Najlepsze praktyki skrobania danych przy użyciu selenu w Pythonie

Selen do skrobania sieci
Selenium to biblioteka automatyzacji przeglądarki. Najczęściej używany do testowania aplikacji internetowych, Selenium może być używany do dowolnego zadania wymagającego automatyzacji interakcji z przeglądarką. Może to obejmować skrobanie sieci.
Poniższy samouczek będzie prowadzonym przez użytkownika przewodnikiem po najlepszych praktykach przeglądania stron internetowych przy użyciu selenu. Podałem 5 najważniejszych wskazówek, które pomogą użytkownikowi zebrać żądane dane tak efektywnie, jak to możliwe, używając Pythona z jak najmniejszą ilością kodu.
Cel:
Aby wyodrębnić światowe nagłówki dotyczące wirusa Koronawirus z wiadomości BBC.
Warunki wstępne
Aby skorzystać z tego samouczka, będziesz potrzebować:
- Pobierz webdriver Selenium. Sterownika Chrome można używać do interakcji z Chrome i jest on dostępny tutaj.
pip install selenium
5 wskazówek dotyczących najlepszych praktyk dotyczących Selenu
Wskazówka 1: Umieść plik wykonywalny sterownika internetowego w PATH
Aby rozpocząć nasze zadanie przeglądania sieci, musimy najpierw przejść do następnej strony „https://www.bbc.co.uk/news”. Ten krok można wykonać w zaledwie trzech liniach kodu. Najpierw importujemy webdriver z Selenium, tworzymy instancję chrome webdriver i na koniec wywołujemy metodę get na obiekcie webdriver o nazwie Driver.
