Wykorzystanie DeepShap do zrozumienia i udoskonalenia modelu napędzającego samochód autonomiczny

Przerażają mnie autonomiczne samochody. Wielkie kawałki metalu latają bez ludzi, którzy mogliby je powstrzymać, jeśli coś pójdzie nie tak. Aby zmniejszyć to ryzyko, nie wystarczy ocenić modele napędzające te bestie. Musimy także zrozumieć, w jaki sposób prognozują. Ma to na celu uniknięcie wszelkich przypadków Edge, które mogłyby spowodować nieprzewidziane wypadki.
OK, więc nasza aplikacja nie jest tak konsekwentna. Będziemy debugować model zastosowany do napędu minisamochodu (najgorsze, czego można się spodziewać, to stłuczona kostka). Mimo to metody IML mogą być przydatne. Zobaczymy, jak mogą jeszcze poprawić wydajność modelu.
W szczególności:
- Dostosuj ResNet-18 za pomocą PyTorch z danymi obrazu i ciągłą zmienną docelową
- Oceń model za pomocą MSE i wykresów punktowych
- Zinterpretuj model za pomocą DeepSHAP
- Popraw model poprzez lepsze gromadzenie danych
- Omów, w jaki sposób powiększenie obrazu mogłoby jeszcze bardziej ulepszyć model
Po drodze omówimy kilka kluczowych fragmentów kodu Pythona. Pełny projekt można także znaleźć na GitHub.
Jeśli dopiero zaczynasz korzystać z SHAP, obejrzyj filmponiżej. Jeśli chcesz więcej, sprawdź mój Kurs SHAP. Możesz uzyskać bezpłatny dostęp, jeśli zapiszesz się na mój Biuletyn :)
Pakiety Pythona
# Imports import numpy as np import pandas as pd import matplotlib.pyplot as plt import glob import random from PIL import Image import cv2 import torch import torchvision from torchvision import transforms from torch.utils.data import DataLoader import shap from sklearn.metrics import mean_squared_error
Zbiór danych
Projekt zaczynamy od zebrania danych tylko w jednym pomieszczeniu (będzie to nas prześladować). Jak wspomniano, używamy obrazów do zasilania zautomatyzowanego samochodu. Przykłady można znaleźć na Kaggle. Wszystkie te obrazy mają wymiary 224 x 224 pikseli.
Wyświetlamy jeden z nich za pomocą poniższego kodu. Zanotuj nazwę obrazu (wiersz 2). Pierwsze dwie liczby to współrzędne x i y w ramce 224 x 224. Na Rysunku 1 widać, że współrzędne te zostały wyświetlone w zielonym kółku (linia 8).
#Load example image
name = "32_50_c78164b4-40d2-11ed-a47b-a46bb6070c92.jpg"
x = int(name.split("_")[0])
y = int(name.split("_")[1])
img = Image.open("../data/room_1/" + name)
img = np.array(img)
cv2.circle(img, (x, y), 8, (0, 255, 0), 3)
plt.imshow(img)

