Что вы делаете, когда данные говорят вам о расизме?
«Конечно, алгоритмы расистские. Их делают люди ». - Стивен Буш, New Statesman America

Этика в машинном обучении
В большинстве случаев машинное обучение не затрагивает особо деликатных социальных, моральных или этических вопросов. Кто-то дает нам набор данных и просит нас спрогнозировать цены на жилье на основе заданных атрибутов, классифицируя изображения по различным категориям или обучая компьютер тому, как лучше всего играть в PAC-MAN - что мы делаем, когда нас просят основывать прогнозы защищенных атрибуты в соответствии с антидискриминационными законами?
Как мы гарантируем, что мы не внедряем расистские, сексистские или другие потенциальные предубеждения в наши алгоритмы, будь то явным или неявным образом?
Возможно, вас не удивит, что в Соединенных Штатах было несколько важных судебных процессов по этой теме, возможно, самый заметный из них касался спорного программного обеспечения COMPAS от Northpointe - Профилирование исправительных правонарушителей для альтернативных санкций - программного обеспечения, которое прогнозирует риск того, что обвиняемый совершит еще один преступление. Собственный алгоритм учитывает некоторые ответы из вопросника из 137 пунктов, чтобы предсказать этот риск.
В феврале 2013 года Эрика Лумиса нашли за рулем автомобиля, использованного в перестрелке. Он был арестован и признал себя виновным в ускользании от офицера. При вынесении приговора судья обращал внимание не только на его судимость, но и на оценку, выставленную инструментом COMPAS.
COMPAS - один из нескольких алгоритмов оценки риска, которые сейчас используются в Соединенных Штатах для прогнозирования горячих точек насильственных преступлений, определения типов надзора, которые могут понадобиться заключенным, или - как в случае с Лумисом - предоставления информации, которая может быть полезна при вынесении приговора. . КОМПАС отнес его к категории лиц с высоким риском повторного совершения преступления, и Лумис был приговорен к шести годам заключения.
Он обжаловал это решение на том основании, что судья при рассмотрении результатов алгоритма, внутренняя работа которого была скрытной и не могла быть исследована, нарушил надлежащую правовую процедуру. Апелляция была подана в Верховный суд штата Висконсин, который вынес решение против Лумиса, отметив, что приговор был бы таким же, если бы КОМПАС никогда не проконсультировался. Однако их постановление призывает к осторожности и скептицизму при использовании алгоритма.
Этот случай, по понятным причинам, вызвал настоящий переполох в сообществе машинного обучения - я сомневаюсь, что кто-то захочет, чтобы его оценивали по алгоритму, в конце концов, вы же не можете обвинить алгоритм в неэтичности, не так ли?
Споры нарастают
Пока что все, что мы обсуждали, - это предположительно несправедливый человек, которого якобы жестко судили с помощью алгоритма. Однако споры вокруг этого программного обеспечения становятся немного более острыми, когда мы переносимся в 2014 год.
После того, как алгоритм выплюнул и тщательно изучил еще несколько спорных результатов, он снова привлек внимание общественности. Затем генеральный прокурор США Эрик Холдер предупредил, что оценка риска может вносить предвзятость в суды. Он призвал Комиссию по вынесению приговоров США изучить их использование. «Хотя эти меры были разработаны с наилучшими намерениями, я обеспокоен тем, что они непреднамеренно подрывают наши усилия по обеспечению индивидуального и равного правосудия, - сказал он, добавив, - что они могут усугубить неоправданные и несправедливые различия, которые уже слишком распространены в нашей стране. система уголовного правосудия и в нашем обществе ».
Однако комиссия по вынесению приговора не начала исследование оценок риска. Так ProPublica сделала, как часть более обширного исследования мощного, в значительной степени скрытого эффекта алгоритмов в американской жизни.