Aby kod był krótki i czytelny, plik wykonywalny chromedriver można umieścić w folderze wybranym przez użytkownika. To miejsce docelowe można następnie dodać do PATH w zmiennych środowiskowych. Sterownik sieciowy jest wtedy gotowy do pracy — wystarczy użyć funkcji webdriver.Chrome() bez żadnych argumentów przekazywanych do przeglądarki Chrome w nawiasach.
Wskazówka 2. Znajdź dowolny element sieciowy za pomocą konsoli
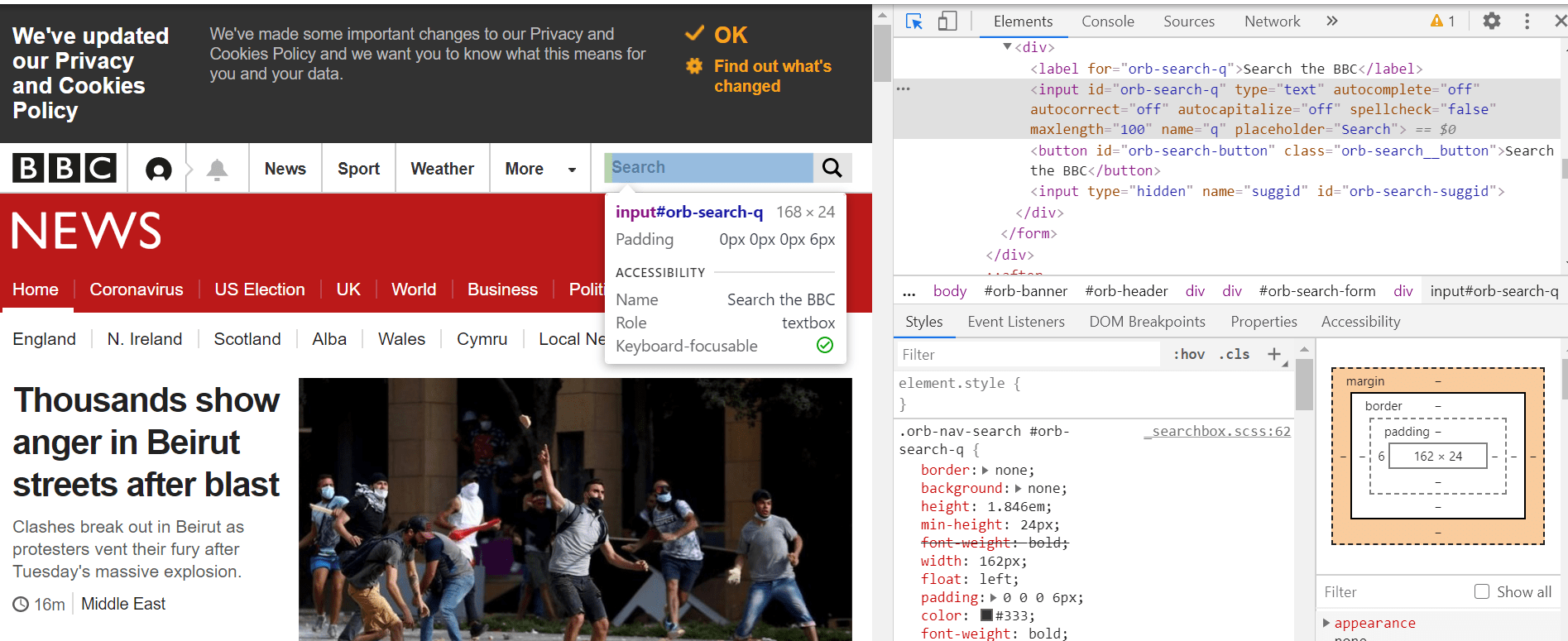
Po przejściu na stronę internetową chcielibyśmy znaleźć pole wyszukiwania, kliknąć je i zacząć wpisywać „globalne aktualizacje dotyczące koronawirusa”.
Aby znaleźć ten element sieciowy, możemy po prostu kliknąć prawym przyciskiem myszy Chrome i wybrać opcję Sprawdź. W lewym górnym rogu strony, która otwiera się podczas sprawdzania, możemy użyć kursora, aby najechać kursorem i wybrać interesujące nas elementy internetowe. Jak pokazano, pole wyszukiwania ma znacznik wejściowy z wartością identyfikatora „orb-search-q”.
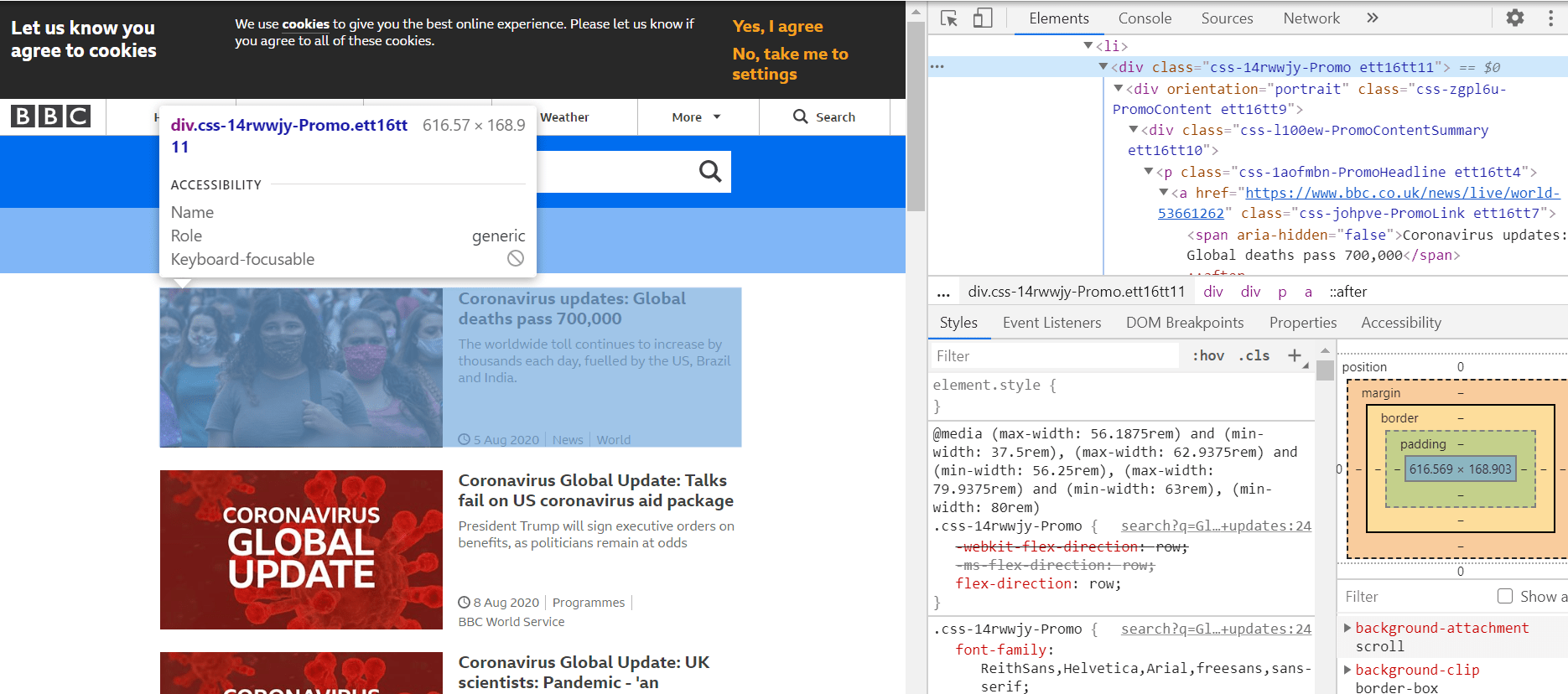
Jak możemy mieć pewność, że będzie to jedyny element wyszukiwania, który nas interesuje?
Możemy po prostu wybrać okno zakładki konsoli, a następnie wpisać dwa znaki dolara, po których następują nawiasy i cudzysłowy. Wewnątrz cudzysłowów wpisujemy dane wejściowe tagu, po których umieszczamy nawiasy kwadratowe. W nawiasach kwadratowych możemy dodać identyfikator i jego wartość.