Te współrzędne są zmienną docelową. Model przewiduje je, wykorzystując obraz jako dane wejściowe. Ta prognoza jest następnie wykorzystywana do kierowania samochodem. W tym przypadku widać, że samochód zbliża się do skrętu w lewo. Idealnym kierunkiem jest podążanie w kierunku współrzędnych podanych przez zielone kółko.
Trenowanie modelu PyTorch
Chcę się skupić na SHAP, więc nie będziemy zagłębiać się zbytnio w kod modelowania. Jeśli masz jakieś pytania, możesz je zadać w komentarzach.
Zaczynamy od utworzenia klasy ImageDataset. Służy do ładowania naszych danych obrazu i zmiennych docelowych. Robi to za pomocą ścieżek do naszych obrazów. Należy zwrócić uwagę na sposób skalowania zmiennych docelowych — zarówno x, jak i y będą wynosić od -1 do 1 mocny>.
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, paths, transform):
self.transform = transform
self.paths = paths
def __getitem__(self, idx):
"""Get image and target (x, y) coordinates"""
# Read image
path = self.paths[idx]
image = cv2.imread(path, cv2.IMREAD_COLOR)
image = Image.fromarray(image)
# Transform image
image = self.transform(image)
# Get target
target = self.get_target(path)
target = torch.Tensor(target)
return image, target
def get_target(self,path):
"""Get the target (x, y) coordinates from path"""
name = os.path.basename(path)
items = name.split('_')
x = items[0]
y = items[1]
# Scale between -1 and 1
x = 2.0 * (int(x)/ 224 - 0.5) # -1 left, +1 right
y = 2.0 * (int(y) / 244 -0.5)# -1 top, +1 bottom
return [x, y]
def __len__(self):
return len(self.paths)
W rzeczywistości, gdy model jest wdrażany, do kierowania samochodem wykorzystywane są tylko przewidywania x. Ze względu na skalowanie znak przewidywania x określi kierunek samochodu. Gdy x ‹ 0, samochód powinien skręcić w lewo. Podobnie, gdy x › 0 samochód powinien skręcić w prawo. Im większa wartość x, tym ostrzejszy skręt.
Klasę ImageDataset wykorzystujemy do tworzenia modułów ładujących dane szkoleniowe i walidacyjne. Odbywa się to poprzez losowy podział 80/20 wszystkich ścieżek obrazu z pokoju 1. Ostatecznie mamy 1217i 305 obrazy odpowiednio w zestawie szkoleniowym i walidacyjnym.
TRANSFORMS = transforms.Compose([
transforms.ColorJitter(0.2, 0.2, 0.2, 0.2),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
paths = glob.glob('../data/room_1/*')
# Shuffle the paths
random.shuffle(paths)
# Create a datasets for training and validation
split = int(0.8 * len(paths))
train_data = ImageDataset(paths[:split], TRANSFORMS)
valid_data = ImageDataset(paths[split:], TRANSFORMS)
# Prepare data for Pytorch model
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=valid_data.__len__())
Zwróć uwagę na batch_size valid_loader. Używamy długości zbioru danych walidacyjnych (tj. 305). Dzięki temu możemy załadować wszystkie dane walidacyjne w jednej iteracji. Jeśli pracujesz z większymi zbiorami danych, może być konieczne użycie mniejszego rozmiaru partii.
Ładujemy wstępnie wytrenowany model ResNet18 (linia 5). Ustawiając model.fc, aktualizujemy ostatnią warstwę (linia 6). Jest to w pełni połączona warstwa od 512 węzłów do naszych 2 docelowych węzłów zmiennych. Będziemy używać optymalizatora Adama do dostrojenia tego modelu (wiersz 9).
output_dim = 2 # x, y
device = torch.device('mps') # or 'cuda' if you have a GPU
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, output_dim)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
Wytrenowałem model przy użyciu procesora graficznego (linia 2). Nadal będziesz mógł uruchomić kod na procesorze. Dostrajanie nie jest tak kosztowne obliczeniowo, jak szkolenie od zera!
Wreszcie mamy nasz kod szkoleniowy modelu. Trenujemy przez 10 epok, używając MSE jako naszej funkcji straty. Nasz ostateczny model to ten, który ma najniższy MSE w zestawie walidacyjnym.
