Разоблачение обманчивой стороны метрик данных

Являетесь ли вы новичком в мире статистического анализа (или науки о данных, анализа данных, машинного обучения и т. д.) или опытным ветераном; тогда шансы — одна из первых вещей, о которых вы узнали, — это линейный регрессионный анализ. Также весьма вероятно, что среда (без каламбура), в которой вы узнали о регрессии, реализовала метрику R² во время оценки модели. Хотя R² является популярной метрикой для оценки регрессионных моделей, иногда она может оказаться недостаточно надежной и интерпретируемой.
Безусловно, существует множество других проблем, которые могут возникнуть при реализации регрессионного анализа, и недостатки метрики R² никоим образом не охватывают все эти потенциальные сложности. Однако в этой статье мы сосредоточимся конкретно на R² и начнем с нескольких основных определений, за которыми следуют некоторые конкретные примеры того, когда и почему метрика R² может быть обманчивой с точки зрения ее надежности и интерпретации.
Определения:
Линейная регрессия:
Метод контролируемого обучения, который реализуется для прогнозирования переменной количественного ответа (Y) на основе одной или нескольких переменных-предикторов (X). Метод предполагает линейную связь между предикторами и откликом. Отношения между предиктором и ответом можно смоделировать как:

В множественной линейной регрессии может быть более одной переменной-предиктора. «Линия наилучшего соответствия» оценивается путем минимизации функции потерь, часто остаточной суммы квадратов между наблюдаемыми и прогнозируемыми значениями (так называемый метод «наименьших квадратов»). В то время как линейная регрессия предполагает линейную связь, она может обрабатывать нелинейные отношения, когда включены полиномиальные признаки или условия взаимодействия. Для простоты мы будем использовать простой пример линейной регрессии. Ниже приведен пример функции потерь, которую мы стремимся минимизировать с помощью метода наименьших квадратов линейной регрессии:

В приведенной выше функции:
- J(θ) — функция потерь.
- θ — вектор параметров модели.
- m — количество экземпляров в наборе данных.
- hθ(x) — прогноз модели для i-го экземпляра.
- y — фактическое значение для i-го экземпляра.
- Сумма по i — это суммирование квадратов остатков для всех экземпляров в наборе данных.
R²:
Также известный как коэффициент детерминации, представляет собой статистическую меру, представляющую долю дисперсии для зависимой переменной, которая объясняется независимой переменной или переменными в регрессионной модели.
Он варьируется от 0 до 1, где 0 указывает на то, что независимые переменные не объясняют ни одну из дисперсий зависимой переменной, а 1 указывает на то, что они объясняют все. Другими словами, более высокий R² указывает на лучшее соответствие модели. R² рассчитывается следующим образом:



Скорректированный R²:
Также указывает, насколько хорошо термины соответствуют кривой или линии, но корректирует количество терминов в модели. Если вы добавляете в модель все больше и больше бесполезных переменных, R² не уменьшится, но скорректированное R² уменьшится, если дополнительные переменные не улучшат соответствие модели. Следовательно, скорректированный R² может быть более точной мерой того, насколько хорошо модель обобщает.

Теперь, когда у нас есть несколько определений, давайте рассмотрим некоторые из основных причин, по которым R² может быть обманчивой метрикой.
Причины обмана или недостоверности R²:
Определение и интерпретация R²:
Одной из основных причин того, что R² может вводить в заблуждение, является неправильное толкование самой метрики. R² измеряет долю дисперсии переменной (переменных) ответа, которая объясняется переменной (переменными) предиктора. Это не то же самое, что измерение того, насколько «хороша» сама модель. Модель с R², близким к 1, также может быть моделью, которая дает плохие прогнозы на невидимых данных.
Возможность переобучения:
Высокое значение R² иногда может быть результатом переобучения, особенно когда количество предикторов близко к количеству наблюдений. Это связано с тем, что модель может «запоминать» обучающие данные и плохо работать с невидимыми данными. Давайте посмотрим на пример этого.
# Create a toy data set with 200 samples and 1000 features
n_samples = 200
n_features = 1000
X, y = make_regression(n_samples=n_samples, n_features=n_features,
noise= 1, random_state=0)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
# Train a linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict on the training set and calculate R^2
y_train_pred = model.predict(X_train)
x = PrettyTable()
x.field_names = ["Model", "R^2"]
x.add_row(["Training", r2_score(y_train, y_train_pred)])
print(x)