Format to find CSS selectors
$$('tag[attribute="attribute value"]')
Jak pokazano, zwracana jest tablica zawierająca tylko jeden element. Możemy być pewni, że mamy teraz odpowiednie pole wyszukiwania, w którym możemy kliknąć i rozpocząć wpisywanie wyszukiwanych haseł.
Zawartość cudzysłowów w konsoli jest prawidłowym selektorem CSS i możemy go użyć w naszym skrypcie, aby znaleźć element sieciowy.
To prowadzi do następnej wskazówki.

Wskazówka 3: Wydajne skrobanie danych Jednoliniowe: ActionChains i Keys
Możemy teraz wywołać metodę find_element_by_css_selector w sterowniku obiektu webdriver.
Chcemy, aby nasz sterownik internetowy przeniósł się do tego elementu internetowego, kliknij go, wpisz wyszukiwane hasło „Globalne aktualizacje dotyczące wirusa koronowego” i naciśnij klawisz Enter.
Można to łatwo osiągnąć za pomocą klas ActionChains i Keys z Selenium. Po prostu przekazujemy sterownik do ActionChains i łańcuch metod, używając metod move_to_element, click, send_keys do wprowadzania danych wejściowych i key_downz Keys.ENTER przekazywanych w celu imitowania Enter. Aby uruchomić to polecenie, dodaj metodę perform na końcu łańcucha ActionChain.
Uruchomienie ActionChain prowadzi nas tutaj:

Wskazówka 4: Przechwytywanie danych
Wyświetlony element sieciowy zwraca obraz, nagłówek, podnagłówek i pewne dodatkowe informacje, takie jak data publikacji.
Jak uchwycić tylko nagłówek każdego artykułu?
