W ostatnich latach w dziedzinie głębokiego uczenia się nastąpił bezprecedensowy postęp, napędzany chęcią naśladowania skomplikowanego działania ludzkiego mózgu. U podstaw głębokiego uczenia się leży odtworzenie zdolności mózgu do przetwarzania informacji z różnych źródeł i wyciągania znaczących wniosków. Ta głęboka inspiracja doprowadziła do opracowania nowatorskich architektur, które nie tylko umożliwiają realizację złożonych zadań, ale także odkrywają głębsze warstwy reprezentacji danych. W rezultacie architektury są dla nas kluczowe, nie tylko dlatego, że wiele wyzwań opiera się na zadaniach, które możemy z nimi wykonać. W rzeczywistości projekt samych sieci wskazuje nam na reprezentację, której poszukiwali badacze, aby lepiej uczyć się na podstawie danych .
LeNet
Pionierskie prace
Zanim zaczniemy, zauważmy, że nie odnieślibyśmy sukcesu, gdybyśmy po prostu użyli surowego wielowarstwowego perceptronu połączonego z każdym pikselem obrazu. Oprócz tego, że jest to szybko trudne do wykonania, ta bezpośrednia operacja nie jest zbyt wydajna, ponieważ piksele są skorelowane przestrzennie.
Dlatego najpierw musimy wyodrębnić
- znaczące i
- Funkcje niskowymiarowe, nad którymi możemy popracować.
I tu właśnie pojawiają się konwolucyjne sieci neuronowe!
Aby rozwiązać ten problem, pomysł Yanna Le Cuna składa się z kilku etapów.
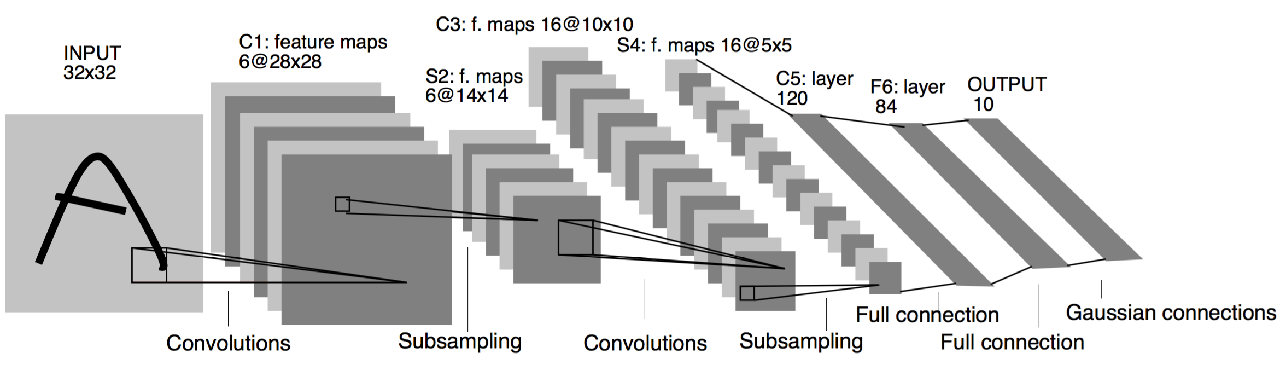
Jak zaobserwowano, wymiary funkcji są stopniowo zmniejszane w architekturze sieci. Ostatecznie te udoskonalone funkcje wysokiego poziomu są spłaszczane i przekazywane do w pełni połączonych warstw. Warstwy te z kolei generują prawdopodobieństwa dla różnych klas za pośrednictwem warstwy softmax.
W trakcie fazy uczenia sieć nabywa umiejętność dostrzegania cech wyróżniających, które klasyfikują daną próbkę do określonej kategorii. Ten proces uczenia się jest ułatwiony dzięki propagacji wstecznej, podczas której sieć dostosowuje swoje wewnętrzne parametry w oparciu o rozbieżności między przewidywanymi a rzeczywistymi wynikami.
