Kompleksowa analiza algorytmów detekcji obiektów

Przegląd
Ludzki mechanizm wizjonerski jest fascynujący. Sensory wizualne odbierają obraz i przetwarzają go na sygnały elektryczne, które przekazują do systemów neuronowych. Następnie mózg przetwarza sygnały, ostatecznie umożliwiając ludziom widzenie i zrozumienie kontekstu obrazu, w tym tego, które obiekty się na nim znajdują oraz gdzie i ile ich jest. Wszystkie te złożone procesy zachodzą natychmiast. Jeśli ktoś otrzyma długopis i zostanie poproszony o narysowanie ramki wokół wszystkich widocznych obiektów, można to łatwo zrobić.
Jednak wątpliwe jest, czy maszyna może wykonać ten proces tak skutecznie, jak człowiek. Konwolucyjne sieci neuronowe (ConvNets lub CNN) dobrze radzą sobie z wyodrębnianiem cech z danego obrazu i ostatecznie klasyfikują go jako kota lub psa. Proces ten nazywany jest klasyfikacją obrazu. Jest to łatwe zadanie, jeśli obiekty są wyśrodkowane, a na obrazie znajduje się tylko kilka obiektów. Jeśli liczba obiektów zostanie zwiększona, a obiekty należą do różnych klas, należy je rozróżnić i zlokalizować w obrazie. Nazywa się to wykrywaniem i lokalizacją obiektów. Zhao zakłada, że wykrywanie obiektów to proces budowania pełnego zrozumienia, w tym klasyfikacji i szacowania koncepcji oraz lokalizacji obiektów na każdym obrazie. (Zhao i in., 2019). Wykrywanie obiektów obejmuje również zadania podrzędne, takie jak wykrywanie twarzy, wykrywanie pieszych i wykrywanie kluczowych punktów. Podzadania te zasilają wiele aplikacji, w tym analizę ludzkich zachowań, rozpoznawanie twarzy i jazdę autonomiczną (Zhao i in., 2019).
W tym artykule skupiam się na algorytmach wykrywania obiektów, które są algorytmami z rodziny R-CNN; R-CNN, szybki R-CNN, szybszy R-CNN, maska R-CNN, Sdetektor Multibox Single Shot (SSD), RetinaNet i YOLO algorytmy rodzinne; YOLO, YOLO-9000, YOLOv3, YOLOv4 i YOLOv5.
Według Bochkovskiy i in. detektory obiektów składają się z 2 głównych części: szkieletu trenowanego w ImageNet i głowy używanej do predykcji obwiedni. Przede wszystkim VGG, ResNet, ResNeXt i Darknet są używane na platformach GPU, podczas gdy SqueezeNet, MobileNet lub ShuffleNet są używane na platformach CPU jako architektura „szkieletowa”. Większość detektorów obiektów wstawia warstwy połączeń między szkieletem a głowicą, aby zbierać mapy obiektów z różnych etapów. Nazywa się to „szyją”. Można stosować różne szyjki, takie jak sieci Feature Pyramid Networks, PANet lub Bi-FPN. W zależności od detektora obiektu można zastosować różne „głowice”, m.in. YOLO, SSD czy RetinaNet jako detektory jednostopniowe lub rodzinę R-CNN jako detektory dwustopniowe (Bochkovskiy i in., 2020).
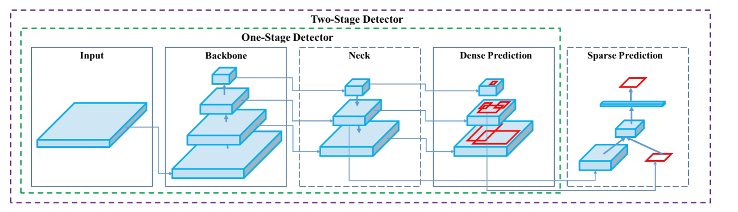
R-CNN — regionalne konwolucyjne sieci neuronowe
R-CNN i szybki R-CNN
W pierwszej wersji regionalne konwolucyjne sieci neuronowe (R-CNN) składają się z trzech etapów. Pierwszym etapem jest generowanie propozycji regionu, które definiuje zestaw potencjalnych wykryć. Drugim etapem jest ekstrakcja cech dla każdego regionu, natomiast ostatnim etapem jest klasyfikacja (Girshick i in., 2013). Girshick i in. użyj algorytmu wyszukiwania selektywnego do generowania propozycji regionów i wykorzystaj architekturę AlexNet CNN jako ekstraktor funkcji. Na ostatnim etapie wyodrębnione funkcje są wprowadzane do liniowych maszyn wektorów nośnych (SVM), które są optymalizowane pod względem klasy, aby sklasyfikować obecność obiektów w propozycji regionu kandydującego. Oprócz przewidywania klasy propozycji regionu algorytm przewiduje również cztery wartości, które są wartościami przesunięcia w celu zwiększenia precyzji ramki ograniczającej. Algorytmom R-CNN towarzyszy kilka wad. Po pierwsze, ich szkolenie jest powolne, a klasyfikacja każdej propozycji regionu (~2000) na obraz jest kosztowna. Po drugie, R-CNN nie można używać w scenariuszach czasu rzeczywistego, ponieważ testowanie obrazu zajmuje około 47 sekund. Po trzecie, naprawiono algorytm wyszukiwania selektywnego R-CNN. Zatem na tym etapie nie dochodzi do uczenia się, co może prowadzić do przedstawienia złej propozycji kandydata.
W 2015 r. Girshick zaproponował ulepszoną wersję R-CNN, znaną również jako Fast R-CNN (Girshick, 2015).To podejście jest podobny do oryginału, ale zamiast dostarczać propozycje regionów do warstwy splotowej, oryginalny obraz jest używany do generowania mapy cech splotowych. Propozycje regionów są identyfikowane na mapie obiektów, a następnie przetwarzane przez warstwę zbiorczą RoI (region zainteresowania) w celu nadania im stałego rozmiaru; następnie są wprowadzane do całkowicie połączonej warstwy. Istnieją dwie bliźniacze warstwy wyjściowe. Pierwsza warstwa generuje dyskretny rozkład prawdopodobieństwa na ROI w kategoriach. Druga warstwa generuje przesunięcia regresji obwiedni. Osiąga się to poprzez tak zwaną stratę wielozadaniową.