name = "direction_model_1" # Change this to save a new model
# Train the model
min_loss = np.inf
for epoch in range(10):
model = model.train()
for images, target in iter(train_loader):
images = images.to(device)
target = target.to(device)
# Zero gradients of parameters
optimizer.zero_grad()
# Execute model to get outputs
output = model(images)
# Calculate loss
loss = torch.nn.functional.mse_loss(output, target)
# Run backpropogation to accumulate gradients
loss.backward()
# Update model parameters
optimizer.step()
# Calculate validation loss
model = model.eval()
images, target = next(iter(valid_loader))
images = images.to(device)
target = target.to(device)
output = model(images)
valid_loss = torch.nn.functional.mse_loss(output, target)
print("Epoch: {}, Validation Loss: {}".format(epoch, valid_loss.item()))
if valid_loss < min_loss:
print("Saving model")
torch.save(model, '../models/{}.pth'.format(name))
min_loss = valid_loss
Metryki oceny
W tym momencie chcemy zrozumieć, jak radzi sobie nasz model. Przyglądamy się MSE i wykresom punktowym rzeczywistych i przewidywanych wartości x. Na razie ignorujemy y, ponieważ nie ma to wpływu na kierunek samochodu.
Zestaw szkoleniowy i walidacyjny
Rysunek 2 przedstawia te metryki w zestawie szkoleniowym i walidacyjnym. Ukośna czerwona linia daje doskonałe przewidywania. Istnieje podobna odmiana wokół tej prostej dla x ‹ 0 i x › 0. Innymi słowy, model jest w stanie przewidzieć skręty w lewo i w prawo z podobną dokładnością. Podobna wydajność zbioru uczącego i walidacyjnego wskazuje również, że model nie jest nadmiernie dopasowany.
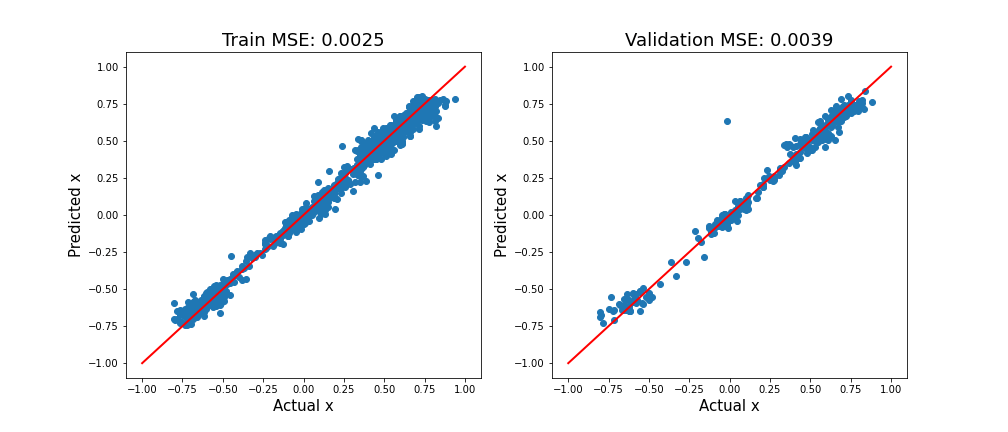
Do stworzenia powyższego wykresu używamy funkcji model_evaluation. Należy pamiętać, że moduły ładujące dane należy utworzyć w taki sposób, aby ładowały wszystkie dane w pierwszej iteracji.
def model_evaluation(loaders,labels,save_path = None):
"""Evaluate direction models with mse and scatter plots
loaders: list of data loaders
labels: list of labels for plot title"""
n = len(loaders)
fig, axs = plt.subplots(1, n, figsize=(7*n, 6))
# Evalution metrics
for i, loader in enumerate(loaders):
# Load all data
images, target = next(iter(loader))
images = images.to(device)
target = target.to(device)
output=model(images)
# Get x predictions
x_pred=output.detach().cpu().numpy()[:,0]
x_target=target.cpu().numpy()[:,0]
# Calculate MSE
mse = mean_squared_error(x_target, x_pred)
# Plot predcitons
axs[i].scatter(x_target,x_pred)
axs[i].plot([-1, 1],
[-1, 1],
color='r',
linestyle='-',
linewidth=2)
axs[i].set_ylabel('Predicted x', size =15)
axs[i].set_xlabel('Actual x', size =15)
axs[i].set_title("{0} MSE: {1:.4f}".format(labels[i], mse),size = 18)
if save_path != None:
fig.savefig(save_path)
Możesz zobaczyć, co mamy na myśli, gdy używamy poniższej funkcji. Stworzyliśmy nowy train_loader, ustawiający wielkość partii na długość zbioru danych szkoleniowych. Ważne jest także załadowanie zapisanego modelu (linia 2). W przeciwnym razie skończysz na modelu wytrenowanym w ostatniej epoce.
# Load saved model
model = torch.load('../models/direction_model_1.pth')
model.eval()
model.to(device)
# Create new loader for all data
train_loader = DataLoader(train_data, batch_size=train_data.__len__())
# Evaluate model on training and validation set
loaders = [train_loader,valid_loader]
labels = ["Train","Validation"]
# Evaluate on training and validation set
model_evaluation(loaders,labels)
Przeprowadzka do nowych lokalizacji
Wyniki wyglądają dobrze! Oczekiwaliśmy, że samochód będzie dobrze się sprawował i tak się stało. Tak było, dopóki nie przenieśliśmy go do nowej lokalizacji:

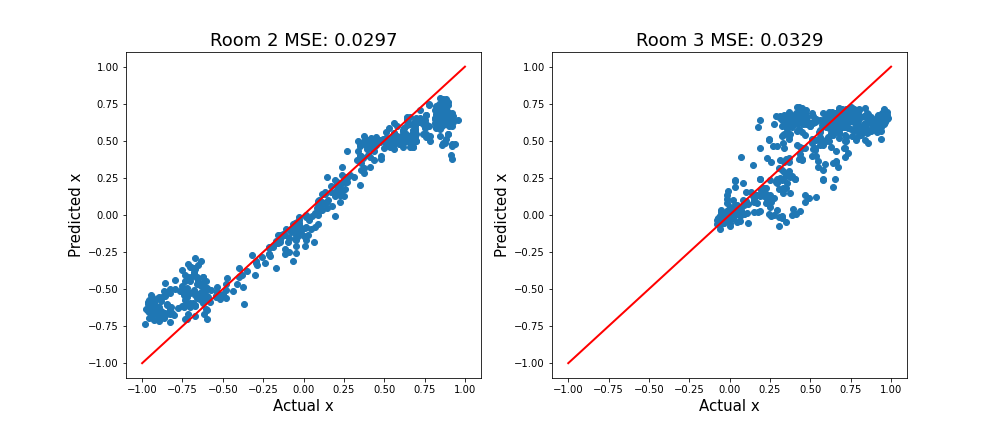
Zbieramy dane z nowych lokalizacji (pokój 2 i pokój 3). Przeprowadzając ocenę tych obrazów, można zauważyć, że nasz model nie działa równie dobrze. To jest dziwne! Samochód jedzie dokładnie po tym samym torze, więc dlaczego pomieszczenie ma znaczenie?
Debugowanie modelu za pomocą SHAP
Szukamy odpowiedzi w firmie SHAP. Można go wykorzystać do zrozumienia, które piksele są ważne dla danej prognozy. Zaczynamy od załadowania naszego zapisanego modelu (linia 2). SHAP nie został zaimplementowany dla GPU, dlatego ustawiamy urządzenie na CPU (linie 5–6).
# Load saved model
model = torch.load('../models/direction_model_1.pth')
# Use CPU
device = torch.device('cpu')
model = model.to(device)
Aby obliczyć wartości SHAP, musimy uzyskać obrazy tła. SHAP zintegruje te obrazy podczas obliczania wartości. Używamy batch_size 100 obrazów. To powinno dać nam rozsądne przybliżenia. Zwiększenie liczby obrazów poprawi przybliżenie, ale także wydłuży czas obliczeń.
#Load 100 images for background shap_loader = DataLoader(train_data, batch_size=100, shuffle=True) background, _ = next(iter(shap_loader)) background = background.to(device)
Tworzymy obiekt wyjaśniający, przekazując nasz model i obrazy tła do funkcji DeepExplainer. Ta funkcja skutecznie przybliża wartości SHAP dla sieci neuronowych. Alternatywnie możesz zastąpić ją funkcją GradientExplainer.
#Create SHAP explainer explainer = shap.DeepExplainer(model, background)
Ładujemy 2 przykładowe obrazy — skręt w prawo i w lewo (linia 2) i przekształcamy je (linia 6). Jest to ważne, ponieważ obrazy powinny mieć ten sam format, jaki został użyty do uczenia modelu. Następnie obliczamy wartości SHAP dla przewidywań dokonanych na podstawie tych obrazów (linia 10).
# Load test images of right and left turn
paths = glob.glob('../data/room_1/*')
test_images = [Image.open(paths[0]), Image.open(paths[3])]
test_images = np.array(test_images)
test_input = [TRANSFORMS(img) for img in test_images]
test_input = torch.stack(test_input).to(device)
# Get SHAP values
shap_values = explainer.shap_values(test_input)
Na koniec możemy wyświetlić wartości SHAP za pomocą funkcji image_plot. Najpierw jednak musimy je zrestrukturyzować. Wartości SHAP są zwracane z wymiarami:
( #targets, #images, #channels, #width, #height)
Używamy funkcji transpozycji, więc mamy wymiary:
( #targets, #images, #width, #height, #channels)
Uwaga, przekazaliśmy także oryginalne obrazy do funkcji image_plot. Obrazy test_input wyglądałyby dziwnie z powodu przekształceń.
# Reshape shap values and images for plotting shap_numpy = list(np.array(shap_values).transpose(0,1,3,4,2)) test_numpy = np.array([np.array(img) for img in test_images]) shap.image_plot(shap_numpy, test_numpy,show=False)
Wynik możesz zobaczyć na Rysunku 4. Pierwsza kolumna zawiera oryginalne obrazy. Druga i trzecia kolumna to odpowiednio wartości SHAP dla predykcji x i y. Niebieskie piksele zmniejszyły przewidywanie. Dla porównania, czerwone piksele zwiększyły przewidywanie. Innymi słowy, w przypadku przewidywania x czerwone piksele spowodowały ostrzejszy skręt w prawo.