Экспертиза ProPublica сделала несколько интересных выводов. Алгоритм был не только абсурдно неточным (верным было менее 20% его прогнозов), но и демонстрировал значительные расовые различия, чего и опасался Холдер. При прогнозировании того, кто совершит повторное преступление, алгоритм допускал ошибки с черными и белыми обвиняемыми примерно с одинаковым процентом, но очень разными способами.
- Эта формула была особенно вероятна для ложного обозначения черных подсудимых как будущих преступников, ошибочно называя их таким образом почти в два раза чаще белыми подсудимыми.
- Белых подсудимых чаще ошибочно относили к категории лиц с низким уровнем риска, чем черных подсудимых.
У чернокожих обвиняемых по-прежнему на 77 процентов выше вероятность того, что они будут подвергнуты более высокому риску совершения в будущем насильственного преступления, и на 45 процентов с большей вероятностью будет предсказано совершение в будущем преступления любого рода.
Это может показаться плохим, но в этой истории есть нечто большее, чем кажется на первый взгляд. В зависимости от того, как мы это анализируем, мы можем обнаружить, что алгоритм является одновременно расистским, а не расистским, это зависит от того, как мы определяем «равенство» в нашей модели. В оставшейся части этой статьи я постараюсь помочь нам понять, что эта модель на самом деле была разработана приемлемым образом, но все же может давать якобы расистские результаты.
Типы дискриминации
Сначала нам нужно определить типы дискриминации, которые возможны в алгоритмах, и с какими типами мы имеем дело в наших предыдущих примерах. Существует две формы дискриминации, которые мы будем называть разрозненным воздействием и разрозненным обращением.
Несоразмерное отношение - подразумевает недопустимую классификацию кого-либо. Он включает в себя намерение различать, о чем свидетельствует явная ссылка на членство в группе.
Несопоставимое влияние - анализирует последствия классификации / принятия решений для определенных групп. Никакого намерения не требуется, он нейтральный по внешнему виду.
Несопоставимое воздействие часто называют непреднамеренной дискриминацией, тогда как разрозненное отношение является преднамеренным.
По мнению Верховного суда, практики, оказывающие непропорционально сильное воздействие на конкретную группу, не вызывают несоразмерных последствий, если они «основаны на разумных деловых соображениях».
При рассмотрении любого из следующих защищенных атрибутов можно вызвать несопоставимое обращение или разное воздействие.

Все эти атрибуты могут использоваться в качестве функций в наших алгоритмах машинного обучения, и, таким образом, наши алгоритмы могут различать на основе этих атрибутов. Некоторыми распространенными примерами этого являются распознавание лиц, рецидив (как обсуждалось ранее) и прием на работу. Что мы можем сделать, чтобы с этим бороться?
Бороться с разрозненным обращением легко. Явная дискриминационная предвзятость делает классификацию менее точной, поэтому для этого нет веских причин. Однако как насчет случаев, когда дискриминация встроена в исторические данные? Или атрибуты являются результатом прошлой социальной несправедливости, которая сохраняется до сих пор?
Дискриминационная предвзятость в обучающих данных
Дискриминация влияет на социальные блага, когда классификация и принятие решений основаны на неточной информации (например, если вы думаете, что каждый старше 7 футов - плохая няня). Эти идеи часто поддерживаются человеческими предубеждениями и внедряются в данные, которые используются для обучения алгоритмов.
В этом случае человеческие предубеждения не смягчаются алгоритмом машинного обучения. Фактически, они воспроизводятся в сделанных классификациях. Почему это происходит? Оценки рецидивов, например, полученные с помощью программного обеспечения Northpointe, основаны на предыдущих арестах, возрасте первого обращения в полицию, записях родителей о лишении свободы. Эта информация сформирована предубеждениями в мире (например, культурными ценностями и национализмом) и несправедливостью в целом (например, расовыми предрассудками).
