Najczęściej nasze platformy dla przedsiębiorstw są przeznaczone do tworzenia tradycyjnych aplikacji. Zwykle składają się z czterech środowisk — deweloperskiego, testowego, przedprodukcyjnego i produkcyjnego — przy czym w miarę postępów w nich środowiska stają się coraz bezpieczniejsze.
W związku z tym „Dev” lub Development to najbardziej liberalna ze stref, w której programiści mogą zazwyczaj robić, co im się podoba, a z drugiej strony „Prod” lub Production to strefa bezdotykowa i zwykle jedyne miejsce, w którym mogą znajdować się aktualne dane .
Jednakże środowiska te zwykle nie są odpowiednie do tworzenia i wydawania produktów danych. Przez „produkty danych” rozumiemy aplikacje, w których dane i kod są ściśle powiązane i od siebie zależne. Modele uczenia maszynowego są doskonałym przykładem; gdzie badacze danych rozpoczynają swój cykl życia od badania bieżących danych i gdzie parametry modelu zależą od danych, na których zostali przeszkoleni.

W tych scenariuszach potrzebne są surowe (nieanonimowe) dane na dużą skalę, aby można było zidentyfikować rzeczywiste trendy i korelacje wielu zmiennych, aby można było łączyć dane z wielu systemów źródłowych oraz aby testy etyczne, takie jak wykrywanie stronniczości, mogły odbywać się.
Dane syntetyczne lub anonimowe nie są w tym przypadku wystarczające, szczególnie w dużych organizacjach z wieloma obszarami biznesowymi, w których różne modele danych, pamięć masowa, infrastruktura i starsze systemy komplikują ten krajobraz. Posiadanie aktualnych, zanonimizowanych danych, które zachowują integralność referencyjną i relacje statystyczne w wielu milionach rekordów w tysiącach pól w setkach różnych systemów źródłowych, jest w rzeczywistości niewykonalne.
Próba umożliwienia oprogramowania RTL obsługiwania danych
Gdy organizacje zaakceptują, że będą musiały pracować z bieżącymi danymi, próbują narzucić istniejące oprogramowanie RTL, wciskając kwadratowy kołek w okrągły otwór, i ostatecznie wybierają jedną z dwóch opcji:
- Wypychanie danych do niższych środowisk, w których odbywa się rozwój; Lub
- Przeniesienie rozwoju na wyższe środowiska, w których znajdują się aktualne dane
Pierwsza opcja oznacza wprowadzenie nowych zagrożeń, ponieważ Twoje dane opuściły stalowy pierścień Production i znajdują się teraz w mniej kontrolowanym środowisku, co jest szczególnie niebezpieczne w chmurze publicznej. W dobrze zarządzanych przedsiębiorstwach będzie to również obejmować rezygnację z danych w poszczególnych przypadkach użycia, co utrudnia skalowanie.
Druga opcja oznacza wprowadzenie użytkowników i nowych narzędzi do wcześniej ściśle kontrolowanego środowiska, w którym wszystkie aplikacje działały w ramach kont usług. Możesz także mieć uzasadnione obawy dotyczące prac programistycznych lub fałszywego zapytania wpływającego obecnie na obciążenie o znaczeniu krytycznym dla firmy.
Z dwóch opcji druga jest prawdopodobnie mniejszym złem, o ile można wprowadzić pewne elementy sterujące w celu odizolowania działań związanych z kompilacją od obciążeń produkcyjnych, na przykład przy użyciu kolejek zasobów.
Ale jakie jest lepsze rozwiązanie?
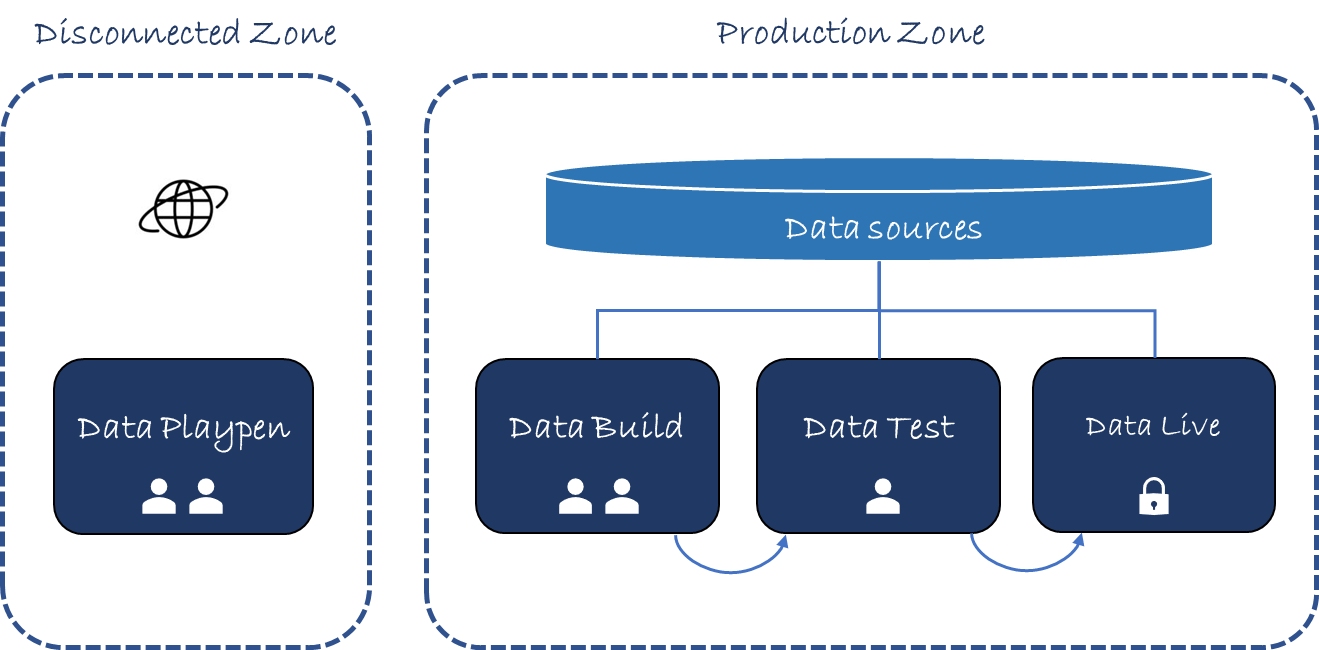
W stalowym kręgu Production, zdefiniowanym poprzez segregację sieci, utwórz trzy zupełnie nowe środowiska tworzące nowy Data Route to Live:
- Kompilacja danych
- Test danych
- Dane na żywo
Budowanie danych umożliwi dostęp człowieka w ramach interaktywnych sesji, podczas których można będzie analizować aktualne dane na dużą skalę za pomocą szeregu narzędzi i podczas których będzie można tworzyć produkty oparte na danych. To jest Twoje środowisko EDA (Exploratory Data Analytics).