W rezultacie na podstawie wektora cech RoI widocznego na rysunku 2 przewidywane są wartości klasy i przesunięcia dla każdego proponowanego obszaru. Ważnym elementem Fast R-CNN jest RoIPooling, który umożliwia ponowne wykorzystanie mapy obiektów z poprzedniej sieci splotowej; technika ta znacznie skraca czas szkolenia i testowania oraz umożliwia kompleksowe przeszkolenie systemu wykrywania obiektów (Grel, 2017).
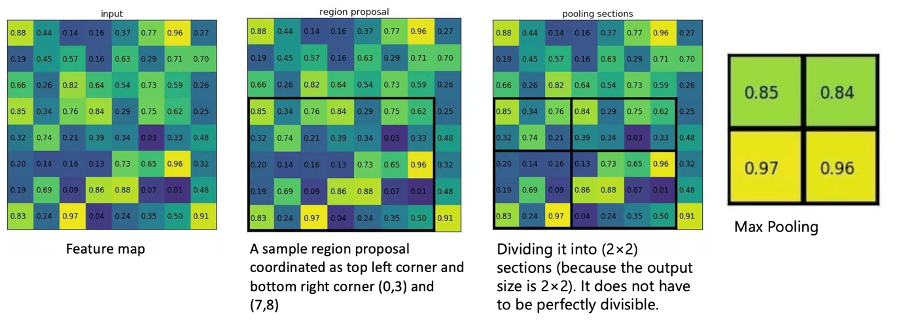
Problem z Fast R-CNN polega na tym, że nadal wykorzystuje algorytm wyszukiwania selektywnego do generowania propozycji regionów. Ponieważ proces ten jest kosztowny i czasochłonny, generowanie propozycji regionu stało się wąskim gardłem dla algorytmu.
Szybszy R-CNN
W 2015 roku Ren i in. zaproponował Faster R-CNN, który eliminuje algorytm selektywnego wyszukiwania propozycji regionów i wykorzystuje sieci propozycji regionów (RPN) do poznania propozycji regionów (Ren i in., 2015).
W swojej oryginalnej pracy Ren i in. użyj modelu Zeilera i Fergusa – który ma 5 współdzielonych warstw splotowych, a także VGG16, który ma 13 współdzielonych warstw splotowych – jako ekstraktorów cech, zwanych także szkieletami. W implementacji PyTorch Faster R-CNN wykorzystuje ResNet z FPN lub MobileNetV3 z FPN jako ekstraktory funkcji; architekturę przedstawiono na rysunku 4.

Sieć propozycji regionów (RPN) to mała sieć, która przesuwa się po wynikowej mapie obiektów splotowych ostatniej współdzielonej warstwy splotowej. Generuje prostokątne propozycje obiektów z wynikami obiektywności, biorąc okno przestrzenne 3 x 3 wejściowych map cech splotowych generowanych przez ekstraktor cech. Dla każdej lokalizacji okna przesuwnego RPN generuje k różnych możliwych propozycji. Tych k różnych propozycji prowadzi do 2 tys. punktów obiektywności i 4 tys. współrzędnych. Ponadto tych k różnych propozycji odnosi się do k różnych ramek odniesienia, zwanych kotwicami. Kotwy te są dostępne w różnych rozmiarach i kształtach (Ren i in., 2015). W swojej pracy Ren i in. określ, że użyli 3 skal i 3 współczynników proporcji, co daje w sumie 9 kotwic. RPN są szkolone poprzez przypisanie etykiet klas binarnych do każdej kotwicy w celu sprawdzenia, czy istnieje jakiś obiekt, czy nie. Etykiety dodatnie dotyczą kotwic o najwyższym IoU i kotwic z nakładaniem się IoU większym niż 0,7 ze skrzynką prawdy uziemiającej. Etykiety ujemne są przypisane do kotwicy niedodatniej z IoU 0,3 dla wszystkich pól prawdy naziemnej. Zgodnie z tymi definicjami funkcja straty dla RPN jest zdefiniowana w sposób pokazany w równaniu 1:

gdzie i to indeks kotwicy w minipartii, a pi to prawdopodobieństwo, że w tej kotwicy znajduje się obiekt. Etykieta uziemienia p*i wynosi 1, jeśli kotwica jest dodatnia i wynosi 0, jeśli kotwica jest ujemna; ti jest wektorem reprezentującym 4 sparametryzowane współrzędne ramki ograniczającej; oraz t*i jest podstawowym polem prawdy powiązanym z dodatnią kotwicą. Strata klasyfikacji jest binarną entropią krzyżową, a strata regresji jest gładka L1. Strata regresyjna jest aktywowana tylko dla kotwic dodatnich, gdzie p*i nie wynosi zero. Dla 4 współrzędnych ramki granicznej stosowane są następujące parametry, jak zdefiniowano w równaniu 2:
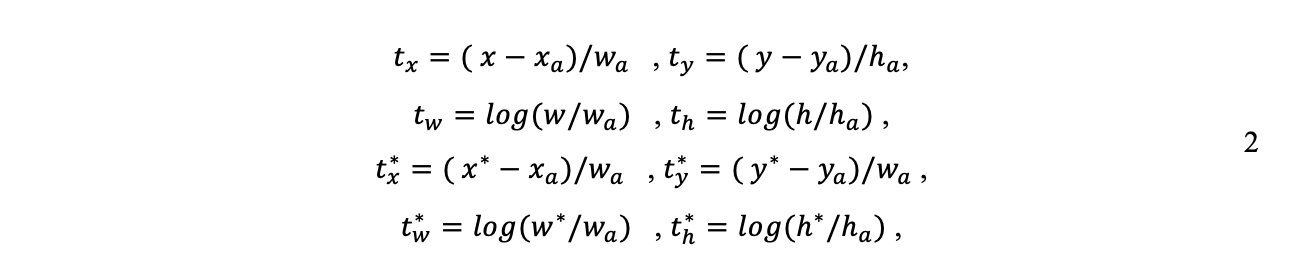
gdzie x i y oznaczają współrzędne środka pudełka, a h i w oznaczają wysokość i szerokość; x, xa i x* oznaczają przewidywaną obwiednię, kotwicę i podstawę prawdy.
Po wygenerowaniu przez RPN propozycji regionów Faster R-CNN korzysta również z łączenia ROI — podobnie jak w przypadku Fast R-CNN — w celu łączenia propozycji regionalnych i map obiektów na potrzeby zadań wykrywania.
Maska R-CNN
On i in. opracował Mask R-CNN w 2017 r., rozszerzając Faster R-CNN i dodając gałąź do przewidywania maski obiektów równolegle z przewidywaniem obwiedni (He i in., 2017). Maska R-CNN działa z szybkością 5 klatek na sekundę. Głównym celem jest segmentacja instancji. Nowa gałąź modelu Mask R-CNN przewiduje maski segmentacji piksel po pikselu w każdym obszarze zainteresowania (RoI). RoIAlign jest używany zamiast RoIPool, ponieważ nie wymaga kwantyzacji oraz ponieważ naprawia niewspółosiowość i zachowuje lokalizacje przestrzenne.
W implementacji PyTorch Mask R-CNN wykorzystuje ResNet z FPN lub MobileNetV3 z FPN jako ekstraktory funkcji; architekturę przedstawiono na rysunku 5.