Эй, посмотри на это! Наша модель имеет R² 1. Это должно означать, что наша модель идеальна, верно? Что ж, нам не следует слишком волноваться, потому что это значение обучения R². Давайте проверим, насколько совершенна наша модель, протестировав ее на невидимых данных.
# Predict on the testing set and calculate R^2 y_test_pred = model.predict(X_test) x = PrettyTable() x.field_names = ["Model", "R^2"] x.add_row(["Training Score ", r2_score(y_train, y_train_pred)]) x.add_row(["Testing Score ", round(r2_score(y_test, y_test_pred),3)]) print(x)
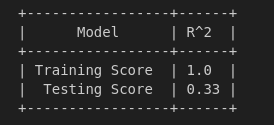
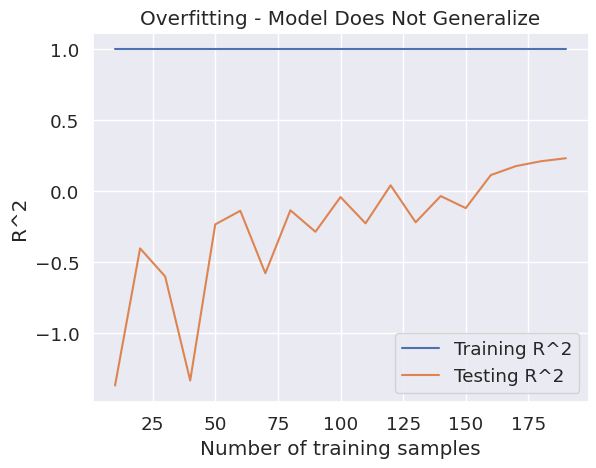
О, похоже, наша модель плохо обобщает. Если бы мы не проверили нашу модель на невидимых данных, мы могли бы обмануться, думая, что наша модель очень «хорошая». Внимательный читатель мог заметить, что использованный синтетический набор данных содержал всего 200 наблюдений в выборке, но имел 1000 признаков. Это крайний дисбаланс (для целей обучения), который может привести к переоснащению. Давайте визуализируем R² по сравнению с скорректированным R², чтобы подтвердить, соответствует ли наша модель тренировочным данным.
Сравнение с скорректированным R²:
Скорректированный R² «приспосабливается» к количеству предикторов в модели. Сравнение R² и скорректированного R² может дать вам представление о том, насколько надежен стандартный показатель. В идеале они должны быть одинаковыми.
# Create empty lists to store R^2 values
train_r2 = []
test_r2 = []
# Iterate over different amounts of training data
for i in range(10, n_samples, 10):
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X[:i], y[:i],
test_size=0.2)
# Train a linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict on the training set and calculate R^2
y_train_pred = model.predict(X_train)
train_r2.append(r2_score(y_train, y_train_pred))
# Predict on the testing set and calculate R^2
y_test_pred = model.predict(X_test)
test_r2.append(r2_score(y_test, y_test_pred))
# Ensure data is 1-D by reshaping it
train_r2_np = np.array(train_r2).flatten()
test_r2_np = np.array(test_r2).flatten()
# Generate x values
x_values = np.array(range(10, n_samples, 10)).flatten()
# Visualize R^2 values
sns.lineplot(x = x_values, y = train_r2_np, label='Training R^2')
sns.lineplot(x = x_values, y = test_r2_np, label='Testing R^2')
plt.xlabel('Number of training samples')
plt.ylabel('R^2')
plt.title('Overfitting - Model Does Not Generalize')
plt.legend()
plt.show()
# Adjusted R^2 Calculation
def adjusted_r2(r2, n, p):
return 1 - (1 - r2) * (n - 1) / (n - p - 1)
# Create a dataset with a small number of samples & a large # of predictors
X, y = make_regression(n_samples=50, n_features=40,
