Как создавать визуализации для книг
Поклонники веб-комикса xkcd, вероятно, помнят повествовательные диаграммы, которые он сделал для таких фильмов, как Властелин колец, Парк Юрского периода и — саркастически — 12 разгневанных мужчин:
Но большинство поклонников xkcd, вероятно, не знали, что существует проект программного обеспечения с открытым исходным кодом от Университета Ватерлоо для динамического создания этих диаграмм. Единственная проблема с этим проектом заключается в том, что он берет данные из комиксов, которые, я думаю, были созданы вручную. Мне было интересно применить их технику визуализации к книгам, поэтому я подключил код Python к их библиотеке d3, чтобы создавать повествовательные диаграммы для пьес и романов.
Археология данных
Первоначальный проект Ватерлоо отображал повествовательную диаграмму для панели комиксов за панелью. Информация поступала через объект JSON верхнего уровня, который содержал название произведения, список персонажей верхнего уровня с идентификаторами и список сцен с информацией о том, какие персонажи присутствовали в каждой из них:
{
"title": "Romeo and Juliet",
"characters": [
{
"name": "Romeo",
"group": 1,
"id": 1,
},
// ...
],
"scenes": [
{
"title": "Act 1",
"duration": 10,
"start": 499,
"chars": [1, 3, 7],
"named_chars": ["Romeo", "Juliet", "Friar Laurence"],
"id": 1,
},
// ...
]
}
Я хотел использовать этот инструмент для визуализации книг и пьес, таких как Ромео и Джульетта; таким образом, мне нужно было проанализировать тела этих работ и обработать их, чтобы они выглядели как приведенный выше JSON. К счастью — и сейчас странно об этом думать — эти пьесы 16-го века были написаны на высокоструктурированном DSL, который выглядел так:
ACT I SCENE I. A public place. Enter Sampson and Gregory armed with swords and bucklers. SAMPSON. Gregory, on my word, we’ll not carry coals. GREGORY. No, for then we should be colliers. SAMPSON. I mean, if we be in choler, we’ll draw. GREGORY. Ay, while you live, draw your neck out o’ the collar. SAMPSON. I strike quickly, being moved.
Как будто Шекспир использовал формат файла, оканчивающийся на .play. Границы акта и сцены четко обозначены, а строкам для каждого персонажа предшествует его имя в верхнем регистре плюс точка. Мы могли бы даже написать для этого грамматический файл:
CHARACTER := [A-Z ]+ LINE := CHARACTER ".\n" ([a-ZA-Z0-9 ,\"\'\?]+\n)*[a-ZA-Z0-9 ,\"\'\?]+ "\n" STAGE_DIRECTION := ([a-ZA-Z0-9 ,\"\'\?]+\n)*[a-ZA-Z0-9 ,\"\'\?]+ "\n" SCENE := "SCENE " [IVX]+ ".\n" (LINE | STAGE_DIRECTION)+
Однако для разбора этих игровых сценариев мы не собираемся писать полный парсер с yacc — это было бы излишеством. Но мы будем делать простой обход строк текста в духе алгоритма с одним указателем.
Парсинг — это все, что вам нужно
Мы собираемся получить игру в виде списка строк, а затем использовать алгоритм с одним указателем, в котором мы пошагово перемещаемся по строкам, используя индекс i = 0. Мы хотим отслеживать, в какой сцене мы находимся, сколько персонажей в каждой сцене и кто какие строки произнес, как показано ниже:
import re
lines = open(filename, 'r').readlines()
scenes = []
last_line_ix = 0
last_scene_match = None
next_scene_match = None
i = 0
while i < len(lines)
line = lines[i]
next_scene_match = re.match(r"SCENE [IVX]+", line)
if next_scene_match:
# Save the last scene with all its lines.
if last_scene_match:
scenes.append(
Scene(
title=last_scene_match.group(0),
lines=lines[last_line_ix : i])
last_scene_match = next_scene_match
last_line_ix = i + 1
i += 1
if len(lines) > last_line_ix:
scenes.append(
Scene(
title=last_scene_match.group(0),
lines=lines[last_line_ix : len(lines)])
Каждый раз, когда мы видим новый маркер "SCENE ", мы берем все строки, которые были видны с момента последнего маркера сцены, и склеиваем их в объект Scene. Единственная проблема с подобным синтаксическим анализом заключается в том, что вы обычно выходите из основного цикла с некоторым «зависанием». Поскольку цикл сохраняет последнюю сцену только после того, как он увидит новый маркер сцены, а воспроизведение не заканчивается конечным маркером сцены, мы должны не забыть сохранить последнюю сцену после выхода из цикла — это проверка if len(lines) > last_line_x:.
