Установка R, выполнение манипуляций с данными, вплоть до применения машинного обучения с R.

Специалисты по анализу данных в настоящее время могут выбирать из множества вариантов создания статистической визуализации. Допустим, у нас самый популярный Python. С Python мы можем выполнять практически все, от классификации и регрессии машинного обучения, глубокого обучения для компьютерного зрения, НЛП до анализа звука. Помимо Python, мы можем выполнять алгоритмы машинного обучения на многих других языках, таких как JAVA, Scala, Lisp, C ++ или C #. Однако нельзя отрицать, что R является вторым наиболее востребованным навыком от Data Scientist, по крайней мере, до 2021 года согласно LinkedIn, как указано в приведенной ниже ссылке:
Приступим к загрузке
Самое первое, что нам нужно сделать, это установка. Ниже приведены инструкции по установке R как для Windows, так и для OS X:
Для Windows
1. Щелкните следующую ссылку: http://www.r-project.org/.
2. Выберите CRAN, после чего появится несколько зеркальных сайтов, отсортированных по странам.
3 . Выберите один из перечисленных сайтов в зависимости от вашей страны или страны, близкой к вашей.
4. Затем выберите Windows в разделе Загрузить и установить R.
5. Выберите base.
6. Выберите ссылку, чтобы загрузить последнюю версию R в формате .exe.
7. После завершения дважды щелкните файл .exe и начните установку, ответив на необходимые вопросы.
Для OS X
1. Щелкните следующую ссылку: http://www.r-project.org/.
2. Выберите CRAN, после чего появится несколько зеркальных сайтов, отсортированных по странам.
3 . Выберите один из перечисленных сайтов в зависимости от вашей страны или страны, близкой к вашей.
4. Затем выберите MacOS X.
5. Выберите последнюю версию предоставленного файла .pkg
6. Выберите ссылку, чтобы загрузить последнюю версию R в формате .exe.
7. После завершения дважды щелкните файл .pkg и начните установку, ответив на необходимые вопросы.
После установки вы заметите, что установлено два типа R: R i386 или R x64. Если вы думаете, что они предназначены для 32-битных и 64-битных пакетов, то вы правы. I386 предназначен для 32-разрядной версии, что немного быстрее, но вы можете использовать только 3 ГБ оперативной памяти. Между тем, для 64-разрядной версии вы можете использовать столько оперативной памяти, сколько у вас есть. Откройте то, что вам подходит, и вы увидите следующий экран:

Первая команда
Начнем с вашей самой первой команды. Как и Python, R довольно прост, например, если вы введете 1 + 1, он даст вам результат [1] 2. Здесь [1] не дает никакого значения и не дает вам количество ваших выходов. Однако, если вы не хотите его отображать, вам пригодится cat ().
Вы также можете использовать max или min, чтобы найти конкретное число, например max (5,8,7). R запросит дальнейший ввод, если знак ›изменится на +. Итак, если вы вставите max (5,8, only и нажмете Enter, нам нужно будет ввести еще один номер после +, который будет включен в команду предыдущей строки и даст нам правильный результат.
В R есть несколько методов присвоения значений переменным. Обычно мы используем x = 1. Тем не менее, также можно использовать знаки ‹-, -› или даже ‹
x <- .Last.value
Получать помощь
R легко изучить, но если вы забудете некоторые функции, вы можете просто использовать команду args (). Например, если вы используете args (mean), R расскажет вам, как использовать функцию mean:
function (x, ...) NULL
Если вы спросите, что такое функция sd, используя args (sd), он ответит вам:
function (x, na.rm = FALSE) NULL
Если вы даже не понимаете, как снова использовать функцию из примера функции, вы можете использовать команду example (), чтобы попросить R предоставить вам пример использования функции. Например, пример (sd) покажет нам:
sd> sd(1:2) ^ 2 [1] 0.5
Встроенные пакеты и наборы данных R
Подобно Python, мы также можем устанавливать пакеты в R, чтобы помочь нам в выполнении наших задач с помощью R. Есть также несколько интересных команд, связанных с пакетами, например, если мы введем
> library()
И он покажет все пакеты, которые были установлены в R, как показано ниже:

Чтобы установить новый пакет, например, чтобы установить пакет e1071, мы можем просто использовать:
> install.packages(“e1071”)
А для его обновления мы можем использовать:
> update.packages("e1071")
После установки мы можем загрузить его для использования с помощью команды:
> library(e1071)
Помимо этих предоставленных библиотек, в R также есть встроенные наборы данных, которые вы можете проверить с помощью следующей команды:
> data()
И он отобразит все предоставленные данные следующим образом:
Эти наборы данных включают хорошо известные наборы данных Iris и Titanic, которые широко используются новичками для начала работы с машинным обучением.
Управление данными диафрагмы с помощью R
Поскольку мы знаем, что набор данных Iris всегда был Hello World для машинного обучения, почему бы нам не применить его для обучения R. Во-первых, давайте загрузим данные:
> data(iris)
В Python мы можем суммировать данные, используя функцию головы Панды. В R мы можем просто использовать функцию str (), например:
> str(iris)
Отобразит нам все 5 переменных, таких как длина чашелистика, ширина чашелистика, длина лепестка, ширина лепестка и вид, как показано ниже:

Чтобы назначить переменную для выбора определенных столбцов, мы можем использовать функцию c (), например, мы можем назначить переменную Sepal.iris, чтобы указать все столбцы ширины и длины сепала, как показано ниже:
> Sepal.iris = iris[, c("Sepal.Length", "Sepal.Width")]
Следовательно, если мы суммируем Sepal.iris, он даст нам только результаты длины и ширины Sepal:

Или, отображая только первые 5 данных, мы можем установить их перед функцией c () следующим образом:
> Sepal.iris = iris[1:5, c("Sepal.Length", "Sepal.Width")]
Следовательно, мы получим только 5 данных в результате обобщения нового Sepal.iris следующим образом:

Чтобы показать, какие индексы отображают виды Setosa, мы можем использовать функцию which () следующим образом:
> which(iris$Species=="setosa")
Что покажет нам индексы:

Из этих индексов мы можем отобразить только первые 5 наборов данных по видам Setosa, установив новую переменную следующим образом:
> setosa.data = iris[which(iris$Species=="setosa"),1:5]
А если просуммировать переменную, мы получим только желаемые данные:

Вы также можете применить логическое выражение И, ИЛИ, ‹, = или› для фильтрации данных с помощью функции подмножества. Например, мы пытаемся отфильтровать данные с длиной лепестка меньше 1,4 и шириной лепестка более 1,2:
> example.data = subset(iris, Petal.Length<=1.4 & Petal.Width >= 0.2, select=Species)
Тогда мы можем узнать, что существует 21 данные с такими конкретными размерами, как следующие:

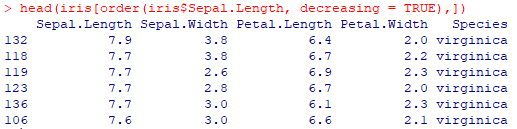
Наконец, мы можем отображать упорядоченные данные с помощью функции заказа. Например, если мы упорядочиваем данные на основе длины лепестка, это выглядит следующим образом:
> head(iris[order(iris$Sepal.Length, decreasing = TRUE),])
Он будет отображать фактический номер заказа, а также другие переменные:
Применение статистики к данным радужной оболочки с помощью R
Во-первых, давайте попробуем несколько описательных статистических данных, таких как среднее значение, стандартное отклонение, дисперсия, минимум, максимум, медиана, диапазон и квантиль от длины Iris Sepal, как показано ниже:
Иметь в виду:
mean(iris$Sepal.Length)
Среднеквадратичное отклонение:
sd(iris$Sepal.Length)
Разница:
var(iris$Sepal.Length)
Минимум:
min(iris$Sepal.Length)
Максимум:
max(iris$Sepal.Length)
Медиана:
median(iris$Sepal.Length)
Диапазон:
range(iris$Sepal.Length)
Квантиль:
quantile(iris$Sepal.Length)
Это даст нам следующий результат:

Мы также можем суммировать каждую числовую переменную, используя команду Sapply, как показано ниже:
sapply(iris[1:4],mean)
1: 4 указывает количество переменных, которые должны быть показаны в этой сводной команде. Результат следующий:

Чтобы отобразить другую статистику, например, стандартное отклонение, мы можем просто заменить команду mean на команду sd следующим образом:
sapply(iris[1:4],sd)