Jak pokazano w Tabeli 1, Mask-RCNN przewyższa także Szybszy RCNN w zadaniach wykrywania obiektów w mAP. On i in. sugerują, że poprawa ta wynika z RoIAlign (+1,1 AP), szkolenia wielozadaniowego (+0,9 AP) i ResNeXt101 (+1,6 AP) (He i in., 2017).

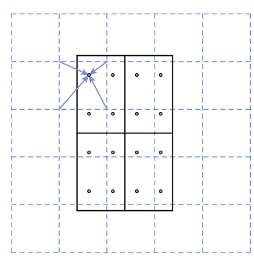
On i in. zaproponować RoIAlign do rozwiązania problemu kwantyzacji spowodowanego przez RoIPooling (RoIPool został wprowadzony w sekcji 1.1.1.1. RoIAlign po prostu unika jakiejkolwiek kwantyzacji granic RoI; wykorzystuje interpolację dwuliniową do obliczenia dokładnych wartości cech w każdym przedziale RoI i agreguje wyniki. Jak pokazano na rysunku 6, przerywana siatka to mapa obiektów, linie ciągłe oznaczają obszary zainteresowania (ROI), a cztery kropki to punkty próbkowania. RoI oblicza dwuliniową interpolację punktu z pobliskiej siatki obiektu map Dlatego podczas tych operacji nie następuje kwantyzacja.
Maska R-CNN wykorzystuje tę samą funkcję utraty, co Faster R-CNN. Dodatkowo ma utratę maski zdefiniowaną w równaniu 3:

Lcls i Lbox są zdefiniowane jak w Faster R-CNN. Gałąź maski ma maskę binarną K dla każdego obszaru ROI, a każda maska ma rozdzielczość m x m, która jest wynikiem wyjściowego wymiaru Km2 dla każdego obszaru ROI. Dlatego istnieje możliwość tworzenia masek dla każdej klasy przez sieć, co zapobiega konkurencji pomiędzy klasami. On i in. zastosuj sigmoidę na piksel i wykorzystaj Lmask jako binarną stratę entropii krzyżowej (He i in., 2017).
Detektor jednostrzałowy MultiBox (SSD)
Detektory obiektów regionalne, takie jak rodzina R-CNN, wymagają co najmniej 2-stopniowych detektorów obiektów, gdzie pierwszy etap polega na generowaniu propozycji, a drugi etap polega na wykrywaniu obiektu dla każdej propozycji. Detektor Single Shot MultiBox, znany również jako SSD, jest detektorem jednostopniowym, co oznacza, że zarówno lokalizacja, jak i klasyfikacja obiektu są wykonywane w jednym przebiegu sieciowym, w wyniku którego powstaje zbiór ramek ograniczających o stałym rozmiarze i wyniki dla obecność instancji klasy obiektów, po której następuje tłumienie inne niż maksymalne w celu usunięcia tych samych wykryć dla obiektu (Liu i in., 2016). Dysk SSD działa z szybkością 59 klatek na sekundę (FPS), a mAP wynosi 74,3% w testowym zestawie danych VOC2007. Dla porównania, Faster R-CNN działało z szybkością 7 klatek na sekundę i mAP na poziomie 73,2%, podczas gdy YOLO działało z prędkością 45 klatek na sekundę z mAP na poziomie 63,4% (Liu i in., 2016).
Według Liu i in. największa poprawa wynika z wyeliminowania propozycji ramek ograniczających i ponownego próbkowania funkcji. Wkład dysku SSD jest potrójny. Po pierwsze, jest szybszy i znacznie dokładniejszy niż najnowocześniejszy detektor jednostrzałowy (YOLO). Po drugie, przewiduje wyniki kategorii i przesunięcia obwiedni dla stałego zestawu domyślnych bboxów, używając małych filtrów splotowych stosowanych do map obiektów. Po trzecie, generuje prognozy dla różnych skal na podstawie map obiektów w różnych skalach i oddziela prognozy według współczynnika kształtu.
Architektura dysku SSD opiera się na VGG-16, choć eliminuje w pełni połączone warstwy. Dodano dodatkowe warstwy splotowe, aby wyodrębnić cechy z różnych skal i stopniowo zmniejszać rozmiar danych wejściowych w każdej warstwie. Określa się to jako wieloskalowe mapy obiektów do wykrywania. SSD oblicza wyniki lokalizacji i klas przy użyciu małych filtrów splotowych, które mają wymiary 3x3 i dają wynik dla kategorii lub przesunięcie kształtu względem domyślnych współrzędnych pola dla każdej komórki (Liu i in., 2016). Filtry te są znane jako predyktory splotowe do wykrywania. Dysk SSD używa domyślnych ramek ograniczających, takich jak kotwice w szybszym R-CNN.