noise=.005, random_state=42)
# Create arrays to store R^2 and adjusted R^2 scores
r2_scores = []
adj_r2_scores = []
# Fit models with an increasing number of predictors
for p in range(1, X.shape[1] + 1):
model = LinearRegression()
model.fit(X[:, :p], y)
y_pred = model.predict(X[:, :p])
r2 = r2_score(y, y_pred)
adj_r2 = adjusted_r2(r2, X.shape[0], p)
r2_scores.append(r2)
adj_r2_scores.append(adj_r2)
# Calculate the differences and find the index of the maximum difference
diffs = np.array(r2_scores) - np.array(adj_r2_scores)
max_diff_index = np.argmax(diffs)
# Plot R^2 and adjusted R^2 as a function of the number of predictors
sns.lineplot(x=range(1, X.shape[1] + 1), y=r2_scores, label='R^2')
sns.lineplot(x=range(1, X.shape[1] + 1), y=adj_r2_scores,
label='Adjusted R^2')
# Add arrow patch at the location of the maximum difference
plt.gca().add_patch(patches.FancyArrowPatch(
(max_diff_index - 1, r2_scores[max_diff_index-1]),
(max_diff_index - 1, adj_r2_scores[max_diff_index-2]),
connectionstyle="arc3,rad=0",
arrowstyle="Simple, tail_width=0.4, head_width=6, head_length=6",
color="#444444"))
plt.xlabel('Number of predictors')
plt.ylabel('Score')
plt.title('Small Sample, Large Number of Predictors')
plt.legend()
plt.show()
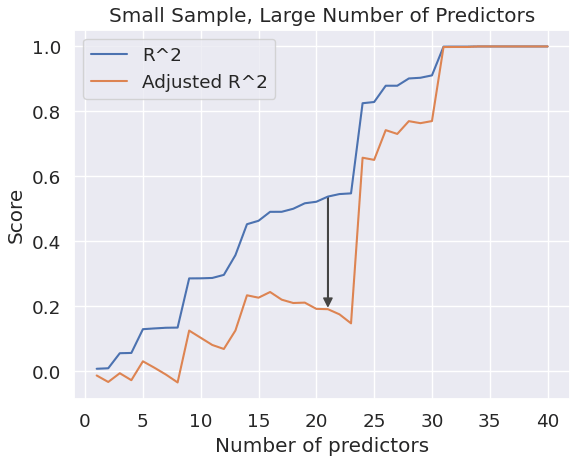
Как мы видим, наша модель определенно переобучена. Обучающая R² почти идеальна на каждом уровне обучающей выборки. Однако скорректированный R², который снижает количество функций в модели, не очень хорош. Очевидно, эти синтетические данные были придуманы для учебных целей. Тем не менее, они хорошо визуализируют модель, которая плохо обобщает и, следовательно, дает обманчивые значения R². Это особенно верно, если не удается протестировать модель на невидимых данных и имеется большое количество предикторов относительно размера выборки.
Основные предположения:
Значение R² основано на предположениях линейной регрессии; включая (1) линейность, (2) независимость ошибок, (3) постоянную дисперсию ошибок (гомоскедастичность) и (4) нормальность ошибок. Нарушения этих допущений могут сделать R² ненадежным. Давайте посмотрим на некоторые визуализации, которые могут помочь нам оценить основные предположения, необходимые для линейной регрессии.
# Generate test predictions & residuals
y_pred = model.predict(X_test)
residuals = y_test - y_pred
# Create a residuals vs. fitted values plot
sns.scatterplot(x=y_pred, y=residuals)
plt.axhline(0, color='black', linestyle='--')
# Add lowess line
lowess_line = lowess(residuals, y_pred)
plt.plot(lowess_line[:, 0], lowess_line[:, 1], color='red')
plt.xlabel('Fitted values')
plt.ylabel('Residuals')
plt.title('Residuals vs. Fitted Values')
plt.show()