W ramach Testu danych nowo utworzone produkty danych zostaną poddane szeregowi testów, w tym testom wydajności i etyki. Będziesz potrzebować znacznie mniej narzędzi programistycznych, ponieważ to po prostu tutaj przeprowadzane są końcowe kontrole przed wdrożeniem. Jeśli weryfikacja zakończy się niepowodzeniem, przed powrotem tutaj przejdziesz do kompilacji danych, aby przeprowadzić naprawę.
W ramach Data Live produkty danych będą działać jako aplikacje w ramach kont usług, a środowisko będzie wolne od narzędzi (ani w rzeczywistości dostępu człowieka), z wyjątkiem możliwości monitorowania. Te możliwości monitorowania będą umożliwiały wykonywanie działań związanych z danymi, takich jak wykrywanie dryftu danych.
We wszystkich tych trzech środowiskach dane źródłowe przedsiębiorstwa stanowią ten sam zasób. Nie ma mowy o powielaniu ani kopiowaniu danych, chyba że działasz w szczególnie nieelastycznym środowisku. Dzięki takiemu podejściu potoki środowiska muszą jedynie promować kod w środowiskach.
Być może potrzebne jest jedno końcowe środowisko: kojec lub strefa eksperymentów. Tutaj programiści mają pełną swobodę, w tym dostęp do Internetu.
4.Kojec danych
Data Playpen jest odłączony od reszty Data RTL poprzez segregację sieci i prawdopodobnie jest odłączony od reszty Twojego przedsiębiorstwa. Jest to poligon doświadczalny dla nowych narzędzi lub technik, niezależnie od danych lub być może z danymi syntetycznymi. Praca w tym środowisku będzie raczej informować o sposobie myślenia niż być pierwszym krokiem w budowaniu produktu opartego na danych.
W jaki sposób RTL oprogramowania i RTL danych mogą współistnieć?
Większość nowoczesnych przedsiębiorstw będzie potrzebować obu RTL, szczególnie jeśli chcą korzystać z zaawansowanych analiz, a dobra wiadomość jest taka, że mogą one stosunkowo sprawnie współistnieć w ramach jednej platformy:

Należy podjąć decyzję, że „Data Live” i „Prod” są w rzeczywistości tym samym środowiskiem lub dwoma oddzielnymi środowiskami, ponieważ na tym etapie cyklu życia produkt danych można uznać za samodzielną aplikację działającą w ramach konta usługi. Będzie to wymagało sprawdzenia, ale jeśli dołączasz nową RTL danych do istniejącej platformy z istniejącą RTL oprogramowania, prawdopodobnie łatwiej będzie uniknąć zwijania ich w jedno środowisko.
Wreszcie, czasami zaistnieją scenariusze, w których twórcy danych będą budować komponenty inżynierii oprogramowania, które będą wspierać tworzenie lub konserwację ich produktów danych. Może to być pakiet niestandardowy lub magazyn audytu, który rejestruje dane wejściowe i wyjściowe modelu danych.
Tutaj możesz zobaczyć połączenie dwóch RTL, począwszy od oprogramowania RTL Dev, Test, Pre-Prod, ale następnie będącego świadkiem równoczesnego wydania do Data Build, Data Test i Data Live, dzięki czemu artefakt jest dostępny do nowych prac związanych z tworzeniem danych.
Pamiętaj, że Data RTL zapewnia uprzywilejowany dostęp, którego nie należy rozszerzać poza określonych członków organizacji, którzy muszą wykonywać określone czynności obejmujące dostęp ludzi do aktualnych danych.
Do tych użytkowników należeć będą nie tylko specjaliści zajmujący się danymi, ale także osoby, które muszą testować aplikacje na rzeczywistych danych, aby zapewnić klientom uczciwe wyniki.
Tam, gdzie dane i kod są niezależne, programiści powinni zawsze korzystać z oprogramowania RTL.