Liu i in. opisz także technikę zwaną twardym eksploracją negatywną, która wykorzystuje podczas szkolenia pewne negatywne i pozytywne przykłady. Ponieważ większość ramek ograniczających ma niski współczynnik przecięcia przez sumę (IoU) i są one interpretowane jako przykłady negatywne, Liu i in. użyj stosunku 3:1 pomiędzy przykładami negatywnymi i pozytywnymi, aby zrównoważyć przykłady szkoleniowe. Pomaga to również sieci uczyć się nieprawidłowych wykryć (Liu i in., 2016).
Stosowane są również techniki powiększania danych, takie jak odwracanie i łatanie, podobnie jak w wielu innych zastosowaniach sieci neuronowych. Liu i in. użyj odwracania poziomego z prawdopodobieństwem 0,5, aby upewnić się, że potencjalne obiekty pojawią się zarówno po lewej, jak i po prawej stronie z podobnym prawdopodobieństwem.
Funkcja straty dla modelu SSD jest ważoną sumą utraty lokalizacji (loc) i utraty zaufania (conf), jak opisano w równaniu 4:

gdzie x jest wskaźnikiem dopasowania domyślnego pola do podstawowej prawdy; l to przewidywane pudełko, a N to liczba domyślnych pól dopasowanych do podstawowej prawdy. Utrata ufności to wynik SoftMax dla wielu klas ufności ©, podczas gdy utrata lokalizacji to gładka utrata L1 między przewidywaną skrzynką a prawdą podstawową (Liu i in., 2016).
RetinaNet
Focal Loss for Dense Object Detection, znana również jako RetinaNet, została zaproponowana w 2018 roku przez Lin i in. Według Lin i in. przyczyną niższej dokładności detektorów jednostopniowych jest skrajna nierównowaga klas pierwszego planu i tła. W rodzinie R-CNN i innych detektorach dwustopniowych rozwiązano problem braku równowagi klas. Stan propozycji, taki jak propozycje wyszukiwania selektywnego lub RPN, jest odpowiedzialny za odfiltrowanie większości próbek tła poprzez zawężenie liczby potencjalnych lokalizacji obiektów do małej liczby (1–2 tys.), podczas gdy detektory jednostopniowe muszą przetworzyć ~ 100 tys. Na drugim etapie heurystyka próbkowania, taka jak stały stosunek pierwszego planu do tła (1:3) lub eksploracja twardych przykładów online, pomaga zrównoważyć pierwszy plan i tło. Chociaż w detektorach jednostopniowych stosuje się ładowanie początkowe lub eksplorację twardych przykładów, Liu i in. twierdzą, że te techniki nie są wystarczające, aby sobie z tym poradzić. Dlatego Lin i in. zaproponować przekształconą stratę entropii krzyżowej w taki sposób, aby zmniejszyć wagę straty, aby uzyskać dobrze sklasyfikowaną stratę (Lin i in., 2018).

RetinaNet wykorzystuje sieć ResNet + Feature Pyramid Network (FPN) jako szkielet, który jest odpowiedzialny za wyodrębnianie bogatych i wieloskalowych map obiektów z całego obrazu. RetinaNet wykorzystuje wówczas jedną podsieć do przewidywania klas, a drugą do przewidywania obwiedni. Jak widać w Tabeli 2, RetinaNet jest pierwszym jednostopniowym detektorem, który przewyższa detektory dwustopniowe nie tylko pod względem czasu wnioskowania (FPS), ale także pod względem dokładności w danym momencie.

Zaproponowano utratę ogniskową, aby rozwiązać problem braku równowagi pomiędzy klasami pierwszego planu i tła. Jak stwierdził Lin i in., współczynnik ważenia jest powszechną metodą modyfikowania entropii krzyżowej (Lin i in., 2018). Dlatego dodają współczynnik modulujący (1-pt)y, gdzie jest parametrem ogniskowania:


Patrzysz tylko raz (YOLO) Rodzina
YOLO, V1
Algorytm YOLO został po raz pierwszy zaproponowany w 2015 roku przez Redmona i in. Przyjmuje inne podejście niż inne ówczesne algorytmy wykrywania obiektów. Określa wykrywanie obiektów jako problem regresji, podczas gdy inne wykorzystują podejście klasyfikacyjne. Redmon i in. argumentują, że ponieważ pojedyncza sieć przewiduje w jednym przebiegu prawdopodobieństwa zarówno ramki ograniczającej, jak i klas, można ją kompleksowo zoptymalizować (Redmon i in., 2015).
YOLO (v1) może przetwarzać obrazy z szybkością 45 klatek na sekundę, a mniejsza wersja YOLO może przetwarzać obrazy z szybkością 155 klatek na sekundę, jednocześnie osiągając dwukrotnie większą wartość mAP w porównaniu z innymi detektorami obiektów działającymi w czasie rzeczywistym (Redmon i in., 2015).
Ideą algorytmu YOLO jest pobranie obrazu jako danych wejściowych i podzielenie go na komórki, które można sobie wyobrazić jako nakładające się na siatkę (S x S); jeśli środek obiektu wpada do komórki siatki, ta komórka siatki jest odpowiedzialna za przewidywania.