# Scale - Location Plot
model_norm_residuals_abs_sqrt=np.sqrt(np.abs(residuals))
plt.figure(figsize=(7,5))
sns.regplot(x=y_pred, y=model_norm_residuals_abs_sqrt,
scatter=True,
lowess=True,
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8})
plt.ylabel('Standarized residuals')
plt.xlabel('Fitted values')
plt.title('Scale-Location')
plt.show()

Мы можем видеть на основе кривизны в линии LOWESS (локально взвешенное сглаживание диаграммы рассеяния), которую мы хотели бы максимально приблизить к черной пунктирной «идеальной» линии; что предположение о гомоскедастичности не соответствует базовой структуре данных — и, следовательно, даже при хорошем значении R² — нашей линейной модели, скорее всего, недостаточно. График Scale-Location усиливает эту идею гетероскедастичности. На этом графике мы также хотели бы видеть горизонтальную линию без указаний на глобальную закономерность в остатках.
Нелинейные отношения:
R² может вводить в заблуждение, если взаимосвязь между предиктором и переменными отклика не является линейной. Даже если значение R² велико, линейная модель может быть не лучшим выбором для данных.
# Create a nonlinear dataset
X = np.array(np.linspace(-1, 1, 100))[:, np.newaxis]
X = np.array(X)
y = X**3 + np.random.normal(scale=0.1, size=X.shape)
# Fit a linear model to the data
model = LinearRegression()
model.fit(X, y)
y_pred_linear = model.predict(X)
r2_linear = r2_score(y, y_pred_linear)
# Plot the data and the model's prediction
sns.scatterplot(x=X.squeeze(), y=y.squeeze(), color='blue', label='Data')
sns.lineplot(x=X.squeeze(), y=y_pred_linear.squeeze(), color='red',
label=f'Linear Model (R^2 = {r2_linear:.2f})')
plt.xlabel('X')
plt.ylabel('y')
plt.title('R^2 is still high - Nonlinear relationship')
plt.legend()
plt.show()
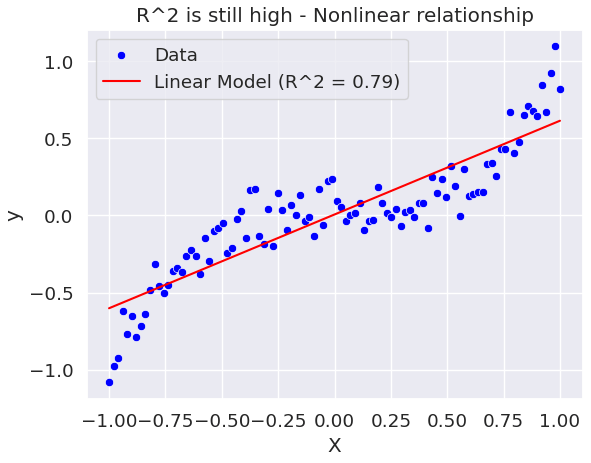
Здесь мы видим, что R² на самом деле довольно высок. Тем не менее, предиктор и ответ, по-видимому, имеют очевидную нелинейную связь. Если бы мы смотрели только на значение R², мы могли бы поверить, что наша модель довольно хороша. Однако линейная модель не может отразить истинную взаимосвязь данных. Ниже это станет еще более ясным путем добавления планок погрешностей, а также подбора нелинейной модели к данным.
# Fit a non-linear model to the data
model_poly = make_pipeline(PolynomialFeatures(degree=3),
LinearRegression())
model_poly.fit(X, y)
y_pred_poly = model_poly.predict(X)
r2_poly = r2_score(y, y_pred_poly)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(8, 12))
# Plot the data and the linear model's prediction
sns.scatterplot(x=X.squeeze(), y=y.squeeze(), color='blue',
label='Data', ax=ax[0])
sns.lineplot(x=X.squeeze(), y=y_pred_linear.squeeze(), color='red',
label=f'Linear Model (R^2 = {r2_linear:.2f})', ax=ax[0])
# Add lines between the actual points and the predicted points
for x_i, y_i, y_pred_linear_i in zip(X.squeeze(), y.squeeze(),
y_pred_linear.squeeze()):
ax[0].plot([x_i, x_i], [y_i, y_pred_linear_i], color='red',
linestyle='--', linewidth=0.5, alpha=0.5)
ax[0].set_ylabel('y')
ax[0].set_title('Linear Model - Poor Fit - Decent R^2')
ax[0].legend()
# Plot the data and the polynomial model's prediction
sns.scatterplot(x=X.squeeze(), y=y.squeeze(), color='blue', label='Data',
ax=ax[1])
sns.lineplot(x=X.squeeze(), y=y_pred_poly.squeeze(), color='purple',
label=f'Polynomial Model (R^2 = {r2_poly:.2f})', ax=ax[1])
# Add lines between the actual points and the predicted points
for x_i, y_i, y_pred_poly_i in zip(X.squeeze(), y.squeeze(),
y_pred_poly.squeeze()):
ax[1].plot([x_i, x_i], [y_i, y_pred_poly_i], color='red',
linestyle='--', linewidth=0.5, alpha=0.5)
ax[1].set_xlabel('X')
ax[1].set_title('Polynomial Model - Good Fit - Better R^2')
ax[1].set_ylabel('y')
ax[1].legend()
plt.show()