Aby zilustrować tę koncepcję, rozważmy obraz przedstawiający konia. Początkowo filtry sieci mogą koncentrować się na ogólnym konturze zwierzęcia. W miarę zagłębiania się w sieć, osiąga ona wyższy poziom abstrakcji, umożliwiając uchwycenie drobniejszych szczegółów, takich jak oczy i uszy konia.
Zasadniczo konwolucyjne sieci neuronowe (ConvNets) służą jako mechanizm konstruowania funkcji, które w przypadku braku takiej architektury wymagałyby ręcznego tworzenia. Podkreśla to potencjał ConvNets w automatyzacji procesu ekstrakcji cech, rewolucjonizując w ten sposób krajobraz głębokiego uczenia się.
AlexNet
Droga Convolution do sławy
Można naturalnie zadać pytanie, dlaczego konwolucyjne sieci neuronowe (ConvNets) nie osiągnęły powszechnej popularności przed 1998 r. Zwięzłą odpowiedzią na to pytanie jest to, że ich pełne możliwości nie wykorzystały pełnego potencjału z powrotem
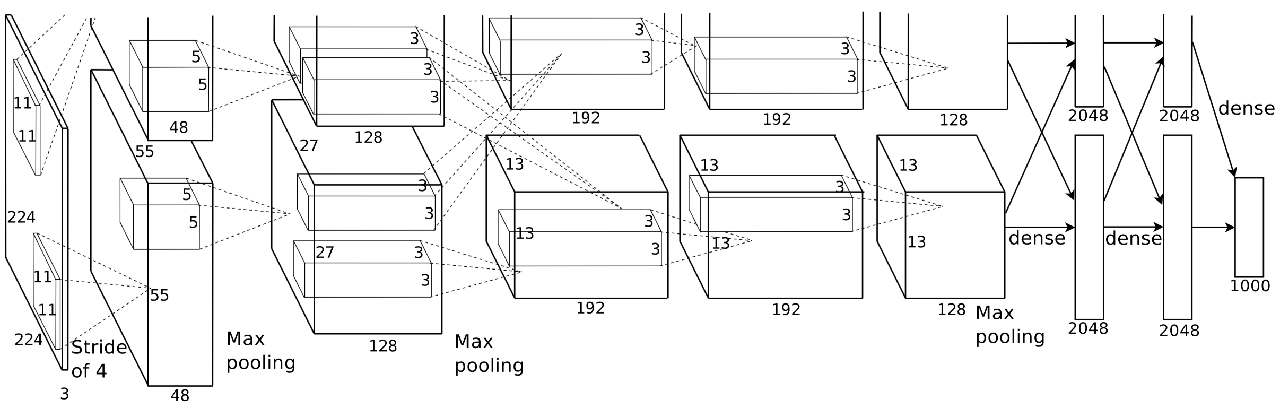
W tym przypadku AlexNet stosuje to samo podejście od góry do dołu, w którym kolejne filtry są zaprojektowane tak, aby wychwytywać coraz bardziej subtelne cechy. Ale tutaj jego praca zbadała kilka kluczowych szczegółów.
- Po pierwsze, Kriżewski wprowadził lepszą nieliniowość w sieci poprzez aktywację ReLU, której pochodna wynosi 0, jeśli cecha jest poniżej 0 i 1 dla wartości dodatnich. Okazało się to skuteczne w przypadku propagacji gradientu.
- Po drugie, w jego artykule przedstawiono koncepcję porzucenia jako regularyzacji. Z punktu widzenia reprezentacji zmuszasz sieć do przypadkowego zapominania o wszystkim, aby mogła zobaczyć kolejne dane wejściowe z lepszej perspektywy.
Dajmy przykład: po zakończeniu czytania tego postu najprawdopodobniej zapomnisz o jego fragmentach. A jednak jest to w porządku, ponieważ będziesz pamiętał tylko o tym, co istotne.
Cóż, miejmy nadzieję. To samo dzieje się w przypadku sieci neuronowych, co sprawia, że model jest solidniejszy.