Każda komórka siatki generuje B ramek ograniczających i poziom ufności dla tych ramek, odzwierciedlający pewność modelu co do ramki pod względem tego, czy zawiera ona obiekt, czy nie. Redmon i in. sformułować pewność jak we wzorze 6 (Redmon i in., 2016):
Zgodnie z tym wzorem, jeśli w komórce nie ma żadnego obiektu, wskaźnik pewności powinien wynosić zero. Jeśli w komórce znajduje się obiekt, prawdopodobieństwo wynosi 1, a pewność jest równa IoU między przewidywaną obwiednią a podstawową prawdą.
Jak wspomniano powyżej, każda komórka przewiduje ramkę ograniczającą B, a dla każdej ramki ograniczającej istnieje 5 wartości. Są to x, y, w i h ramki ograniczającej, a także współczynnik pewności. (x, y) to środek obwiedni, podczas gdy w i h to szerokość i wysokość obwiedni w stosunku do całego obrazu. Oprócz ramki ograniczającej każda komórka siatki przewiduje również prawdopodobieństwa klas, jeśli istnieje obiekt — innymi słowy, prawdopodobieństwa klas warunkowych C Pr(Classi | Object) — więc wzór jest renderowany w następujący sposób (Redmon i in. , 2015):
Całkowite przewidywania dla obrazu są równe S x S x (B * 5 + C). W swojej pracy Redmon i in. stwierdzić, że użyli S=7 i B=2 w zbiorze danych PASCAL VOC, który ma 20 klas; zatem ostateczną prognozą jest tensor 7 x 7 x 30. Na ostatnim etapie YOLO stosuje tłumienie inne niż maksymalne, aby wyeliminować duplikaty (Redmon i in., 2016).

YOLO v1 ma 24 warstwy splotowe i 2 w pełni połączone warstwy, inspirowane GoogLeNet. Jednak zamiast modułów początkowych YOLO wykorzystuje warstwę redukcyjną 1x1, po której następują warstwy splotowe 3x3. Warstwy splotowe są wstępnie trenowane w ImageNet w połowie rozdzielczości (224 x 224), a następnie w celu wykrycia podwojonej rozdzielczości.
YOLO v1 ma znane w swoim czasie ograniczenia. Ponieważ każda komórka siatki przewiduje tylko dwie ramki ograniczające i jedną klasę, trudno jest wykryć bliskie obiekty. YOLO v1 ma również trudności z wykrywaniem małych obiektów. Funkcja straty stwarza ryzyko powielania błędów zarówno w przypadku dużych, jak i małych obiektów. Małe błędy na małych obiektach mają większy efekt.
YOLO wykorzystuje funkcję utraty wieloczęściowej, która jest sumą utraty lokalizacji, utraty pewności i utraty klasyfikacji. Utrata lokalizacji mierzy błędy w przewidywanych lokalizacjach i rozmiarach obwiedni;
kładzie większy nacisk na dokładność obwiedni. Co więcej, mierzy się utratę zaufania, jeśli w celli znajduje się obiekt; nazywa się to obiektywnością. Jeśli obiekt zostanie wykryty, utrata klasyfikacji przewiduje klasę obiektu w każdej komórce, obliczając błąd kwadratowy prawdopodobieństw warunkowych klasy dla każdej klasy.

W momencie zaproponowania YOLO przewyższał on detektory dwustopniowe zarówno pod względem mAP, jak i FPS, jak widać w tabeli 3.

YOLO v2 (YOLO 9000)
Dysk SSD był silnym konkurentem, gdy go zaproponowano. YOLO charakteryzowało się większymi błędami lokalizacji, podczas gdy jego zapamiętywanie – które mierzy, jak dobrze lokalizuje wszystkie obiekty – było mniejsze. Zatem YOLO v2 ma na celu poprawę zapamiętywania i lokalizacji przy jednoczesnym zachowaniu dokładności klasyfikacji (Redmon i Farhadi, 2016).
Redmon i Farhadi używają wielu technik, aby ulepszyć YOLO v2, opisując w swoim artykule ścieżkę od YOLO do YOLO v2. Pierwszą z tych technik jest normalizacja wsadowa, która przynosi znaczną poprawę zbieżności i eliminuje inne metody normalizacyjne. Stosując normalizację wsadową, Redmon i Farhadi uzyskali 2% poprawę w mAP i usunęli odpadanie; normalizacja wsadowa poprawiła również regularyzację i zapobiegła nadmiernemu dopasowaniu. Druga technika polega na użyciu klasyfikatora o wyższej rozdzielczości. Wszystkie najnowocześniejsze detektory obiektów korzystają z klasyfikatorów przeszkolonych w ImageNet. W YOLO v1 jest to 224 x 224; ale w YOLO v2 sieć klasyfikacyjna jest szkolona w ImageNet z obrazami wejściowymi w rozdzielczości 448 x 448 przez 10 epok. Wyższa rozdzielczość zapewnia dodatkowy 4% wzrost mAP. Trzecią techniką jest splot z kotwicami, jak w Faster R-CNN: sieć przewiduje przesunięcia jedynie dla ręcznie podanych kotwic (priorów). Dlatego Redmon i Farhadi usuwają w pełni połączone warstwy i używają bloków kontrolnych do przewidywania ramek ograniczających. Jedna warstwa łącząca jest usuwana w celu zwiększenia rozdzielczości, a obraz jest zmniejszany do 416 x 416 zamiast 448 x 448. Motywacją do tego procesu zmniejszania jest użycie nieparzystej liczby lokalizacji w siatce, aby zagwarantować pojedynczą komórkę środkową. YOLO próbkuje obraz 32-krotnie; zatem 448 kończy się na 14, podczas gdy 416 kończy się na 13. Wreszcie Redmon i Farhadi twierdzą, że mogliby osiągnąć lepsze wyniki, zaczynając od lepszych bloków kontrolnych. Dlatego używają grupowania k-średnich w zbiorze danych, aby znaleźć pola zakotwiczenia.

Zamiast przewidywać przesunięcie na podstawie bloków kontrolnych, Redmon i Farhadi stosują bezpośrednie przewidywanie lokalizacji, które jest przesunięte w stosunku do siatki. Pomaga to rozwiązać problem niestabilności modelu podczas wczesnych iteracji. Dla każdej ramki ograniczającej sieć przewiduje 5 współrzędnych (tx, ty, tw, th i to). Jeśli komórka jest odsunięta o (cx, cy) od lewego górnego rogu i jeśli szerokość ramki kontrolnej (pw) i wysokość (ph), to przewidywania obwiedni i obiektywności są następujące:

Redmon i Farhadi również używają drobnoziarnistych funkcji, które są funkcjami z wcześniejszych warstw. Inne detektory obiektów wykorzystują różne skale, które dostarczają przewidywań. Dlatego Redmon i Farhadi również stosują podobne podejście, wykorzystując funkcje z wcześniejszych warstw w formacie 26x26; łączą funkcje z wysokiej i niskiej rozdzielczości, takie jak mapowania identyfikacyjne, jak w ResNet. Stosują także szkolenie wieloskalowe, co wiąże się ze zmianą wielkości danych wejściowych w trakcie szkolenia. Zgłaszają, że używają zestawu wielokrotności 32 ({320, 352,…, 608}) i że ten reżim zmusza sieć do nauczenia się skuteczniejszego przewidywania w różnych wymiarach wejściowych (Redmon i Farhadi, 2016).