Пунктирные линии на каждом графике указывают расстояние (ошибку) между истинными значениями в данных и значениями, предсказанными линией наилучшего соответствия, которая представляет каждую модель. Полиномиальная модель гораздо лучше соответствует данным. Несмотря на то, что линейная модель имеет довольно высокое значение R² по сравнению с полиномиальной моделью, мы видим, что она вообще не сравнивается.
Прогностическая сила:
Как упоминалось ранее, R² не предоставляет информацию о предсказательной силе модели. Модель с высоким значением R² может по-прежнему давать плохие прогнозы. Как мы видим из визуализации ниже, которая отображает прогнозы наших линейных моделей для невидимых тестовых данных в сравнении с фактическими значениями; R² обманчив в том, что, хотя он относительно высок, прогнозы крайне плохи. Нам бы хотелось, чтобы точки на графике располагались как можно ближе к диагональной линии, что указывало бы на идеальные прогнозы.
# Create the plot
plt.figure(figsize=(8,6))
sns.scatterplot(x=y.squeeze(), y=y_pred_linear.squeeze())
# Ideal prediction line
plt.plot([-1, 1], [-1, 1], color='purple', linestyle='--')
# Highlight poor predictions
residuals = y - y_pred_linear
poor_pred_indices = np.where(np.abs(residuals) >
np.percentile(np.abs(residuals), 70)) # take the worst 30%
plt.scatter(y[poor_pred_indices], y_pred_linear[poor_pred_indices],
color='purple') # Highlight
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
plt.title('Predicted vs. True Values')
plt.show()

Вывод:
Хотя R² является полезной метрикой для интерпретации объяснительной силы модели линейной регрессии, она не лишена своих сложностей. Его привлекательность заключается в его простоте: единственное число, которое количественно определяет, насколько хорошо наша модель объясняет дисперсию наших данных. Однако эта простота также может быть обманчивой, и опора только на R² может привести к ошибочным интерпретациям и решениям.
Во-первых, R² не измеряет предсказательную силу модели. Модель может давать высокий R², но по-прежнему давать плохие прогнозы на невидимых данных. Важно дополнить R² другими методами проверки, чтобы обеспечить хорошее обобщение модели.
Во-вторых, R² может маскировать нелинейные отношения. Высокое значение R² может привести к тому, что мы поверим, что имеем хорошую модель, хотя на самом деле более подходящей может быть нелинейная модель. Визуализации и тесты на нелинейность могут помочь обнаружить такие отношения.
В-третьих, R² зависит от допущений линейной регрессии. Если эти предположения — линейность, независимость, гомоскедастичность и нормальность ошибок — нарушаются; R² может стать ненадежным. Диагностические графики, такие как остаточные значения по сравнению с подобранными значениями, а также график «Масштаб-местоположение» могут помочь нам визуально проверить эти предположения.
В-четвертых, R² не учитывает количество предикторов в модели, что может привести к переобучению. С другой стороны, скорректированный R² наказывает слишком сложную модель и может дать более точную картину производительности модели.
В-пятых, неправильное понимание определения и интерпретации R² может быть проблематичным. R² измеряет долю дисперсии переменной отклика, которая может быть объяснена предикторами, а не насколько «хороша» модель.
Наконец, R² может стимулировать чрезмерную подгонку, особенно когда количество предикторов близко к количеству наблюдений. Модель может «запоминать» обучающие данные, что приводит к высокому R², но плохо работать с невидимыми данными.
В свете этих потенциальных ловушек крайне важно принять целостный подход к оценке модели. Дополняйте R² другими показателями, используйте инструменты визуализации, проверяйте предположения и, самое главное, интерпретируйте результаты с осторожностью и учетом контекста. Помните, что ни одна метрика не может отразить всю производительность модели — R² — это всего лишь одна часть головоломки.