Эта предвзятость также присутствует при обработке естественного языка, которая фокусируется на текстовых данных. Хорошим примером этого является исследование под названием «Мужчина для программиста, как женщины для домохозяйки? Debiasing Word Embeddings », которая показывала автоматически генерируемые аналогии из векторов программного обеспечения, такие как мужчина → компьютерный программист и женщина → домохозяйка. Они отражают сексизм в оригинальных текстах.
В более общем плане эти источники предвзятости обычно возникают из-за:
- Избыточная и заниженная выборка
- Перекошенный образец
- Выбор функций / ограниченные возможности
- Прокси / избыточные кодировки
- Предубеждения и несправедливость в мире
Так как же нам избавиться от этих предубеждений? Алгоритмы машинного обучения могут закрепить дискриминацию, потому что они обучаются на предвзятых данных. Решение состоит в том, чтобы определить или сгенерировать беспристрастный набор данных, из которого можно сделать точные обобщения.
Удаление предубеждений
Такие характеристики, как раса, пол и социально-экономический класс, определяют другие особенности нас, которые имеют отношение к результату некоторых служебных задач. Это защищенные атрибуты, но они по-прежнему актуальны для определенных задач производительности - и задач производительности, которые являются предполагаемыми социальными благами. Например:
- Среднее благосостояние белых семей в семь раз выше, чем среднее благосостояние черных семей.
- Богатство имеет значение для того, сможете ли вы выплатить ссуду.
- Различия в богатстве определяются исторической и нынешней несправедливостью.
Машинное обучение по своей природе историческое. Чтобы эффективно бороться с дискриминацией, нам необходимо изменить эти модели. Однако машинное обучение усиливает эти закономерности. Следовательно, машинное обучение может быть частью проблемы.
«Даже если история - это дуга, ведущая к справедливости, машинное обучение не изменится».
Так куда мы идем отсюда? Обречены ли мы на расистские и сексистские алгоритмы?
Даже когда мы оптимизируем для точности, алгоритмы машинного обучения могут увековечить дискриминацию, даже если мы работаем с объективным набором данных и имеем в виду задачу производительности, которая имеет в виду социальные блага. Что еще мы могли сделать?
- Последовательное обучение
- Больше теории
- Причинное моделирование
- Оптимизация для справедливости
Из всего этого оптимизация для справедливости кажется самым простым и лучшим способом действий. В следующем разделе мы расскажем, как оптимизировать модель для обеспечения справедливости.
Оптимизация для справедливости
Построение алгоритмов машинного обучения, оптимизированных для предотвращения дискриминации, можно осуществить 4 способами:
- Формализация критерия недискриминации
- Демографический паритет
- Уравненные шансы
- Хорошо откалиброванные системы
Мы обсудим каждый из них по очереди.
Формализация критерия недискриминации - это, по сути, то, что включают другие 3 подхода, они являются типами критериев, которые направлены на формализацию критерия недискриминации. Однако этот список не является исчерпывающим, и могут быть лучшие подходы, которые еще не были предложены.
Демографический паритет предполагает, что решение (целевая переменная) не должно зависеть от защищаемых атрибутов - раса, пол и т. д. не имеют отношения к решению.
Для двоичного решения Y и защищенного атрибута A:
P(Y=1 ∣ A=0) = P(Y=1∣A=1)
Вероятность принятия какого-либо решения (Y = 1) должна быть одинаковой, независимо от защищенного атрибута (будь то (A = 1) или (A = 0)). Однако демографический паритет исключает использование идеального предиктора C = Y, где C - предиктор, а Y - целевая переменная.
Чтобы понять возражение, рассмотрим следующий случай. Допустим, мы хотим предсказать, купит ли человек органический шампунь. Покупают ли члены определенных групп органический шампунь, зависит от их принадлежности к этой группе. Но демографический паритет исключает возможность использования идеального предсказателя. Так что, может быть, это не лучшая процедура, может быть, другие дадут нам лучший результат?
