Jest to podejście do integracji modeli ML z Dockerem i Jenkinsem.
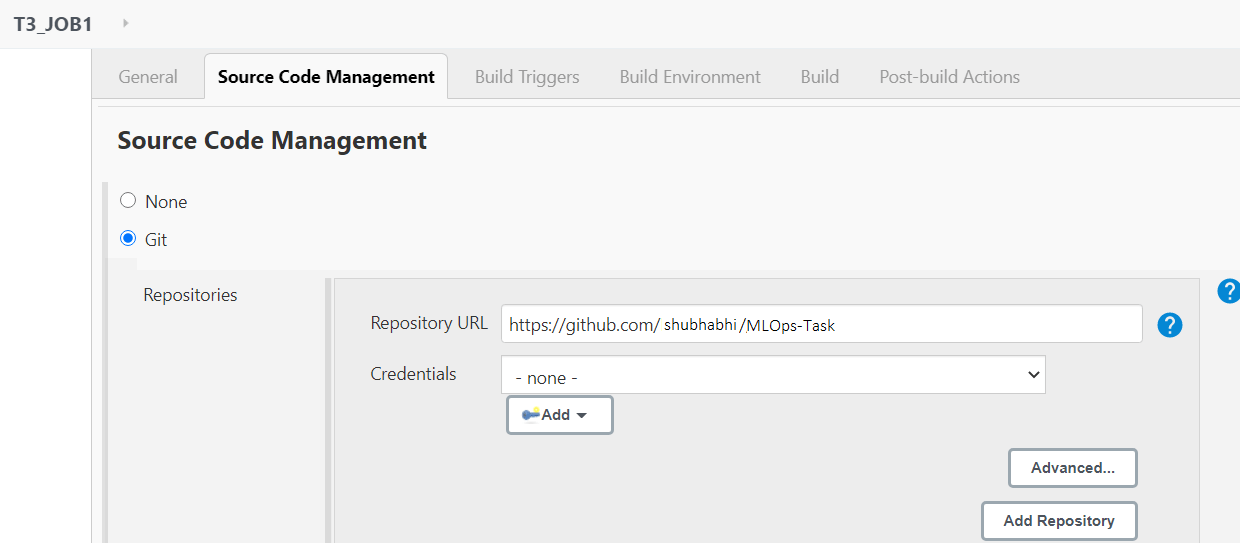
Repozytorium GitHub: https://github.com/shubhabhi/MLOps-Task

Po pierwsze, stworzyłem dwa obrazy Dockera przy użyciu pliku Docker dla modelu CNN, który będziemy trenować, a inne dla ogólnych problemów z ML.


ZADANIE 1: Gdy tylko programista wypchnie kod na GitHub, powinien on zostać automatycznie pobrany w obszarze roboczym Jenkins.

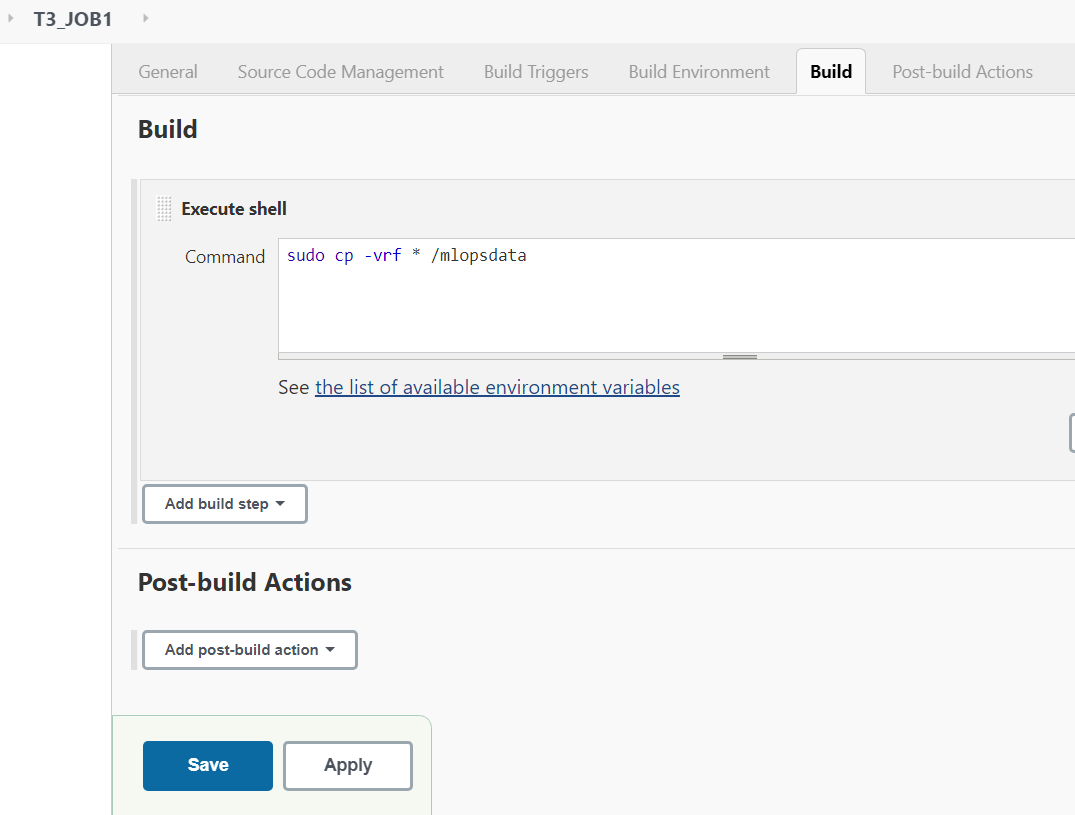
Zadanie 2: Patrząc na kod lub plik programu, Jenkins powinien automatycznie uruchomić odpowiedni zainstalowany interpreter oprogramowania do uczenia maszynowego i zainstalować kontener obrazu, aby wdrożyć kod i rozpocząć szkolenie.
W przypadku, gdy kod korzysta z CNN, Jenkins powinien uruchomić kontener, w którym zainstalowano już całe oprogramowanie wymagane do przetwarzania CNN.

ZADANIE 3: trenowanie modelu i przewidywanie jego dokładności.

ZADANIE 4: jeśli dokładność wytrenowanego modelu jest mniejsza niż nasz określony zakres, tj. dokładność›=80%). Konieczne jest przeszkolenie modelu ze zmianą wartości hiperparametrów.

Początkowe wartości Hyper-parameters:
no_of_filters=32, kernel_size=3, pool_size=2, i=1
Jeśli dokładność modelu nie jest zgodna z naszymi wymaganiami, musimy zmienić wartości, aby uzyskać lepszą dokładność.
Ale jeśli dokładność zostanie osiągnięta (tutaj 90%), programista otrzyma powiadomienie o dokładności modelu za pośrednictwem poczty elektronicznej.
ZADANIE 5: Utwórz jedno dodatkowe do monitorowania, np. jeśli kontener, w którym działa aplikacja, nie powiedzie się z dowolnego z powodów, to zadanie powinno automatycznie uruchomić kontener ponownie od miejsca, w którym opuścił ostatni wytrenowany model.
Powyższe zadanie zostało zrealizowane pod kierunkiem pana Vimala Dagi z LinuxWorld Informatics Pvt Ltd.