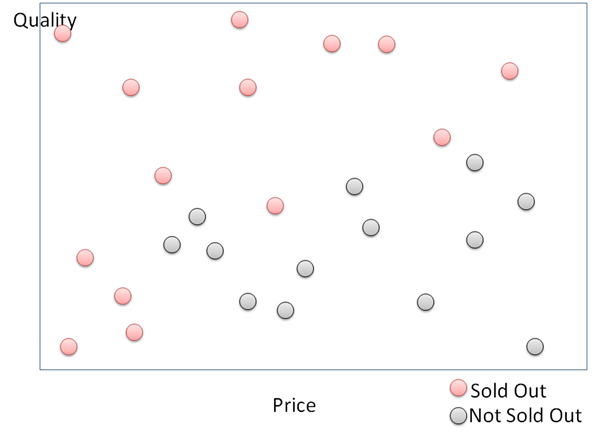
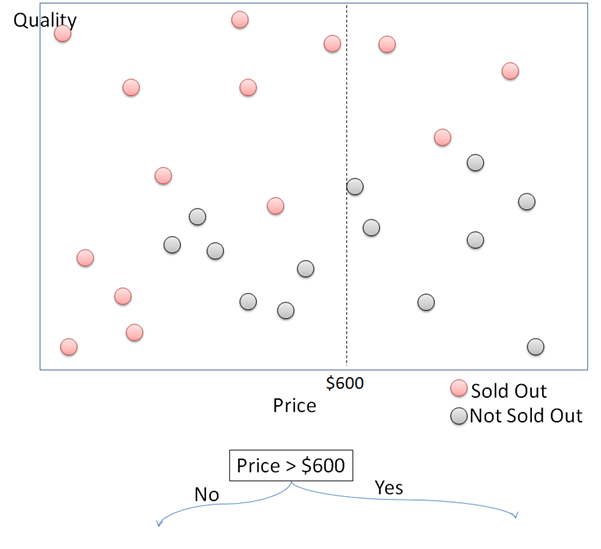
То, как работает дерево решений простым способом, выражается с использованием следующих данных. На этом графике показаны купленные товары, отложенные по их цене по оси x и качеству по оси y. Купленные товары затем делятся на «распроданные» и «не распроданные». В этой статье мы попытаемся построить дерево решений, чтобы определить, будет ли вещь продана или нет, в зависимости от ее цены и качества.
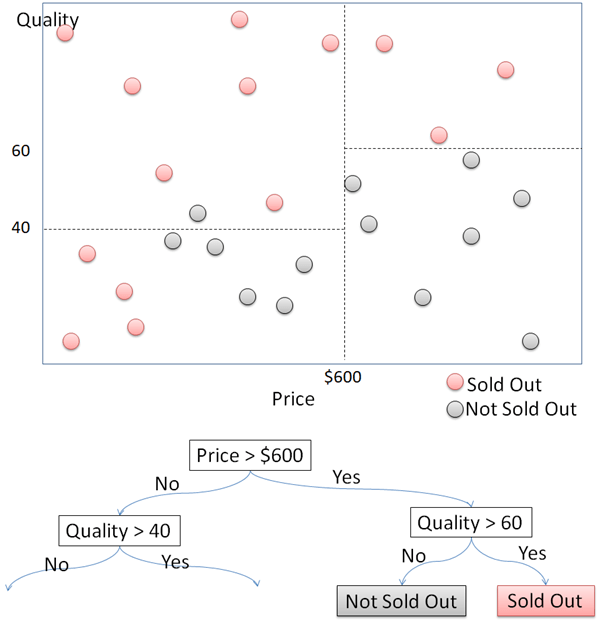
Во-первых, разделите точки данных на две части по цене. Точки данных с ценами выше и ниже 600 долларов делятся на правые и левые. Для каждой из сторон снова разделите точки данных на 2 части в соответствии с качеством. Для точек данных с ценой выше 600 долларов они будут распроданы, если качество выше 60, и не проданы, если качество ниже 60. Этот процесс продолжает разделять эти точки данных при расширении дерева решений.