Один важный нюанс парсеров заключается в том, что они должны работать только в одном направлении. Из всех просмотров кода, которые я когда-либо делал, тот, в котором я, вероятно, принёс наибольшую пользу для карьеры инженера, был тот, в котором я просматривал такой код:
i = 0
do_other_thing = False
while i < len(lines):
line = lines[i]
if do_other_thing:
option_b(line)
i += 1
do_other_thing = False
elif something_else(line):
# Oh, we should have treated the last line differently, so go back.
do_other_thing = True
i -= 1
else:
option_a(line)
i += 1
Этот код начинался как обычный анализатор с одним указателем с индексом i, который перемещался по списку. Но затем программист обнаружил пограничный случай, который означал, что им нужно было «вернуться и исправить ситуацию», поэтому они установили флаг do_other_thing = True и уменьшили указатель на i -= 1. Затем в следующем цикле флаг заставил синтаксический анализатор выполнить специальное действие.
Проблема с этим небольшим изменением заключалась в том, что оно нарушает монотонность. Если все, что делает синтаксический анализатор, — это увеличивает i += 1 от начала до конца, то программа гарантированно завершится. Однако, как только он имеет декремент i -= 1, синтаксический анализатор становится двунаправленным, поток управления намного сложнее и потенциально может закончиться бесконечным циклом. И в этом коде тоже есть баг — должно быть i += 2 вместо i += 1 в ветке if do_other_thing:. В противном случае он просто нажмет something_else на следующем цикле и снова пойдет назад, что приведет к такому же бесконечному циклу.
Гораздо лучшая версия этого кода использует «упреждающий просмотр» или просмотр следующих строк всякий раз, когда требуется дополнительная информация. Это гораздо более чистая версия вышеприведенного, в которой используется «просмотр вперед» вместо «перемотки назад». Вот как выглядит код:
i = 0
while i < len(lines):
line = lines[i]
if i + 1 < len(lines) and something_else(lines[i + 1]):
# Treat these lines differently.
option_b(line)
option_b(lines[i + 1])
i += 2
else:
option_a(line)
i += 1
Визуализация результатов
После того, как я проанализировал все сцены, я просто отправил им список персонажей и псевдонимов для поиска (например, "ROMEO." и "JULIET."), чтобы отслеживать, кто появляется в каждой сцене:
class Scene(object):
def __init__(self, title=None, lines=None):
self.title = title
self.lines = lines
self._character_occs = {}
def FindCharacters(self, characters):
for line in self.lines:
for character in characters:
for alias in character.aliases:
if alias in line:
self.AddCharacter(character)