3. Wprowadzono także poszerzanie danych. Po wprowadzeniu do sieci obrazy są wyświetlane z losowym tłumaczeniem, obrotem i przycięciem. W ten sposób zmusza sieć do większej świadomości atrybutów obrazów, a nie samych obrazów.
Wreszcie kolejna sztuczka zastosowana przez AlexNet polega na tym, aby wejść głębiej. Tutaj widać, że przed operacjami łączenia ułożyli więcej warstw splotowych. Reprezentacja uwzględnia zatem dokładniejsze cechy, które okazują się przydatne przy klasyfikacji.
Sieć ta znacznie przewyższała najnowocześniejszą sieć z 2012 r., z błędem w pierwszej piątce wynoszącym 15,4% w zbiorze danych ImageNet.
VGGNet
Głębiej jest lepiej
Kolejnym kamieniem milowym w klasyfikacji obrazów było dalsze zbadanie ostatniego punktu, o którym wspomniałem: schodzenia głębiej.
I to działa. Sugeruje to, że takie sieci mogą osiągnąć lepszą hierarchiczną reprezentację danych wizualnych przy użyciu większej liczby warstw.
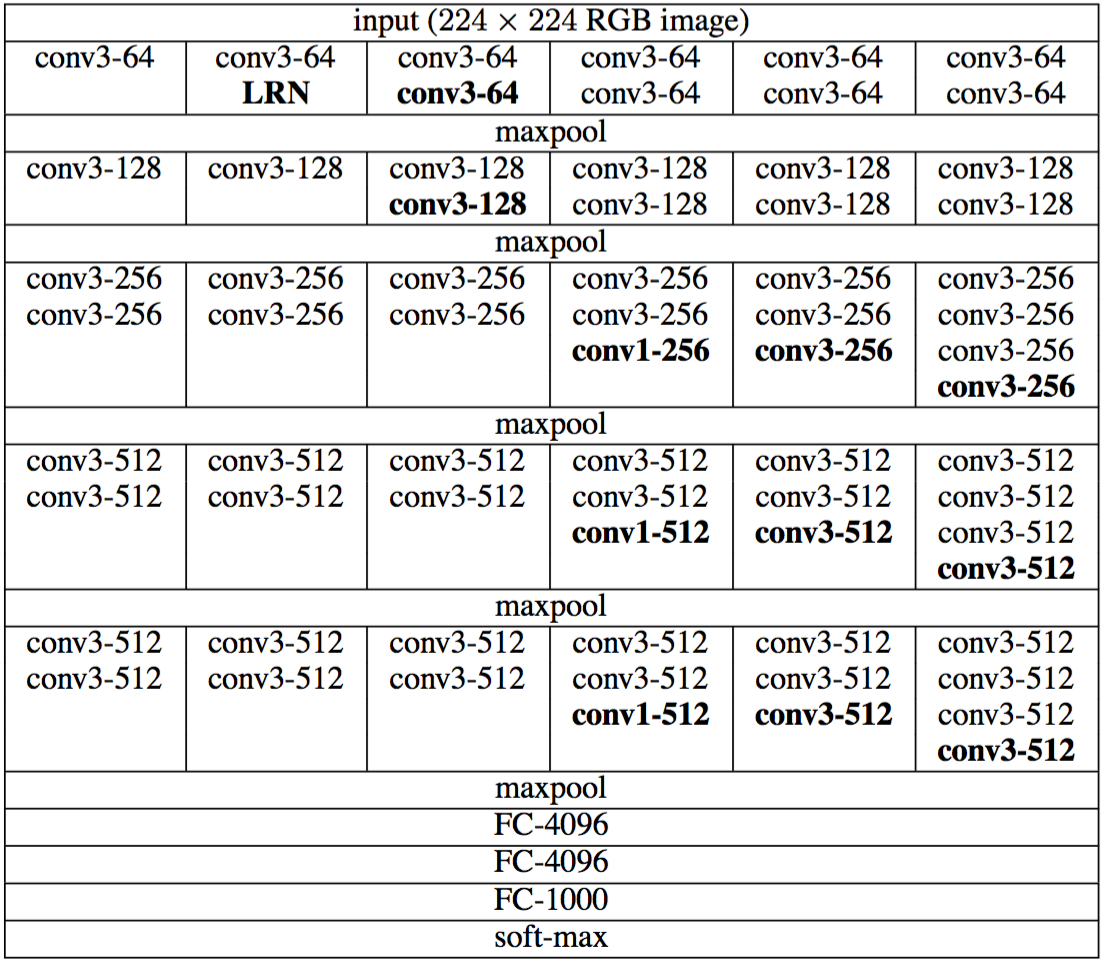
Jak widać, w tej sieci jest coś jeszcze wyjątkowego. Zawiera prawie wyłącznie zwoje 3 na 3. To ciekawe, prawda?