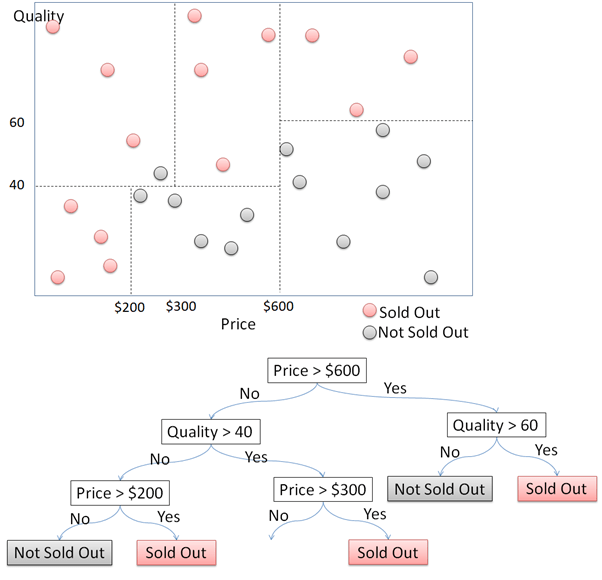
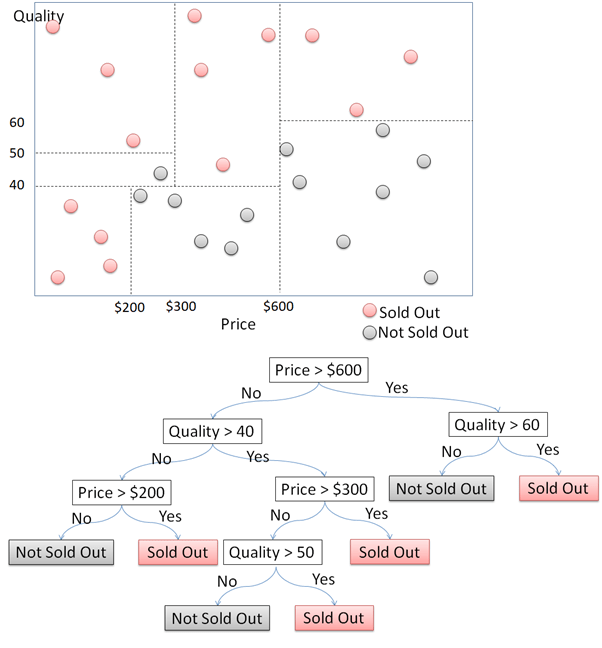
В приведенном выше примере просто показано растущее дерево решений, поскольку точки данных имеют только 2 измерения. Все будет сложнее, если данные имеют более трех измерений или параметров. Для этого мы будем использовать данные клиентов отелей. Данные являются фиктивными данными, которые я создал. Данные содержат информацию о мнениях клиентов об отеле. В этом фрейме данных 500 наблюдений или строк. Каждое наблюдение представляет одного клиента. Имеется 12 переменных со следующей структурой данных.
>str(CustomerData) data.frame': 500 obs. of 12 variables: $ Id : int 1 2 3 4 5 6 7 8 9 10 ... $ Gender : Factor w/ 2 levels "Female","Male": 1 1 1 2 2 2 2 1 2 2 ... $ Age : num 33 30 37 34 33 34 35 30 39 34 ... $ Purpose : Factor w/ 2 levels "Business","Personal": 2 2 2 2 2 2 2 2 1 2 ... $ RoomType : Factor w/ 3 levels "Double","Family",..: 1 2 3 1 1 1 1 2 1 1 ... $ Food : num 21 32 46 72 84 67 56 10 73 97 ... $ Bed : num 53 32 25 30 7 46 0 19 12 30 ... $ Bathroom : num 24 18 29 15 43 16 0 1 62 26 ... $ Cleanness : num 44 44 20 55 78 61 9 53 65 59 ... $ Service : num 46 74 24 38 51 44 32 58 56 46 ... $ Satisfaction: Factor w/ 3 levels "Dissatisfied",..: 1 1 1 1 2 2 1 1 2 2 ... $ Repeat : Factor w/ 2 levels "No","Repeat": 2 1 1 2 2 1 1 2 2 1 ...