Jeśli wpiszemy w konsoli pokazany poniżej element sieciowy, zwróci listę 10 elementów sieciowych. Z każdego z tych artykułów chcemy wyodrębnić tylko nagłówek.
Aby to zrobić, możemy po prostu iterować po 10 historiach. Aby to zrobić, wywołujemy find_elements_by_css_selectorz przekazanym elementem sieciowym. Ta metoda zwraca obiekt przypominający listę, po którym możemy iterować.
Możemy przypisać to do zmiennej o nazwie top_titles i iterować po nich za pomocą pętli for. W pętli for możemy znaleźć element powiązany z każdym nagłówkiem, korzystając z porady nr 2 i wyodrębnić tekst, wywołując .text w elemencie internetowym.
Oprócz drukowania na konsoli terminala możemy także zapisywać do pliku .txt, dzięki czemu mamy stałą kopię nagłówków za każdym razem, gdy uruchamiamy skrypt.
Wskazówka 5: bezgłowy webdriver
Kiedy uruchomimy skrypt w celu wyodrębnienia nagłówków, pojawi się okno przeglądarki i będzie ono działać, jak pokazano na poniższym filmie.
Choć oglądanie tego może być interesujące, w większości przypadków może nie być pożądane.
Aby usunąć przeglądarkę, zaimportuj klasę Options z modułu Selenium, utwórz instancję tej klasy i wywołaj metodę add_argumentmethod w tej instancji z przekazanym argumentem string „ — headless”. Na koniec w webdriverze pod parametrem opcji dodaj zmienną wskazującą przeglądarkę bezgłową.
Dodatkowa wskazówka: Dodaj oczekiwanie na znalezienie elementów w przypadku wolnego połączenia
Webdriver czekaj, By i oczekiwane_warunki
Aby mieć pewność, że webscraping przebiegnie pomyślnie, możemy wprowadzić do naszego skryptu funkcję Wait. Ta funkcja może być szczególnie przydatna w przypadkach, gdy strony internetowe ładują się powoli. Aby to zrobić, importujemy trzy pokazane klasy.
Zaletą wprowadzenia Wait jest to, że kiedy jest skonstruowany, można go prawie zapisać jako zdanie. Ponadto mogą wyszukiwać element sieciowy tak długo, jak tego chcemy. Jeśli element sieciowy zostanie znaleziony wcześniej, skrypt po prostu wykona się wcześniej.
Tutaj przekazujemy klasę WebDriverWait, nasz obiekt sterownika, każemy mu czekać maksymalnie 10 sekund, aż element zostanie zlokalizowany. W metodzie until przekazujemy klasęExpectedConditons z aliasem EC i wywołujemy na niej metodę obecności elementu zlokalizowanego. Następnie przekazujemy tej metodzie krotkę lokalizującą, szczegółowo opisując, jakiego elementu szukamy (By.CSS_SELECTOR) i element sieciowy.
Oczekiwanie sprawi, że Twoje skrypty będą bardziej niezawodne i mniej podatne na wyjątki związane z przekroczeniem limitu czasu.
Skrypt dla tych przykładów jest w całości pokazany tutaj.
Przekształcanie skryptu automatyzacji w klasę
Zajęcia z nagłówków poświęconych koronawirusowi
Kiedy mamy pewność, że automatyzacja sieci działa zgodnie z oczekiwaniami, możemy teraz przekształcić kod w klasę. Aby wszystko było jasne dla potencjalnych użytkowników tej klasy, zdecydowałem się nazwać tę klasę CoronaVirusHeadlines.
W konstruktorze init ustawiam atrybut sterownika w obiekcie, który wskazuje na sterownik internetowy Chrome.
Kod jest dokładnie taki sam, jak kod proceduralny pokazany w poprzednich sekcjach (z wyjątkiem tego, że usunąłem opcję bezgłową). Jedynym wyjątkiem jest to, że sterownik został ustawiony jako atrybut w obiekcie. Sterownik zostaje zainicjowany w metodzie init i jest używany w metodzie get_headlines do pobrania nagłówków.