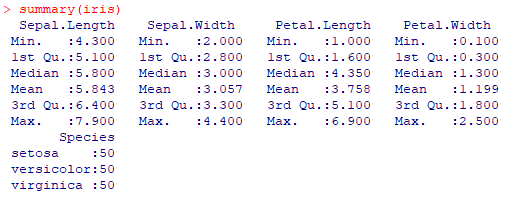
Чтобы отобразить всю описательную статистику без ввода каждой команды, просто используйте команду summary (), тогда R покажет нам каждую из этих статистических данных, включая квантиль 25% и 75% для каждой переменной. Это похоже на команду describe () из Pandas в Python.
summary(iris)
Другими простыми и интересными командами для анализа статистики являются команды cor () и cov (), которые покажут нам матрицы корреляции и ковариации между каждой переменной. Например:
Чтобы отобразить корреляционную матрицу между 4 числовыми переменными:
cor(iris[1:4])

Чтобы отобразить ковариационную матрицу между 4 числовыми переменными:
cov(iris[1:4])

Еще одна причина, по которой R делает нашу жизнь как Data Scientist намного проще, заключается в том, что мы можем выполнить T-тест с помощью предоставленной команды: t.test (), чтобы определить разницу между двумя указанными переменными. Например, мы можем измерить разницу между шириной лепестка от сетозы до разноцветного следующим образом:
t.test(iris$Petal.Width[iris$Species=="setosa"],iris$Petal.Width[iris$Species=="versicolor"])
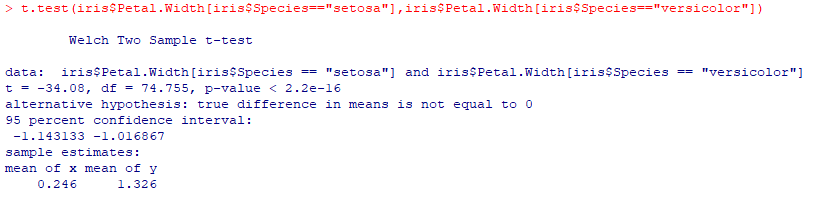
как мы видим, p-значение меньше 2.2x10 ^ -16, следовательно, они значительно отличаются, потому что единственное допустимое p-значение, чтобы они считались похожими, - это не менее 0,5.
Еще одна команда статистического расчета, которую мы можем выполнить, - это определение значения корреляции между двумя переменными с помощью команды cor.test (). Переменные более коррелированы, если их значение ближе к 1, и вряд ли будут коррелированы, если они будут ближе к -1. Давайте попробуем определить значение корреляции между длиной чашелистика и шириной чашелистика следующим образом:
cor.test(iris$Sepal.Length, iris$Sepal.Width)