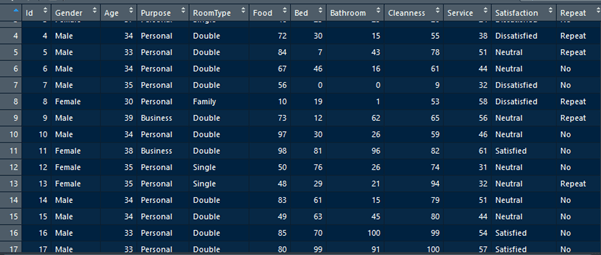
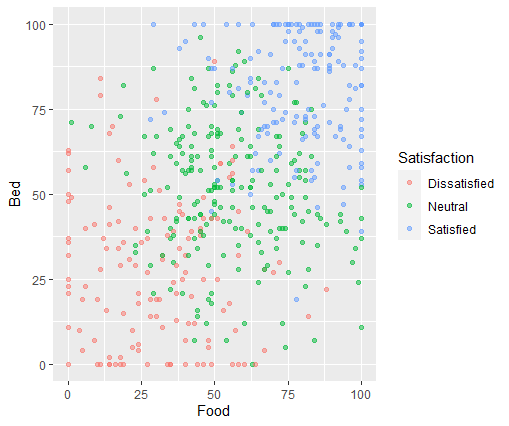
Клиентов просят заполнить форму опроса, чтобы оценить 5 параметров отеля и, наконец, дать общее заключение об удовлетворенности. 5 параметров: еда, постель, ванная, чистота и обслуживание. Пять параметров оцениваются числовыми значениями от 0 до 100. 0 означает очень плохо, а 100 — очень хорошо. Общая удовлетворенность просит клиента заполнить один из трех классов: удовлетворенный, нейтральный или неудовлетворенный. Есть и другие переменные, такие как возраст, цель, тип комнаты и повтор, но они не обсуждаются в этой статье.
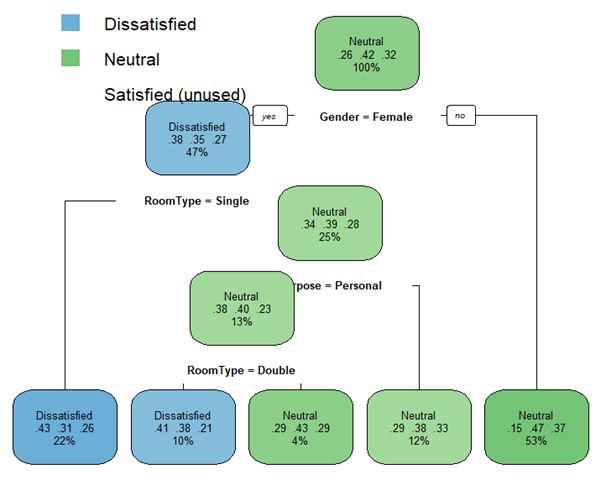
Приведенный ниже сценарий создаст дерево решений, используя 3 параметра клиентов отеля: пол, цель и тип номера, чтобы классифицировать общую удовлетворенность клиентов. Три параметра имеют категориальный формат. Классификация удовлетворенности выражается в 3 классах. Они бывают «удовлетворены», «нейтральны» и «недовольны».
# Load the rpart package library(rpart) # Build a model to predict according to selected parameters. Here we try categorical parameters TreeModel <- rpart(Satisfaction~Gender+ Purpose + RoomType, data = trainCustomer, method = "class", control = rpart.control(cp = 0)) # predict the test data predictTree <- predict(TreeModel, testCustomer, type = "class") # Load the rpart.plot package library(rpart.plot) # visualize the decision tree rpart.plot(TreeModel, tweak = 1.5)
# percentage of accuracy > table(predictTree, testCustomer$Satisfaction) predictTree Dissatisfied Neutral Satisfied Dissatisfied 16 16 8 Neutral 15 24 21 Satisfied 0 0 0 > mean(predictTree == testCustomer$Satisfaction) [1] 0.4
Точность очень низкая, всего 40%. Теперь сценарий дерева решений будет запущен снова. На этот раз будут использоваться все параметры или предикторы. Позже модель решит, какие параметры наиболее важны для роста дерева решений. Он даже не может предсказать «удовлетворен».
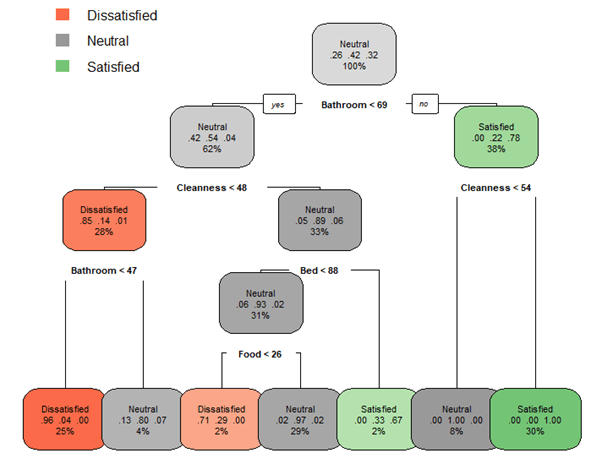
# Create decision tree model using all of the parameters TreeModel2 <- rpart(Satisfaction ~ ., data = trainCustomer, method = "class", control = rpart.control(cp = 0)) # predict the test data predictTree2 <- predict(TreeModel2, testCustomer, type = "class") # visualize the decision tree rpart.plot(TreeModel2, tweak = 1.3) head(data.frame(testCustomer[,c(6:9, 11)],predictTree2), 20)
> # percentage of accuracy > mean(predictTree2 == testCustomer$Satisfaction) [1] 0.89 > table(predictTree2, testCustomer$Satisfaction) predictTree2 Dissatisfied Neutral Satisfied Dissatisfied 26 4 0 Neutral 4 36 2 Satisfied 1 0 27
Вот результат классификации первых 20 наблюдений тестовых данных.
