работая над улучшением автозавершения кода.
Что касается разработки чего-то вроде механизма завершения кода, вы можете тестировать его все, что захотите, но вы никогда не получите всего объема того, что делает автозавершение кода, просто играя с ним самостоятельно. Вот почему одна из идей, которые были у нас с Маркусом, заключалась в том, чтобы внедрить наше новое автозавершение кода в Pharo 8 mid-GSoC, чтобы другие могли протестировать его и посмотреть, какова будет обратная связь.
Примечание: this - это исходная статья, описывающая реализацию автозавершения тестового кода в Pharo 8, а this - продолжение с дополнительными обновлениями, когда нам удалось улучшить его еще больше за пару недель.
В частности, нам удалось получить довольно много отзывов от Кирилла (спасибо Кириллу!) Относительно некоторых, на первый взгляд, безобидных DNU (ошибок «не понимает»), которые, казалось, просто нуждались в небольшой настройке. Дело в том, что, разрабатывая что-то вроде этого, у вас есть какое-то ожидание того, что может потерпеть неудачу и каким образом, или, по крайней мере, достаточно обратить внимание на шаблон, чтобы вы могли понять ошибки. Проблема заключалась в том, что эти сбои не имели полного смысла: вскоре мы увидели, что эти DNU не на 100% соответствуют нашему представлению о том, как должен вести себя наш инструмент. Исключив, что наша конкретная реализация на самом деле не виновата, мы начали изучать AST-реализацию Pharo, чтобы выяснить, в чем может быть проблема. И здесь начинается самое интересное.
Наше расследование было начато с нескольких вещей. У нас были некоторые проблемы с завершением включения и выключения временных переменных и объявлений временных переменных в течение нескольких недель. Не было никаких DNU, просто странные предложения по завершению. Или никаких предложений. Этот выпуск был одним из самых первых открытых, и в конечном итоге он стал не совсем таким, каким он был вначале.
Затем была еще одна проблема с DNU на RBReturnNode, которую получил Кирилл, описанная здесь. Ошибка не имела полностью смысла, и мы не могли сразу найти реальное решение для нее.
Потом, через пару дней, возникла еще одна проблема, задокументированная здесь. Хорошо! Похоже, мы нашли виновника - #bestNodeFor: который был одной из самых важных вещей, которые мы использовали для сопоставления узлов - похоже, не работал так хорошо, как мы думали. Дело в том, что мы использовали #bestNodeFor: при создании нашей модели, и цель этого метода заключалась в том, чтобы войти в код, который мы дали ему, для анализа и поиска наилучшего возможного узла для той части, которую мы завершаем.
Например, если мы были в методе, это был узел метода. Но если вы пишете временное объявление, #bestNodeFor: должен был распознавать для нас, что это был временный узел, и если это была отправка сообщения, которую мы пытались завершить, это должен был быть узел сообщения. И все же, хотя #bestNodeFor: отлично работал с отправкой сообщений, что-то не так с временным узлом. И с узлом последовательности. И видимо с обратным узлом. Казалось очевидным: если мы исправим #bestNodeFor: метод, который использовался в Pharo уже много лет и который мы просто считали само собой разумеющимся, мы исправим наши проблемы.
Начав изучение, мы увидели, что, хотя он был реализован на RBProgramNode (суперкласс других узлов) и переопределен для некоторых узлов, #bestNodeFor: не был переопределен во всех подклассах. Например, у RBMethodNode этого не было. "Там!" мы думали. Таким образом, метод, который должен был искать подузлы внутри узла метода, не работал должным образом, потому что не имел специально адаптированной реализации. Что, если мы просто добавим его на узлы, где он отсутствует? Это должно позаботиться об этом , - была моя идея. Между тем, Маркус был обеспокоен тем, что из-за #bestNodeFor: мы могли не получить правильное смещение, поскольку у нас были некоторые проблемы с this. Что, если мы просто реализуем совершенно новый метод, который будет зависеть не от интервала, а от точного смещения, мы дадим ему И также метод, который будет лучше при рекурсии и, следовательно, не будет реализован для каждого из узлов? была идея Маркуса. Стремясь к спецификации и масштабируемости, конечно, предпочитают последнее.
Мы создали метод #nodeForOffset: (PR; получение правильной рекурсии потребовало дополнительного времени), но он не решил ни одной из наших проблем. В счастливом повороте событий, все еще проверяя, повторно проверяя и отлаживая те же две строки кода (ниже), мы увидели, что способ измерения RBSequenceNode позиции остановки был неправильным (описан здесь).
ast := RBParser parseMethod: 'test | te|'. ast bestNodeFor: (10 to: 10)
По сути, RBSequenceNode всегда возвращал 0 в качестве позиции остановки, если после объявления temp не было операторов, и поэтому, КОНЕЧНО, он не мог обнаружить временный узел внутри узла последовательности - он даже не мог видеть, что было объявление temp. В конце концов, исправить это было не так сложно (пиар) - нам просто нужно было занять максимально дальнюю позицию. Итак, наконец, эта проблема была исправлена.
А что насчет RBReturnNode? У нас был DNU для узла возврата для кода ниже. Но, учитывая позицию курсора в «asSe», это не должно было быть ошибкой возвращаемого узла.