Как мы видим, результат равен -0,1176, следовательно, они вряд ли будут коррелированы.
Визуализация данных для набора данных Iris с помощью R
Визуализация данных с помощью R - простая задача, поскольку команды аналогичны предполагаемой визуализации. Например, мы можем отобразить частоту появления каждого вида ирисов на круговой диаграмме с помощью команды pie (). Во-первых, давайте создадим таблицу, в которой будут отображаться следующие значения частоты:
table.iris = table(iris$Species)
Затем мы можем просто вставить значения таблицы в круговую диаграмму, чтобы отобразить их следующим образом:
pie(table.iris)
Затем R откроет новое окно, в котором отображается наша новая круговая диаграмма:
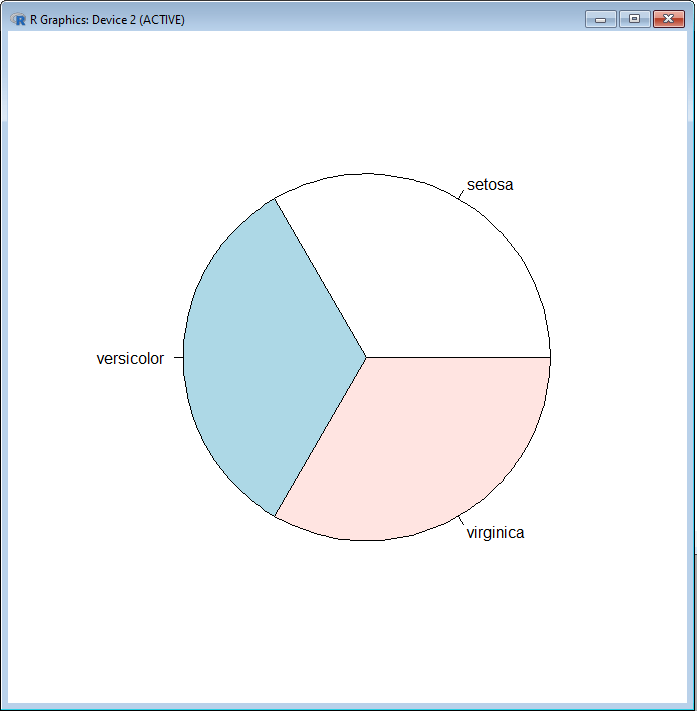
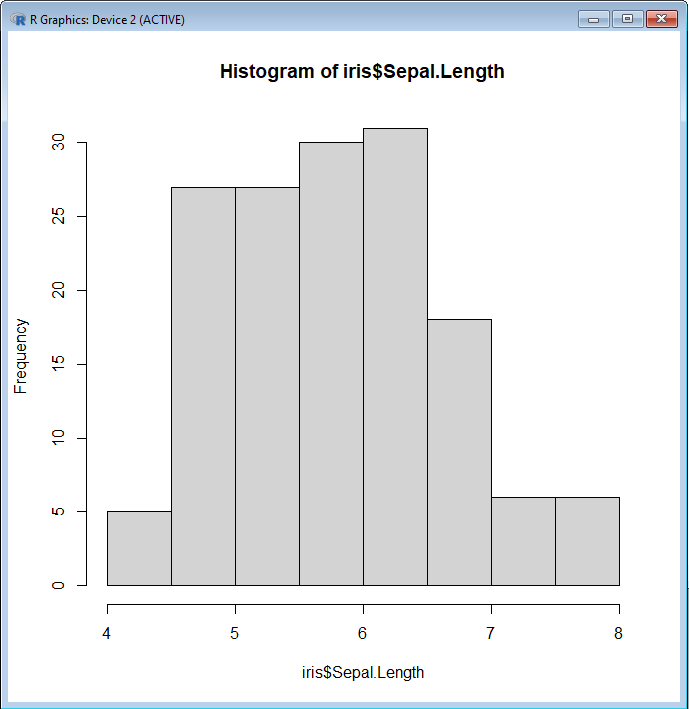
Другой пример - создание гистограммы. Мы можем отобразить его с помощью команды hist () и вставить переменную, которую мы хотели бы проанализировать, например, длину чашелистника.
hist(iris$Sepal.Length)
Далее следует коробчатая диаграмма. Так же проста, как и другие, команда boxplot также называется boxplot (). С помощью коробчатой диаграммы мы можем понять распределение переменной по квартилям. Давайте попробуем отобразить блок-схему ширины лепестка:
boxplot(Petal.Width ~ Species, data = iris)

И, наконец, мы можем создать диаграмму рассеяния, указав переменные для осей x и y с помощью команды plot (). Давайте попробуем создать диаграмму рассеяния ширины и длины лепестка для каждого вида следующим образом:
plot(x=iris$Petal.Length, y=iris$Petal.Width, col=iris$Species)
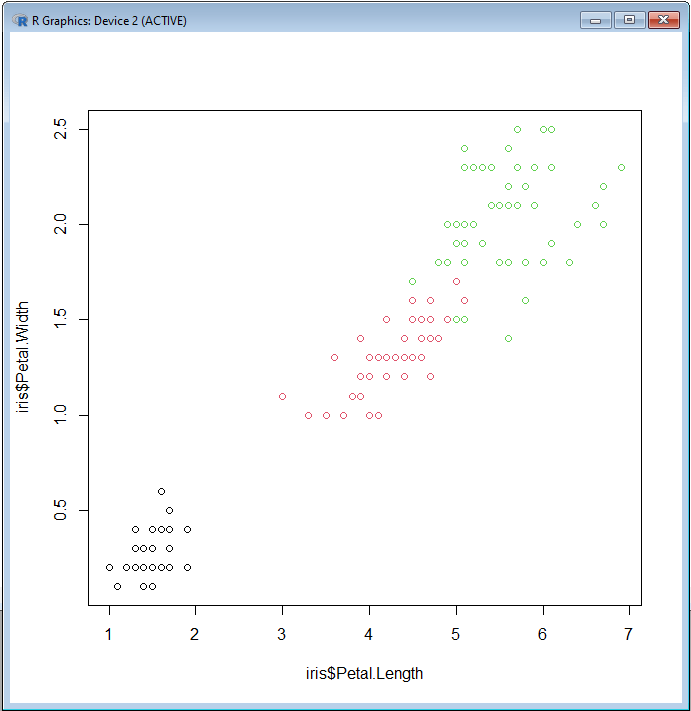
Завершение
Есть еще много функций, которые необходимо охватить, чтобы начать работу с R, однако в этой статье были рассмотрены необходимые базовые функции R и соответствующие знания для начинающих, чтобы начать получать представление об игре с R. Я надеюсь, что вы кое-что узнали и Спасибо за чтение.