def AddCharacter(self, character):
if character.name not in self._character_occs:
self._character_occs[character.name] = {
'character': character,
'count': 1,
}
else:
self._character_occs[character.name]['count'] += 1
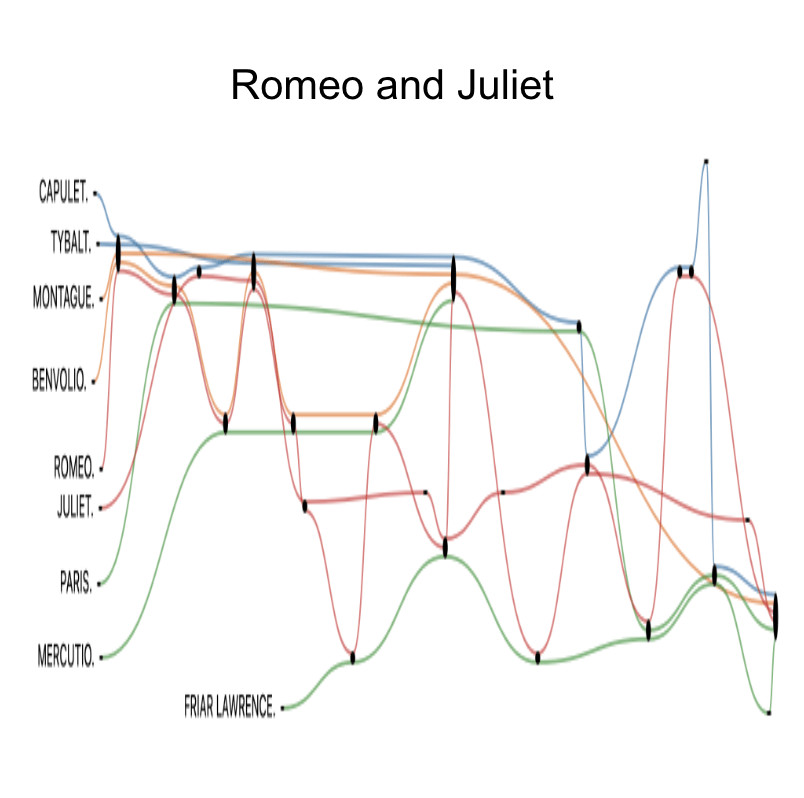
Последним шагом был перевод этого в формат, ожидаемый кодом Ватерлоо (который был немного сложным и не интересным для этой статьи), а затем рендеринг на веб-странице шаблона. Для Ромео и Джульетты наша повествовательная таблица выглядит следующим образом:

Приятно видеть, как повествования персонажей переплетаются воедино: основная связь собирается вокруг кончины Тибальта, Ромео и Джульетта порхают друг вокруг друга до своей роковой кончины, а брат Лоуренс просто тайно руководит всем сюжетом снизу.
Я также хотел обобщить этот код для обработки других работ, поэтому я завернул его в скрипт, который принимает аргументы. Синтаксический анализ Ромео и Джульетты можно выполнить, указав входной файл, регулярное выражение сцены и группы символов следующим образом:
./novel_narrative_charts.py \
--book \
--title="Romeo and Juliet" \
--chapter_regex="SCENE \\w+\\." \
--filename=sources/romeo_and_juliet.txt \
--character_group=CAPULET.\|LADY\ CAPULET.,TYBALT. \
--character_group=MONTAGUE.\|LADY\ MONTAGUE.,BENVOLIO. \
--character_group=PARIS.,MERCUTIO.,FRIAR\ LAWRENCE. \
--character_group=JULIET.,ROMEO.
С этой оболочкой легко применить этот код к другим произведениям — и не только к играм. Чтобы разобрать один из моих любимых романов, Миддлмарч, я просто передал ему новый набор аргументов (хотя для романа этот скрипт в настоящее время не может определить разницу между тем, является ли отсылка к персонажу имя означает, что они говорят, появляются или просто говорят о них):
./novel_narrative_charts.py \
--book \
--title="Middlemarch" \
--chapter_regex="CHAPTER \\w+\\." \
--filename=sources/middlemarch.txt \
--character_group=Dorothea\ Brooke\|Dorothea\|Miss\ Brooke,Celia\ Brooke\|Celia,Arthur\ Brooke\|Arthur\|Mr\.\ Brooke \
--character_group=Mary\ Garth\|Mary\|Miss\ Garth,Caleb\ Garth\|Caleb\|Mr\.\ Garth \
--character_group=Tertius\ Lydgate\|Tertius\|Lydgate,James\ Chettam\|James,Will\ Ladislaw\|Will\|Mr.\ Ladislaw \
--character_group=Rosamond\ Vincy\|Rosamond\|Miss\ Vincy\|Mrs\.\ Lydgate,Fred\ Vincy\|Fred,Mr\.\ Casaubon\|Casaubon
Полученная диаграмма, однако, становится довольно занятой, и я, возможно, расширяю пределы этой технологии как есть (или, может быть, мне следует выбрать более короткую книгу для анализа):

Рекомендации
- https://github.com/kldvlinearwords/NovelNarrativeCharts
- https://github.com/niskander/ComicBookNarrativeCharts