W rzeczywistości autorami kierowali się trzema głównymi powodami, aby to zrobić:
- Po pierwsze, użycie małych filtrów powoduje większą nieliniowość, co oznacza więcej stopni swobody dla sieci.
- Po drugie, układanie tych warstw razem umożliwia sieci widzieć więcej rzeczy, niż się wydaje. Na przykład w przypadku dwóch z nich sieć faktycznie widzi pole recepcyjne 5x5. A kiedy ułożysz 3 takie filtry, otrzymasz w rzeczywistości pole recepcyjne 7x7! Dlatego te same możliwości ekstrakcji cech, co w poprzednich przykładach, można osiągnąć również w tej architekturze.
- Po trzecie, używanie tylko małych filtrów ogranicza liczbę parametrów, co jest dobre, gdy chcesz sięgnąć tak głęboko.
Ilościowo rzecz biorąc, architektura ta osiągnęła 7,3% błędów w pierwszej piątce w ImageNet.
GoogleLeNet
Czas na inicjację
Następnie do gry wszedł GoogLeNet. Opiera swój sukces na swoich modułach startowych.
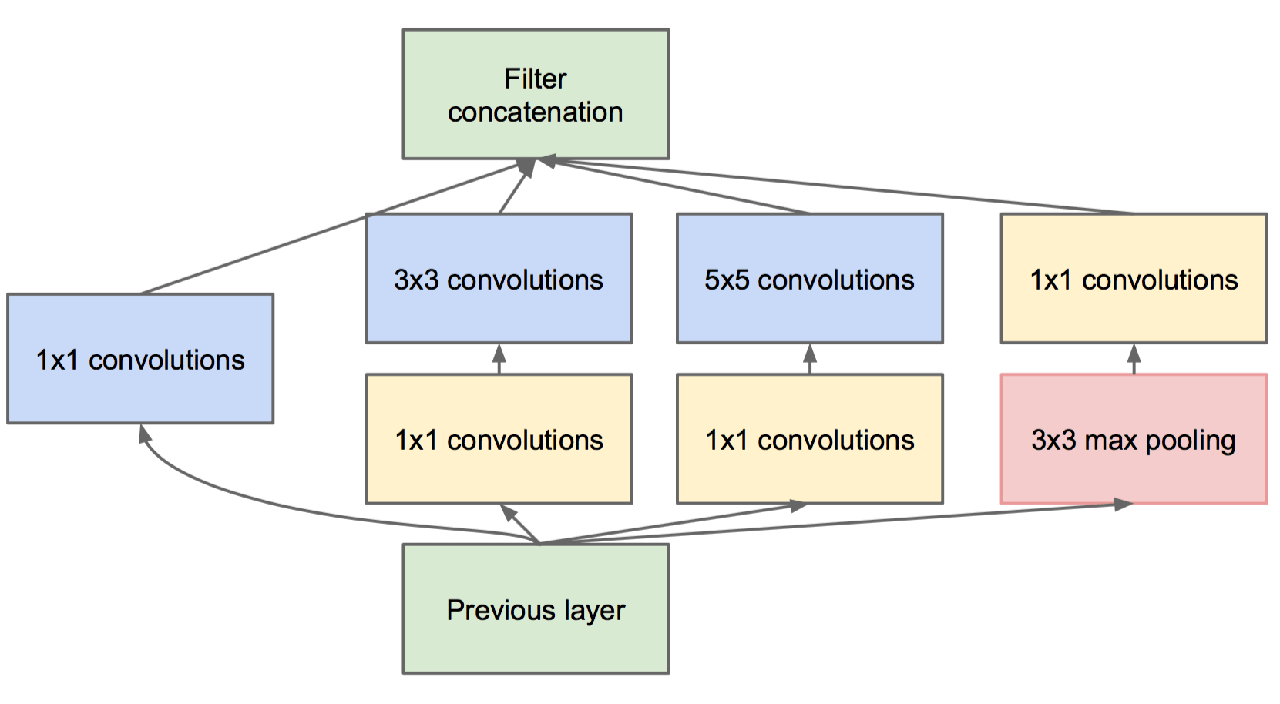
Jak widać, sploty o różnych rozmiarach filtrów są przetwarzane na tym samym wejściu, a następnie łączone razem.