Redmon i Farhadi używają również niestandardowego podstawowego ekstraktora funkcji innego niż VGG-16. Chociaż VGG-16 jest wydajny i dokładny, jest również złożony — ma 30,69 miliarda FLOPów na jedno przejście, podczas gdy niestandardowa sieć zaprojektowana dla YOLO v2 ma 8,52 miliarda FLOPów. Dokładność sieci niestandardowej jest nieco gorsza niż VGG-16: podczas gdy VGG-16 ma 90% dokładności w ImageNet, sieć niestandardowa ma dokładność 88% (Redmon i Farhadi, 2016). Ostateczny model nazywa się Darknet-19 i składa się z 19 warstw splotowych i 5 warstw z maksymalnym łączeniem.
Redmon i Farhadi stosują również klasyfikację hierarchiczną, która umożliwia łączenie zbiorów danych klasyfikacyjnych i zbiorów danych detekcji poprzez wykorzystanie etykiet obrazów. Klasyfikacja hierarchiczna i połączone zbiory danych umożliwiają wykrywanie obiektów w czasie rzeczywistym w ponad 9000 kategoriach obiektów.
YOLO v3
W 2018 roku Redmon i Farhadi zaproponowali kilka aktualizacji algorytmu YOLO. YOLO v3 ma nową architekturę sieciową z ekstraktorem funkcji o nazwie Darknet-53, która jest odmianą Darknet z 53 warstwami wyszkolonymi w ImageNet. W celu wykrywania zadań nakładane są na niego 53 dodatkowe warstwy. Posiada 106 w pełni splotowych warstw. Ze względu na tę ciężką architekturę nie jest szybszy niż YOLO-v2, chociaż jest dokładniejszy (Redmon i Farhadi, 2018). Redmon i Farhadi twierdzą, że Darknet-53 jest lepszy od RestNet-101 i 1,5x szybszy, z podobną wydajnością do ResNet-152, aczkolwiek 2x szybszy.

Dzięki nowej architekturze YOLO v3 z Darknet53 jest lepszy niż SSD i zbliżony do najnowocześniejszej sieci RetinaNet w AP50, choć 3x szybszy.
Ze względu na wydajność Redmon i Farhadi aktualizują przewidywanie klas używane w niezależnych klasyfikatorach logistycznych, zamiast używać SoftMax. Dzięki takiemu podejściu mogą zastosować klasyfikację wieloetykietową i rozwiązać problem nakładających się etykiet (na przykład „kobieta” i „osoba”). W swoim artykule proponują także prognozy w różnych skalach. YOLO v3 generuje prognozy obwiedni w 3 różnych skalach. Zatem tensor wynosi S x S x [ 3 * (4+1 + 80)] dla zbioru danych COCO dla każdej skali (Redmon i Farhadi, 2018). Jak widać na rysunku 14, predykcja wieloskalowa pomaga wykrywać obiekty w różnych skalach. Używają grupowania k-średnich w zbiorze danych COCO, aby znaleźć pola kotwiczące dla każdej skali, którymi jest 9 następujących bloków kontrolnych (3 dla każdej skali): (10 × 13), (16 × 30), (33 × 23) , (30×61), (62×45), (59×119), (116×90), (156×198) i (373×326) (Redmon i Farhadi, 2018).

Nawiasem mówiąc, po opracowaniu YOLO v3, w 2020 roku Redmon podjął decyzję o zaprzestaniu badań nad wizją komputerową ze względu na jej zastosowania wojskowe i związane z tym obawy dotyczące prywatności.