Приведенные шансы предполагает, что предиктор и защищенный атрибут должны быть независимыми и зависеть от результата. Для предиктора R, результата Y и защищенного атрибута A, где все три являются двоичными переменными:
P(R=1|A=0, Y=1) = P(R=1|A=1, Y=1).
Атрибут (независимо от того, (A = 1) или (A = 0)) не должен изменять вашу оценку (P) того, насколько вероятно, что некоторый релевантный предиктор (R = 1) верен для кандидата. Вместо этого должен быть результат (какого-то решения) (Y = 1). Преимущество этой процедуры в том, что она совместима с идеальным предсказателем R = Y.
Рассмотрим следующий случай, в котором учащийся поступает в Йельский университет, учитывая, что он выступал с прощальным словом в своей старшей школе. Выравнивание шансов утверждает, что знание того, является ли студент геем, не меняет вероятность того, был ли студент прощальным.
Predictor R = были ли вы выпускником средней школы (1) или нет (0)
Результат Y = поступить в Йельский университет (1) или нет (0)
Атрибут A = быть геем (1), быть натуралом (0)
P(R=1| A=0, Y=1) = P(R=1| A=1, Y=1).
Хорошо откалиброванные системы предполагают, что результат и защищенный атрибут независимы и зависят от предиктора. Для предиктора R, результата Y и защищенного атрибута A, где все три являются двоичными переменными:
P(Y=1|A=0, R=1) = P(Y=1|A=1, R=1)
Вероятность наступления некоторого результата (Y = 1) не должна зависеть от какого-либо защищенного атрибута (будь то (A = 0) или (A = 1)), а вместо этого должна зависеть от соответствующего предиктора (R = 1). Эта формулировка имеет то преимущество, что она не знает группы - она придерживается одного стандарта.
В отличие от нашего предыдущего примера, знание того, что студент гей, не меняет вероятность того, поступил ли студент в Йельский университет. Различие между уравновешенными шансами и хорошо откалиброванными системами тонкое, но важное.
Фактически, это различие является причиной разногласий по поводу программного обеспечения КОМПАС, которое мы обсуждали в начале.
Так является ли КОМПАС расистским?
Уравненные шансы и хорошо откалиброванные системы - несовместимые стандарты. Иногда, учитывая определенные эмпирические обстоятельства, мы не можем добиться, чтобы система была одновременно хорошо откалибрована и уравновешивала шансы. Давайте посмотрим на этот факт в контексте дебатов между ProPublica и Northpointe о том, предвзято ли COMPAS против чернокожих обвиняемых.
Y = будет ли обвиняемый совершать повторное преступление
A = раса ответчика
R = предсказатель рецидивизма, используемый КОМПАС
Защита Нортпойнта: система COMPAS хорошо откалибрована, т. е.
P(Y=1|A=0, R=1) = P(Y=1|A=1, R=1).

Система КОМПАС делает примерно одинаковые прогнозы рецидивов для обвиняемых, независимо от их расы.