Z punktu widzenia reprezentacji umożliwia to modelowi wykorzystanie wielopoziomowej ekstrakcji cech na każdym etapie. Na przykład cechy ogólne można wyodrębnić za pomocą filtrów 5x5 w tym samym czasie, gdy więcej cech lokalnych zostanie przechwyconych za pomocą splotów 3x3.
Ale wtedy mógłbyś mi powiedzieć. To świetnie. Ale czy nie jest to szalenie drogie w obliczeniach?
I powiedziałbym: bardzo dobra uwaga! Właściwie zespół Google miał na to genialne rozwiązanie: sploty 1x1.
- Z jednej strony zmniejsza wymiarowość Twoich funkcji.
- Z drugiej strony łączy mapy obiektów w sposób, który może być korzystny z punktu widzenia reprezentacji.
W takim razie możesz zapytać, dlaczego nazywa się to początkiem? Cóż, wszystkie te moduły można postrzegać jako sieci ułożone jedna nad drugą w ramach większej sieci.
A dla przypomnienia, najlepszy zespół GoogLeNet osiągnął błąd 6,7% w ImageNet.
ResNet
Połącz warstwy
Zatem wszystkie sieci, o których mówiliśmy wcześniej, podążały tym samym trendem: sięgały głębiej. Jednak w pewnym momencie zdajemy sobie sprawę, że ułożenie więcej warstw nie prowadzi do lepszej wydajności. W rzeczywistości jest dokładnie odwrotnie. Ale dlaczego tak jest?
Jednym słowem: gradient, panie i panowie.
Ale nie martw się, badacze znaleźli sposób, aby przeciwdziałać temu efektowi. W tym przypadku kluczową koncepcją opracowaną przez ResNet jest uczenie się szczątkowe.