YOLO v4
Bochkovskiy i in. kontynuował badania nad algorytmem YOLO i zaproponował YOLO v4 w 2020 roku. Ich wkład w YOLO v4 polega przede wszystkim na opracowaniu wydajnego i wydajnego modelu wykrywania obiektów, weryfikacji metod worków gratisowych i worków specjalnych oraz modyfikowaniu stanu -art metody do działania na jednym procesorze graficznym, aby każdy miał do nich dostęp. Osiągnęli znakomite wyniki z 43,5% AP (65,7% AP50) dla zbioru danych MS COCO przy prędkości czasu rzeczywistego 65 FPS (Bochkovskiy i in., 2020), łącząc niektóre z następujących technik: Ważone połączenia resztkowe ( WRC), częściowe połączenia między etapami (CSP), normalizacja między mini-wsadami (CmBN), szkolenie samokontradyktoryjne (SAT), aktywacja Mish, powiększanie danych mozaikowych i regularyzacja bloków upuszczania.
Ich splotowe sieci neuronowe trenowano w trybie offline, a badacze opracowali modele i wykorzystali techniki pomagające poprawić dokładność modelu w czasie wnioskowania bez wpływu na koszt wnioskowania. Dlatego takie podejście nazywa się torbą gratisów.
Powiększanie danych pomaga trenować model pod kątem zmienności obrazów wejściowych w celu zwiększenia niezawodności. Podejście to opiera się głównie na zniekształceniach fotometrycznych (takich jak zmiana jasności, kontrastu, odcienia, nasycenia i szumu obrazu) i zniekształceniach geometrycznych (takich jak obrót, odwracanie, kadrowanie i losowe skalowanie); jest to jedna z technik z kategorii worków gratisów (Bochkovskiy i in., 2020). Oprócz powiększania pikseli niektórzy badacze proponują przetwarzanie wielu obrazów jednocześnie poprzez zastosowanie MixUp — który wykorzystuje dwa obrazy do mnożenia i nakładania na siebie w różnych proporcjach — lub CutMix, który pokrywa niektóre części obrazów innymi obrazami, oraz Mosaic, która łączy 4 różne obrazy szkoleniowe. Jak wspomniano wcześniej w odniesieniu do RetinaNet, niezrównoważone/stronnicze zbiory danych prowadzą do modeli o niskiej wydajności; w związku z tym mają niską dokładność. Z drugiej strony oznaczone dane mogą być błędne. Jeśli zbiór danych jest mały, opcją może być sprawdzenie ręczne; jednak w przypadku większych zbiorów danych wygładzanie etykiet to matematyczny sposób usprawnienia uczenia się na podstawie błędnie oznakowanych próbek w zbiorze danych (Szegedy i in., 2015). Chociaż błąd średniokwadratowy jest używany głównie jako funkcja straty w problemach regresyjnych, Bochkovskiy i in. stwierdzają również, że wątkowanie współrzędnych ramki granicznej jako zmiennych niezależnych powoduje utratę integralności obiektu (Bochkovskiy i in., 2020).
Bochkovskiy i in. zaproponuj także zestaw produktów specjalnych, który nieznacznie zwiększa koszty wnioskowania, ale znacznie poprawia dokładność wykrywania obiektów.
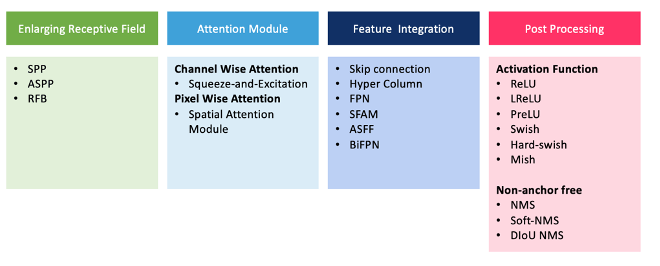
Powiększające się pola recepcyjne to SSP (Spatial Pyramid Pooling), zaproponowane przez He i in. wyeliminowanie ograniczeń wejściowych sieci o stałym rozmiarze poprzez generowanie reprezentacji obrazów o stałej długości (He i in., 2015), a także ASPP (Atrous Spatial Pyramid Pooling) — zaproponowanej przez Chena i in. (Chen i in., 2017), aby pomóc skutecznie powiększyć pole widzenia filtrów w celu uwzględnienia szerszego kontekstu bez znaczącego zwiększania liczby parametrów lub ilości obliczeń — oraz RFB (blok pola recepcyjnego) , co zaproponowali Liu i in. i został zainspirowany ludzkimi systemami wzrokowymi. RFB bierze pod uwagę związek między rozmiarem i mimośrodem pól recepcyjnych, aby zwiększyć zdolność rozróżniania i solidność cech (Liu i in., 2018).
Moduły uwagi — przede wszystkim kanałowy moduł uwagi i pikselowy moduł uwagi — są również wykorzystywane do wykrywania obiektów. Hu i in. zaproponowali Squeeze-and-Excitation, przedstawiciel uwagi kanałowej. umożliwienie modelom/sieciom budowania funkcji informacyjnych poprzez wprowadzanie informacji przestrzennych i kanałowych do lokalnych pól recepcyjnych w każdej warstwie (Hu i in., 2019). Jak stwierdził Bochkovskiy i in. z raportu wynika, że moduł SE jest kosztowny dla procesora graficznego (+10% kosztu), chociaż można go używać z procesorem/urządzeniami mobilnymi (+2% kosztu) (Bochkovskiy i in., 2020). SAM (moduł uwagi przestrzennej), który reprezentuje uwagę pikselową, został zaproponowany przez Woo i in. jako element konstrukcyjny modułu uwagi bloku splotowego (Woo i in., 2018). SAM generuje maskę, która uwydatnia ważne cechy definiujące obiekt i udoskonala mapy obiektów.
Integracja funkcji, takich jak pomijanie połączeń i FPN, pomaga zintegrować funkcje niskiego poziomu z funkcjami wysokiego poziomu. Funkcje aktywacji zapewniają nieliniowość, a celem wyboru aktywacji jest spowodowanie skutecznej propagacji wstecznej gradientu. Innym procesem przetwarzania końcowego jest NMS (Non-Max Suppression), który polega na eliminacji ramek ograniczających o niskich wynikach.
Zatem architektura YOLO v4 wygląda następująco: szkielet to CSPDarknet53, szyja to SPP i PAN, a głowa jest taka sama jak w YOLOv3. Bezpłatne podejścia do szkieletu to CutMix, Mosaic Data Augmentation, regularyzacja DropBlock i Label Smoothing. Do technik szkieletowych zalicza się aktywację Mish, międzystopniowe połączenia częściowe (CSP) i wielowejściowe ważone połączenia resztkowe (MiWRC). Techniki bezpłatnego zestawu detektorów obejmują utratę CIoU, CmBN, regularyzację DropBlock, powiększanie danych Mosaic, trening samokontradyktoryjny, eliminowanie czułości siatki, używanie wielu kotwic dla jednej prawdy podstawowej, optymalne hiperparametry harmonogramu wyżarzania cosinusowego i losowe kształty treningowe. Do technik specjalnych detektora należą aktywacja Mish, blok SPP, blok SAM, blok agregacji ścieżki PAN i DIoU-NMS (Bochkovskiy i in., 2020).
W dyskusji na Github.com Bochkovskiy określił udział mAP w technikach bag-of-freebies i bag-of-special, takich jak SPP (+3%), CSP+PAN (+2%), SAM (+0,3%) , CIoU+S (+1,5%), strojenie mozaiki i hiperparametrów (+2%), skalowane kotwice (+1%), łącznie około +10% (Bochkovskiy, 2020). Zatem 5% całkowitego ulepszenia pochodzi z architektury, a kolejne 5% z worka gratisów (Bochkovskiy, 2020).
YOLO v5
YOLO v4 stanowiło duży krok naprzód w stosunku do YOLO v3. Zaledwie kilka miesięcy później, 9 czerwca 2020 r., Glenn Jocher — wspomniany w artykule YOLO v4 dotyczącym powiększania danych Mosaic autorstwa Bochkovskiy'ego i in. i który wniósł znaczący wkład w architekturę YOLOv3 (ponad 2000 zatwierdzeń i przeniesienie mAP z 33 do 45.6.) — wydano YOLO v5 bez oficjalnego dokumentu. Po prostu udostępnił YOLO v5 na Github.com (Jocher, 2020).