Teraz gdzieś dochodzimy. Ważnym rezultatem jest to, że model wykorzystuje piksele tła. Można to zobaczyć na rysunku 5, na którym przybliżamy prognozę x dla skrętu w prawo. Innymi słowy, tło jest ważne dla przewidywania. To wyjaśnia słabą wydajność! Kiedy przeprowadziliśmy się do nowego pokoju, tło się zmieniło, a nasze przewidywania stały się niewiarygodne.

Model jest nadmiernie dopasowany do danych z pomieszczenia nr 1. Na każdym obrazie występują te same obiekty i tło. W rezultacie model kojarzy je ze skrętami w lewo i w prawo. Nie mogliśmy tego zidentyfikować w naszej ocenie, ponieważ mamy to samo doświadczenie zarówno w obrazach szkoleniowych, jak i walidacyjnych.

Udoskonalanie modelu
Zależy nam na tym, aby nasz model dobrze spisał się w każdych warunkach. Aby to osiągnąć, spodziewalibyśmy się, że wykorzysta tylko piksele ze ścieżki. Omówmy zatem kilka sposobów zwiększenia wytrzymałości modelu.
Zbieranie nowych danych
Najlepszym rozwiązaniem jest po prostu zebranie większej ilości danych. Mamy już kilka z pokoju 2 i 3. Postępując w ten sam sposób, szkolimy nowy model, korzystając z danych ze wszystkich 3 pokoi. Patrząc na Rysunek 7, teraz działa on lepiej w przypadku obrazów z nowych pomieszczeń.

Mamy nadzieję, że trenując na danych z wielu pokoi, przełamiemy skojarzenia między obrotami a tłem. Na zakrętach w lewo i w prawo znajdują się teraz różne obiekty, ale tor pozostaje ten sam. Model powinien nauczyć się, że dla przewidywania ważny jest tor.
Możemy to potwierdzić, patrząc na wartości SHAP dla nowego modelu. Dotyczy to tych samych zakrętów, które widzieliśmy na Rysunku 4. Piksele tła przywiązują teraz mniejszą wagę. OK, nie jest idealnie, ale gdzieś zmierzamy.

Moglibyśmy nadal gromadzić dane. Im więcej lokalizacji zbierzemy, tym solidniejszy będzie nasz model. Gromadzenie danych może być jednak czasochłonne (i nudne!). Zamiast tego możemy pomyśleć o zwiększeniu ilości danych.
Rozszerzenia danych
Powiększanie danych ma miejsce wtedy, gdy systematycznie lub losowo zmieniamy obrazy za pomocą kodu. Dzięki temu możemy sztucznie wprowadzić szum i zwiększyć rozmiar naszego zbioru danych.
Na przykład możemy podwoić rozmiar naszego zbioru danych, odwracając obrazy wokół osi pionowej. Możemy to zrobić, ponieważ nasz tor jest symetryczny. Jak widać na rysunku 9, usunięcie również może być użyteczną metodą. Obejmuje to uwzględnianie obrazów, z których usunięto obiekty lub całe tło.

Budując solidny model, należy również wziąć pod uwagę takie czynniki, jak warunki oświetleniowe i jakość obrazu. Możemy je symulować za pomocą drgań kolorów lub dodając szum. Jeśli chcesz poznać wszystkie te metody, zapoznaj się z poniższym artykułem.
W powyższym artykule omawiamy również, dlaczego trudno jest stwierdzić, czy te ulepszenia zwiększyły wytrzymałość modelu. Moglibyśmy wdrożyć model w wielu środowiskach, ale jest to czasochłonne. Na szczęście SHAP może być używany jako alternatywa. Podobnie jak w przypadku gromadzenia danych, może nam to dać wgląd w to, jak ulepszenia zmieniły sposób, w jaki model formułuje prognozy.
Mam nadzieję, że podobał Ci się ten artykuł! Możesz mnie wesprzeć, zostając jednym z moich poleconych członków :)
| Twitter | YouTube | Newsletter — zapisz się, aby otrzymać DARMOWY dostęp do kursu Python SHAP
Zbiór danych
Obrazy JatRacer (CC0: domena publiczna) https://www.kaggle.com/datasets/conorsully1/jatracer-images
Bibliografia
SHAP, Przykład PyTorch Deep Wyjaśniacz MNIST https://shap.readthedocs.io/en/latest/example_notebooks/image_examples/image_classification/PyTorch%20Deep%20Explainer%20MNIST%20example.html