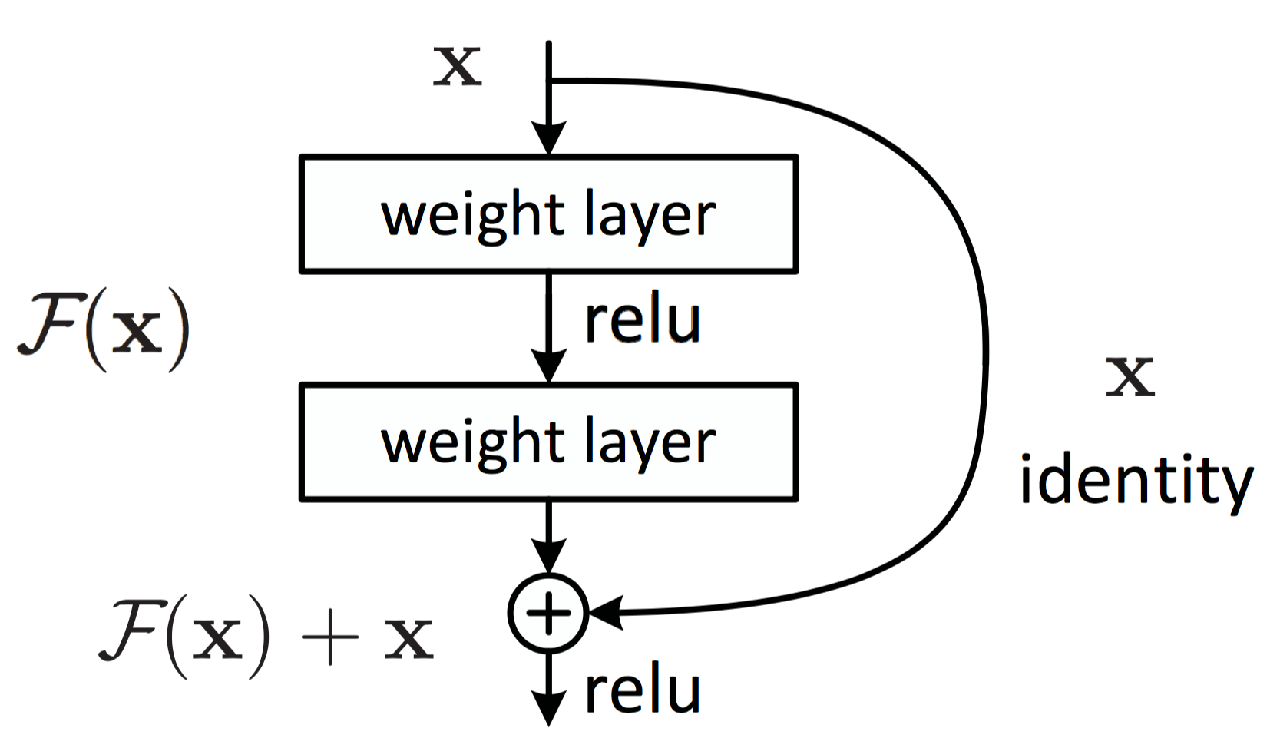
Jak widać, co dwie warstwy następuje mapowanie tożsamości poprzez dodanie elementów. Okazało się to bardzo pomocne przy propagacji gradientu, ponieważ błąd może być propagowany wstecz wieloma ścieżkami.
Ponadto z punktu widzenia reprezentacji pomaga to łączyć różne poziomy funkcji na każdym etapie sieci, tak jak widzieliśmy to w przypadku modułów początkowych.
Jest to do tej pory jedna z najlepiej działających sieci w ImageNet, z współczynnikiem błędów w pierwszej piątce wynoszącym 3,6%.
Gęsta sieć
Połącz więcej!
Później zaproponowano rozszerzenie tego rozumowania. DenseNet proponuje całe bloki warstw połączonych ze sobą.
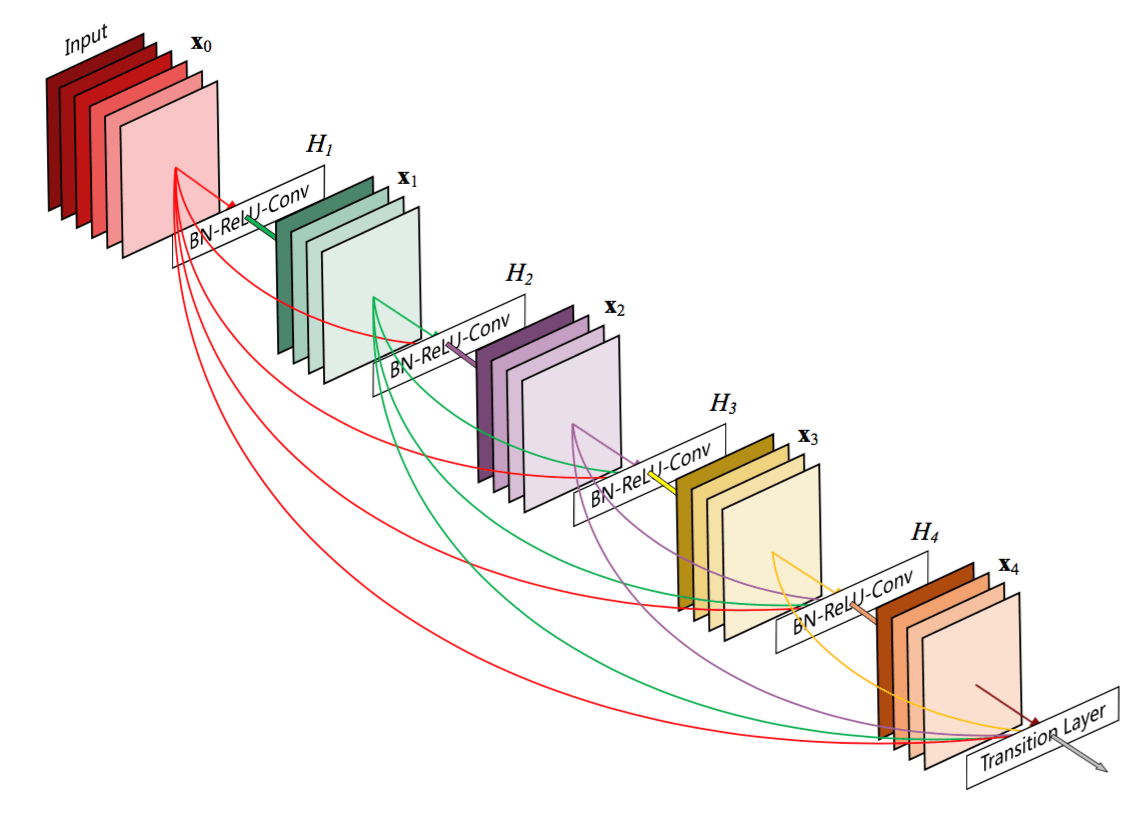
Przyczynia się to do znacznie większej dywersyfikacji funkcji w obrębie tych bloków.
Wniosek
Dominującym trendem światowym jest ciągły postęp w kierunku coraz głębszych architektur sieciowych. Trajektoria ta została uzupełniona przez wprowadzenie ulepszeń obliczeniowych, takich jak rektyfikowane jednostki liniowe (ReLU), eliminacja i normalizacja wsadowa. Strategie te łącznie odegrały kluczową rolę w zwiększeniu ogólnej wydajności tych sieci.