Возражение ProPublica: COMPAS имеет более высокий уровень ложноположительных результатов для черных обвиняемых и более высокий уровень ложноотрицательных результатов для белых обвиняемых, т. е. не удовлетворяет уравненным шансам:
P(R=1|A=0, Y=1) ≠ P(R=1|A=1, Y=1)
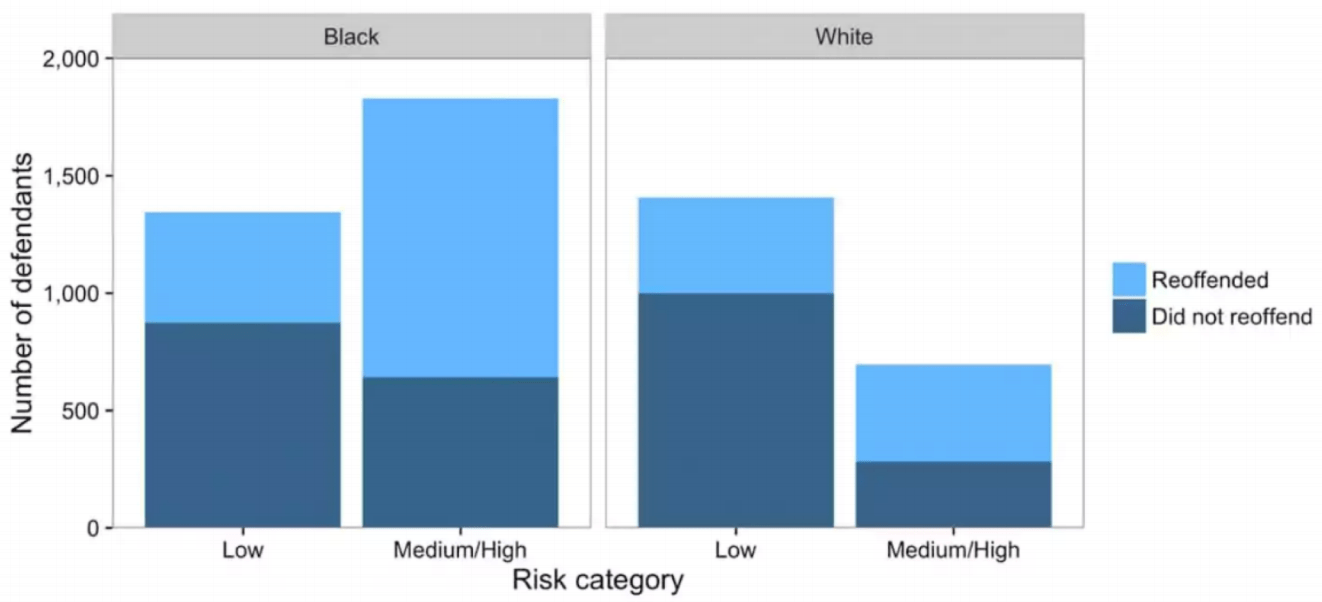
От расы ответчика зависит, находится ли человек в категории низкого или среднего / высокого риска. Независимо от того, будет ли (A = 0) или (A = 1) иметь значение для вероятности того, что COMPAS определил какой-либо предиктор риска рецидивизма, будет придерживаться ответчика (P (R = 1)), а не только то, будет ли ответчик / выиграть » t повторно оскорбить (Y = 1).
Почему это произошло?
Когда верны определенные эмпирические факты, наша способность иметь хорошо откалиброванную и уравновешивающую систему ломается. Кажется, что проблема порождает то, что мы обсуждали ранее: фоновые факты, созданные несправедливостью. Например, более высокие показатели уличения в повторном правонарушении из-за более тщательной проверки со стороны полиции.
Трудно понять, когда должны применяться определенные критерии справедливости. Если какой-то критерий не дорого обходится другим, тогда вы меньше беспокоитесь о применении одного, когда не уверены. Но поскольку это не так, нам нужно понимать последствия несоблюдения некоторых критериев.
Итак, какие из обсуждаемых нами критериев лучше всего выбрать? У всех этих подходов есть многообещающие особенности, но у всех есть свои недостатки.
И что теперь?
Мы не можем отделить справедливость в одном уголке, не борясь за то, чтобы изменить несправедливость в мире и дискриминацию, которая происходит за пределами систем машинного обучения. Это не значит, что мы ничего не можем сделать! Мы должны установить некоторые стандарты справедливости в определенных областях, в то же время стремясь изменить базовые ставки.
Несмотря на несколько разногласий и непопулярность среди некоторых, программное обеспечение КОМПАС продолжает использоваться по сей день. Никто, кто разрабатывает алгоритм, не хочет, чтобы его обвинили или посадили в тюрьму за неосознанную разработку расистского алгоритма, но некоторые критерии должны быть выбраны для обоснования прогнозов в ситуациях, подобных той, с которой COMPAS пытается справиться.