Food Bed Bathroom Cleanness Satisfaction predictTree2 488 42 64 68 40 Neutral Neutral 158 100 37 25 59 Neutral Neutral 126 55 80 93 84 Satisfied Satisfied 113 100 87 63 72 Satisfied Neutral 325 58 32 0 19 Dissatisfied Dissatisfied 421 82 100 70 83 Satisfied Satisfied 154 82 45 10 99 Neutral Neutral 481 92 89 86 100 Satisfied Satisfied 253 15 70 38 0 Dissatisfied Dissatisfied 460 28 51 84 20 Neutral Neutral 64 23 33 29 86 Neutral Dissatisfied 373 51 69 53 78 Neutral Neutral 89 67 46 16 61 Neutral Neutral 402 25 36 11 23 Dissatisfied Dissatisfied 252 42 60 90 12 Neutral Neutral 406 45 40 14 32 Dissatisfied Dissatisfied 67 83 61 15 79 Neutral Neutral 128 89 86 100 100 Satisfied Satisfied 280 94 52 90 72 Satisfied Satisfied 392 34 38 5 8 Dissatisfied Dissatisfied
Созданное выше дерево решений имеет глубину 4. Теперь изучите приведенный ниже сценарий, который строит другую модель дерева решений с использованием аргумента maxdepth = 3. Это ограничивает максимальную глубину дерева решений до 3. Мы видим, что вырезание заросших ветвь может фактически повысить точность. Точность третьего дерева решений, которое у нас есть, составляет 91%. Дерево решений теперь также более простое, чем предыдущее.
# Tend to of overgrown tree # set the maxdepth of 3 for the tree TreeModel3 <- rpart(Satisfaction ~ ., data = trainCustomer, method = "class", control = rpart.control(cp = 0, maxdepth = 3)) # Predict the test data predictTree3 <- predict(TreeModel3, testCustomer, type = "class") # plot the decision tree rpart.plot(TreeModel3, tweak = 1.3)
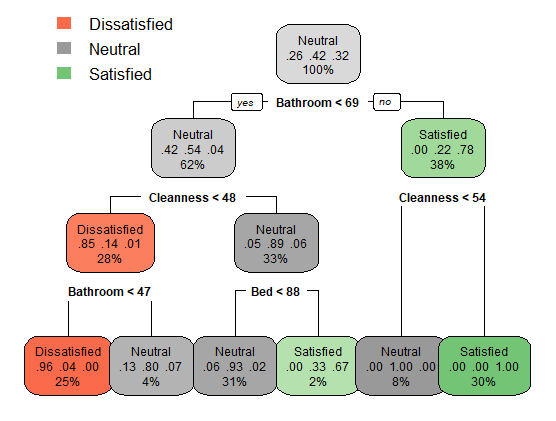
> # Compute the accuracy of the simpler tree > mean(predictTree3 == testCustomer$Satisfaction) [1] 0.91 > table(predictTree3, testCustomer$Satisfaction) predictTree3 Dissatisfied Neutral Satisfied Dissatisfied 25 1 0 Neutral 5 39 2 Satisfied 1 0 27
Еще один способ сделать дерево решений более простым — это обрезка. После того, как дерево решений выросло, оно может показаться слишком сложным. Сокращение может применяться для сокращения менее важных ветвей дерева решений, чтобы оно было менее сложным. Обрезка менее важных ветвей выполняется в наименее сложной точке, где относительная ошибка больше не уменьшается значительно. На приведенном ниже графике показана относительная ошибка по оси Y и cp по оси X, представляющая сложность. Относительная ошибка падает, когда дерево решений становится более сложным или cp приближается к 0. Выясните, что c = 0,024 — это точка, в которой относительная ошибка больше не уменьшается значительно при уменьшении cp.