Jednocześnie pojawiły się nowatorskie moduły, które mogą poszczycić się możliwością wydobywania skomplikowanych funkcji na każdym etapie hierarchii sieci. Ta innowacja nie tylko wzbogaciła możliwości reprezentacji modeli, ale także utorowała drogę do bardziej szczegółowych spostrzeżeń.
Dodatkowym zjawiskiem wartym odnotowania jest rosnący nacisk na wzajemne połączenia pomiędzy różnymi warstwami sieci. Połączenia te pełnią podwójną rolę: po pierwsze ułatwiają generowanie różnorodnych cech; po drugie, odgrywają kluczową rolę w płynnej propagacji gradientów w architekturze sieci, co jest kluczowym czynnikiem skutecznego szkolenia.
Zasadniczo globalną trajektorię głębokiego uczenia się charakteryzują bliźniacze silniki zapewniające głębię architektoniczną i udoskonalenie obliczeniowe, w połączeniu z nowatorskimi mechanizmami ekstrakcji cech i skomplikowanymi połączeniami warstw. To wieloaspektowe podejście doprowadziło do znacznego postępu w tej dziedzinie, wynosząc ją na nowy poziom wydajności i zrozumienia.
W prostym angielskim
Dziękujemy, że jesteś częścią naszej społeczności! Zanim odejdziesz:
- Pamiętaj, aby klaskać i podążać pisarza! 👏
- Jeszcze więcej treści znajdziesz na PlainEnglish.io 🚀
- Zapisz się na nasz bezpłatny cotygodniowy biuletyn. 🗞️
- Śledź nas na Twitterze, LinkedIn, YouTube > i Discord.