Это может быть алгоритм, и он может быть несовершенным, но это только начало, и нужно с чего-то начинать.
Может ли машинное обучение помочь уменьшить дискриминацию?
Машинное обучение - чрезвычайно мощный инструмент. Это становится все более очевидным по мере того, как человечество начинает переходить от гуманистических к информативным взглядам, когда мы начинаем доверять алгоритмам и данным больше, чем людям или нашим собственным мыслям (некоторые люди въезжали в озера, потому что их GPS тоже сказал им!). Это делает чрезвычайно важным, чтобы мы старались сделать алгоритмы максимально непредвзятыми, чтобы они не увековечили бессознательно социальную несправедливость, заложенную в исторических данных. Однако есть также огромный потенциал использования алгоритмов для создания более справедливого и равноправного общества. Хороший пример этого - процесс найма.
Допустим, вы подаете заявку на работу своей мечты и находитесь на заключительном этапе собеседования. Менеджер по найму имеет право определять, наняты вы или нет. Хотели бы вы, чтобы беспристрастный алгоритм определил, подходите ли вы для этой работы лучше всего?
Вы бы предпочли это, если бы знали, что менеджер по найму был расистом? Или сексист?
Возможно, менеджер по найму - очень нейтральный человек и основывает свою работу исключительно на заслугах, однако у каждого есть свои склонности и лежащие в основе когнитивные предубеждения, которые могут повысить вероятность выбора кандидата, который им больше всего нравится, а не лучшего человека. для работы.
Если удастся разработать беспристрастные алгоритмы, процесс найма может стать быстрее и дешевле, а их данные могут привести рекрутеров к более высококвалифицированным людям, которые лучше подходят для их компаний. Другой возможный результат: более разнообразное рабочее место. Программное обеспечение полагается на данные, чтобы находить кандидатов из самых разных мест и подбирать их навыки в соответствии с требованиями работы, без каких-либо человеческих предубеждений.
Возможно, это не идеальное решение, на самом деле, когда дело доходит до правосудия, идеального ответа нет. Однако, судя по всему, история имеет тенденцию к справедливости, так что, возможно, это даст правосудию еще один шаг вперед.
Еще один хороший пример - автоматическое андеррайтинг кредита. По сравнению с традиционным ручным андеррайтингом, автоматический андеррайтинг более точно предсказывает, не произойдет ли дефолт по ссуде, а его большая точность приводит к более высоким показателям одобрения заемщиков, особенно для недостаточно обслуживаемых заявителей. Результатом этого является то, что иногда алгоритмы машинного обучения работают лучше, чем мы, при составлении наиболее точных классификаций, а иногда это борется с дискриминацией в таких областях, как прием на работу и одобрение кредита.
Пища для размышлений
В завершение такой длинной и серьезной статьи я предлагаю вам обдумать цитату из Google о дискриминации в машинном обучении.
Оптимизация для обеспечения равных возможностей - это лишь один из многих инструментов, которые можно использовать для улучшения систем машинного обучения, и одна только математика вряд ли приведет к лучшим решениям. Противодействие дискриминации в машинном обучении в конечном итоге потребует тщательного междисциплинарного подхода . - Google
Новостная рассылка
Чтобы получать обновления о новых сообщениях в блогах и дополнительном контенте, подпишитесь на мою рассылку.
Ссылки
[1] О'Нил, Кэти. Оружие разрушения математики: как большие данные увеличивают неравенство и угрожают демократии. Корона, 2016.
[2] Гарви, Клэр; Франкл, Джонатан. Программное обеспечение для распознавания лиц может иметь проблемы с расовым уклоном. Атлантика, 2016.
[3] Толга Болукбаси, Кай-Вей Чанг, Джеймс Цзоу, Венкатеш Салиграма, Адам Калай. Мужчина для программиста, как женщина для домохозяйки? Сглаживание вложений слов. Arxiv, 2016.
[4] CS181: Машинное обучение. Гарвардский университет, 2019.