Aby uzyskać nagłówki, po prostu tworzę instancję tej klasy o nazwie virus_data. Następnie wywołuję metodę get_headlines w tej klasie, aby pobrać nagłówki z pliku .txt.
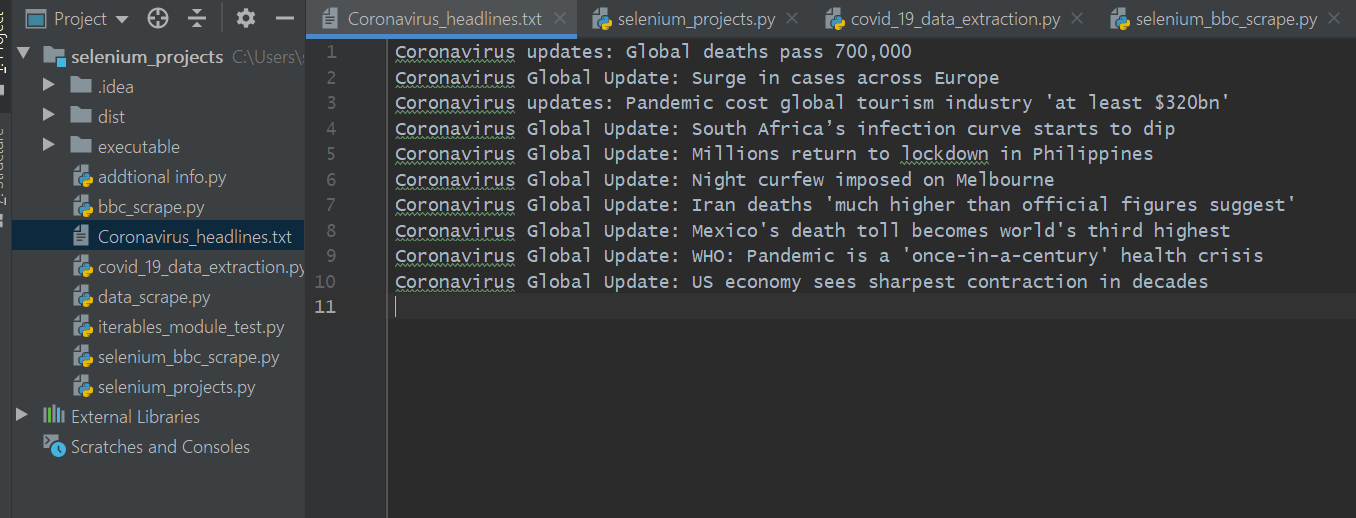
W moim katalogu lokalnym mogę teraz sprawdzić plik o nazwie „Coronavirus_headlines.txt”.
Jak pokazano poniżej, nagłówki zostały skopiowane do pliku .txt. Pamiętaj, że jeśli samodzielnie uruchomisz kod, nagłówki będą oczywiście inne, ponieważ pandemia wirusa koronaawirusa stale ewoluuje, a nowe artykuły są publikowane codziennie w BBC.
Podsumowanie i rozszerzenia
Oto niektóre z moich najlepszych wskazówek dotyczących skrobania przy użyciu selenu. Niektóre wskazówki, w tym wskazówki dotyczące łańcucha akcji i oczekiwania, mogą być bardzo czytelne i łatwo zrozumiałe dla innych, którzy mogą również przeczytać Twój kod.
Skrypt można łatwo rozbudować. Możesz także przejść na drugą stronę, aby pobrać kolejnych 10 nagłówków. A może chcesz, aby nagłówki zostały przesłane e-mailem lub przekonwertowane na plik wykonywalny, aby można było je udostępnić Tobie i Twoim zainteresowanym współpracownikom/przyjaciołom, którzy niekoniecznie używają Pythona. Można to osiągnąć za pomocą odpowiednio smtplib lub PyInstaller modules.
Dziękuje za przeczytanie.