# Examine the complexity plot plotcp(TreeModel3)
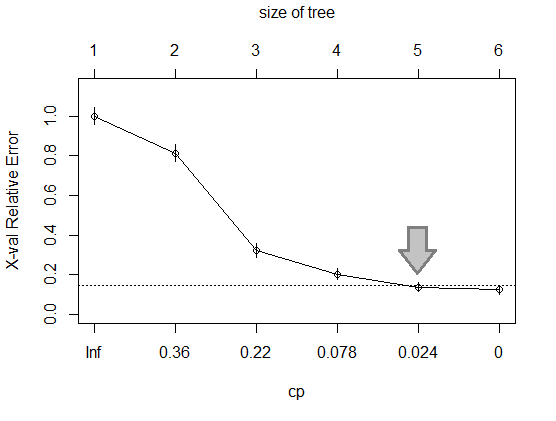
# Prune the tree TreeModel3_pruned <- prune(TreeModel3, cp = 0.024 ) rpart.plot(TreeModel3_pruned) # Predict the test data predictTree3_pruned <- predict(TreeModel3_pruned, testCustomer, type = "class")
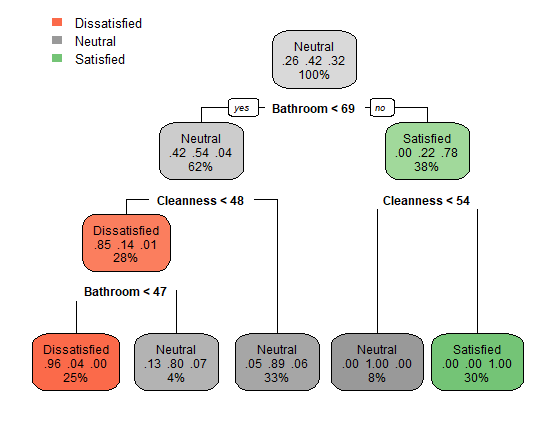
Вот результат и точность модели дерева решений после обрезки с cp = 0,024.
> mean(predictTree3_pruned == testCustomer$Satisfaction)
[1] 0.9
> table(predictTree3_pruned, testCustomer$Satisfaction)
predictTree3_pruned Dissatisfied Neutral Satisfied
Dissatisfied 25 1 0
Neutral 6 39 3
Satisfied 0 0 26
Теперь мы обсудим еще один метод машинного обучения, который все еще связан с деревом решений. Он называется случайным лесом. Модель случайного леса создает несколько разных деревьев решений, используя одни и те же данные. Когда тестовые данные вводятся в модель случайного леса, все деревья решений будут классифицировать тестовые данные. После этого деревья решений проголосуют за то, к какой классификации относятся тестовые данные.
На рисунке ниже показан случайный лес, состоящий из нескольких деревьев решений. Каждое дерево решений классифицирует тестовые данные по классам «A» и «B». Поскольку существует больше деревьев решений, которые классифицируют тестовые данные как «А», принято решение, что тестовые данные классифицируются как «А».
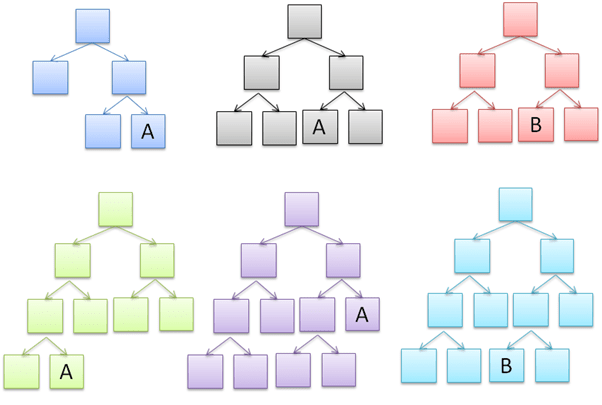
Приведенный ниже сценарий пытается классифицировать удовлетворенность клиентов отеля с помощью метода случайного леса.
# Load the randomForest package library(randomForest) # Grow a random forest model RF_model <- randomForest(Satisfaction~., data = trainCustomer) # Run the Random Forest model to the test data PredictRF <- predict(RF_model, testCustomer) > mean(PredictRF == testCustomer$Satisfaction) [1] 0.97 > table(PredictRF, testCustomer$Satisfaction) PredictRF Dissatisfied Neutral Satisfied Dissatisfied 29 0 0 Neutral 2 40 1 Satisfied 0 0 28