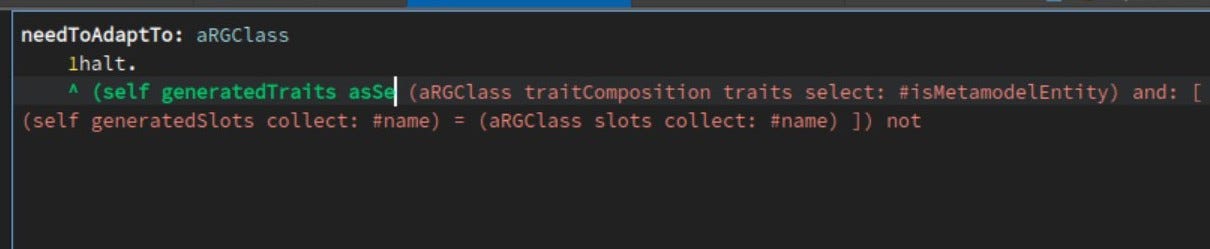
Во-первых, чтобы упростить его, я решил, что лучше избавиться от неправильного синтаксиса, и поэтому наш «тестовый» пример в итоге выглядел так:
needToAdaptTo: aRGClass
^ (self generatedTraits asSe )
То есть я попытался написать его как с «)» в конце, так и без него. Когда стояли закрывающие круглые скобки, все казалось нормально! Мы знали, что завершаем отправку сообщения. С этого момента мы начали анализировать приведенный выше код без закрывающих скобок, вот так:
needToAdaptTo: aRGClass
^ (self generatedTraits asSe
На этом мы наконец сосредоточились на ParseErrorNode - узле, который появляется, когда у нас неправильный синтаксис: в чем проблема?
Ответ пришел очень быстро и внезапно. Когда Pharo обнаруживает, что закрывающих скобок нет, он предлагает это - хорошо, имеет смысл. И позиция остановки ошибки находится точно в том месте, где должны быть закрывающие круглые скобки - отлично, круто! А потом без всякой причины: отсчитывается длина ошибки! Другими словами, мы знаем длину неправильного выражения (назовем его N), но вместо того, чтобы отсчитывать назад от остановки, чтобы начать ошибку там, где начинается неправильное выражение (в данном случае открывающие круглые скобки), оно было случайным образом помещая начальное количество позиций N после конца. Уф, неудивительно, что мы не знали правильный узел - мы не могли войти внутрь ошибки, потому что ошибка, которую увидел Pharo, была не тем фрагментом кода, который видел пользователь, как фактическая ошибка!
Исправив реализацию начальной позиции (PR), мы наконец начали распознавать приведенный выше фрагмент кода как RBParseErrorNode - как и должно быть (чего мы не знали в начале). Другими словами, не будет завершения, но также не будет DNU, потому что у нас уже есть код для работы с узлами ошибок синтаксического анализа (конечно, у нас есть некоторые планы как-то обойти неправильный синтаксис и найти способ предлагать предложения в любом случае - то, чего никогда не было в старой реализации доработки).
Затем возникла проблема с объявлением временного интервала, когда не было закрывающей полосы |. Потому что, когда закрывающая полоса была на месте, мы знали, что это временный узел (перейдите к тому месту, где мы зафиксировали узел последовательности), но в остальном он интерпретировал его как часть метода, что, очевидно, было большой проблемой. Почему? Из-за этого". Мы хотели завершить определения селекторов методов, потому что многие сочли это полезным. Мы не могли написать ни единого фрагмента кода, который давал бы правильные предложения как для селектора метода, так и для имени временной переменной, и тем не менее оба они попали в одну категорию: RBMethodNode. Наконец, мы поняли, что технически объявление temp без закрытия "|" должно рассматриваться как узел ошибки, но это не так. Это привело нас к обнаружению отсутствия поддержки узла ошибок синтаксического анализа для |, что мы в конечном итоге реализовали в том же PR (см. RBParser ›› parseErrorNode: aMessageString).
И, конечно же, наконец осознав, что неполное объявление temp относится к узлу ошибки, мы смогли завершить определения методов.
В целом, это было потрясающее упражнение, чтобы разобраться во всем этом. В этом сообщении в блоге я попытался отдать ему должное и как можно точнее проследить наш мыслительный процесс, поэтому было бы так же интересно прочитать его, как на самом деле выполнить его, а затем описать. Надеюсь, это тоже пригодится. Я знаю, что не так много мест, где можно просто изучить каждый бит кода, отладить и проверить все, но я рад, что Pharo - это то место, и я благодарен людям, которые помогали и продолжают помогать Я научился этому мышлению обратной инженерии.
Проблемы с Github для справки:
1. https://github.com/myroslavarm/Experimental-Completion/issues/65
2. https: // github. com / pharo-project / pharo / issues / 4045
3. https://github.com/myroslavarm/Experimental-Completion/issues/49
4. https: // github. com / myroslavarm / Experimental-Completion / issues / 60
5. https://github.com/pharo-project/pharo/issues/4060
6. https: // github. ru / myroslavarm / Experimental-Completion / issues / 62
Примечание: некоторые проблемы в моем репозитории (экспериментальное завершение) и репозитории Pharo по сути одинаковы, чтобы упростить документирование.
Запрос на вытягивание Github для справки:
1. https://github.com/pharo-project/pharo/pull/4053
2. https: // github .com / pharo-project / pharo / pull / 4049
3. https://github.com/pharo-project/pharo/pull/4062
Сообщения в блоге, чтобы узнать больше о нашей реализации автозавершения кода:
1. Улучшение автозавершения кода на GSoC 2019: введение
2. Прогресс с автозавершением кода [июнь]
3. В Pharo 8 добавлено завершение тестового кода!
4. Последнее обновление завершения: проще, лучше