YOLOv5 nie jest oparty na Darknecie, ale jest w całości zaimplementowany w PyTorch. Zgodnie z wynikami mAP pokazanymi dla YOLO v4 w zestawie danych MS COCO, wartości mAP YOLO v5 są prawie tak samo wysokie. Największy model, YOLO v5x, ma nieco wyższą wartość mAP (Kin-Yiu, 2020).

Jocher omówił także wydajność szkolenia na Github.com Repo/Issues, stwierdzając, że „nasz najmniejszy YOLOv5 trenuje na COCO w zaledwie 3 dni na jednym 2080Ti i uruchamia wnioskowanie szybciej i dokładniej niż EfficientDet D0, który został przeszkolony na 32 rdzeniach TPUv3 przez firmę Zespół Google Brain. Co za tym idzie, naszym celem jest porównywalne przekraczanie D1, D2 itp. z resztą rodziny YOLOv5” (Jocher, 2020)
W następnym artykule dokonam przeglądu wydajności uczenia i wnioskowania na różnych platformach sprzętowych.
Czekać na dalsze informacje!
Bibliografia
Ahmad, R., 2020. Wszystko o YOLO — część 4 — YOLOv3, stopniowe doskonalenie. [Online]
Dostępne pod adresem: https://medium.com/analytics-vidhya/all-about-yolos-part4-yolov3-an-inkrementalna-improvement-36b1eee463a2
Bochkovskiy, A., 2020. Github.com, YOLOv5 O odtworzonych wynikach Dyskusja. [Online]
Dostępne pod adresem: https://github.com/ultralytics/yolov5/issues/6#issuecomment-643644347
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M., 2020. YOLOv4: Optymalna prędkość i dokładność wykrywania obiektów. arXiv,tom arXiv:2004.10934v1.
Chen, L.-C., Papandreou, G., Murphy, K. & Yuille, A. L., 2017. DeepLab: Semantyczna segmentacja obrazu za pomocą głębokich sieci splotowych, splotu Atrous i w pełni połączonych CRF. arXiv,Wolumin arXiv:1606.00915v2.
Girshick, R., 2015. Szybki R-CNN. arXiv,Wydanie 1504.08083v2.
Girshick, R., Donahue, J., Darrell, T. & Malik, J., 2013. Bogate hierarchie funkcji umożliwiające dokładne wykrywanie obiektów i segmentację semantyczną. [Online]
Dostępne pod adresem: https://arxiv.org/pdf/1311.2524.pdf
Grel, T., 2017. Wyjaśnienie regionu łączenia odsetek. [Online]
Dostępne pod adresem: https://deepsense.ai/region-of-interest-pooling-explained/
On, K., Gkioxari, G., Dollar, P. i Girshick, R., 2017. Maska R-CNN. arXiv,Wolumin arXiv:1703.06870v3.
He, K., Zhang, X., Ren, S. i Sun, J., 2015. Łączenie piramid przestrzennych w głębokich sieciach splotowych na potrzeby rozpoznawania wizualnego.
Hu, J. i in., 2019. Sieci ściskania i wzbudzania. arXiv,Wolumin arXiv:1709.01507v4.
Jocher, G., 2020. Github.com, Problemy. [Online]
Dostępne pod adresem: https://github.com/ultralytics/yolov5/issues/2#issuecomment-642425558
Jocher, G., 2020. YOLOv5. [Online]
Dostępne pod adresem: https://github.com/ultralytics/yolov5
Kin-Yiu, W., 2020. Github.com. [Online]
Dostępne pod adresem: https://github.com/ultralytics/yolov5/issues/6#issuecomment-647069454
Lin, T.-Y.et al., 2018. Utrata ogniskowej w przypadku wykrywania gęstych obiektów. arXiv,Wolumin arXiv:1708.02002v2.
Liu, S., Huang, D. i Wang, Y., 2018. Sieć bloków pola recepcyjnego zapewniająca dokładne i szybkie wykrywanie obiektów. arXiv,Wolumin arXiv:1711.07767v3 .
Liu, W. i in., 2016. SSD: Detektor MultiBox z pojedynczym strzałem.
Redmon, J., Divvala, S., Girshick, R. i Farhadi, A., 2015. Patrzysz tylko raz: ujednolicone wykrywanie obiektów w czasie rzeczywistym. arXiv,Problem arXiv:1506.02640v5.
Redmon, J., Divvala, S., Girshick, R. i Farhadi, A., 2016. Patrzysz tylko raz: ujednolicone wykrywanie obiektów w czasie rzeczywistym.
Redmon, J. i Farhadi, A., 2016. YOLO9000: Lepiej, szybciej, mocniej. arXiv,Problem arXiv:1612.08242v1.
Redmon, J. i Farhadi, A., 2018. YOLOv3: Stopniowe doskonalenie. arXiv,Wolumin arXiv:1804.02767v1.
Ren, S., He, K., Girshick, R. i Sun, J., 2015. Szybszy R-CNN: w stronę wykrywania obiektów w czasie rzeczywistym za pomocą sieci propozycji regionów. arXiv,tom 1506.01497v3.
Szegedy, C., Vanhoucke, V., Ioffe, S. & Shlens, J., 2015. Ponowne przemyślenie architektury początkowej dla widzenia komputerowego. arXiv,Wolumin arXiv:1512.00567v3 .
Twitter, 2020. Twitter. [Online]
Dostępne pod adresem: https://twitter.com/pjreddie/status/1230524770350817280?s=20
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S., 2018. CBAM: Moduł uwagi bloku splotowego. arXiv,Wolumin arXiv:1807.06521v2.
Zhao, Z.-Q., Zheng, P., Xu, S.-t. & Wu, X., 2019. Wykrywanie obiektów za pomocą głębokiego uczenia się: recenzja. arXiv,Wolumin arXiv:1807.05511v2.